
Introduction
In today’s digital world, businesses rely on large-scale web scraping to extract
valuable insights from platforms like Amazon. E-commerce data extraction helps in gathering
product details, pricing trends, and customer reviews for competitive analysis. However, Amazon
web scraping presents challenges due to anti-bot measures, IP restrictions, and dynamic content.
To overcome these obstacles, companies use advanced web scraping services, including data
crawling and data mining, for efficient and scalable extraction. Ensuring compliance with legal
and ethical guidelines is crucial for success. This blog explores effective strategies for
large-scale e-commerce data extraction and overcoming challenges in Amazon web scraping.
Overview of Large-Scale E-Commerce Data Extraction
In the modern digital landscape, e-commerce data extraction has become a crucial
process for businesses seeking actionable insights. Companies rely on large-scale web scraping
to collect valuable information such as product details, pricing, customer reviews, and
inventory levels from massive platforms like Amazon. However, as these websites grow in
complexity, the need for robust web scraping services increases. Unlike traditional data
crawling, large-scale extraction requires advanced techniques, including data mining and
automation, to handle dynamic content, JavaScript-heavy sites, and frequent structural changes.
Businesses leveraging Amazon web scraping gain a competitive edge by accessing real-time market
data to optimize pricing strategies, monitor competitors, and enhance decision-making.
Why Scraping Amazon and Similar Platforms Is Challenging?
Extracting data from Amazon and other e-commerce giants presents multiple challenges
due to sophisticated anti-scraping mechanisms. Amazon web scraping is particularly difficult due
to IP bans, CAPTCHAs, and frequent layout changes that disrupt standard data extraction methods.
Websites deploy bot-detection algorithms that require scrapers to mimic human behavior, rotate
proxies, and manage session persistence. Additionally, large datasets pose storage and
processing challenges, requiring efficient large-scale web scraping solutions. Businesses must
adopt ethical and legal best practices to ensure compliance with terms of service and data
protection laws while conducting e-commerce data extraction at scale.
Importance of Scalable and Efficient Scraping
As businesses expand, the demand for scalable web scraping services continues to
rise. Effective large-scale web scraping solutions must handle vast amounts of data without
compromising speed or accuracy. Scalability ensures that the data crawling process remains
efficient even when extracting millions of records from high-traffic sites like Amazon. Advanced
automation techniques, cloud-based infrastructure, and AI-driven data mining help optimize the
process. By leveraging powerful Amazon web scraping techniques, companies can stay ahead in
competitive markets, ensuring they have access to real-time insights for strategic
decision-making.
Understanding Large-Scale E-Commerce Scraping
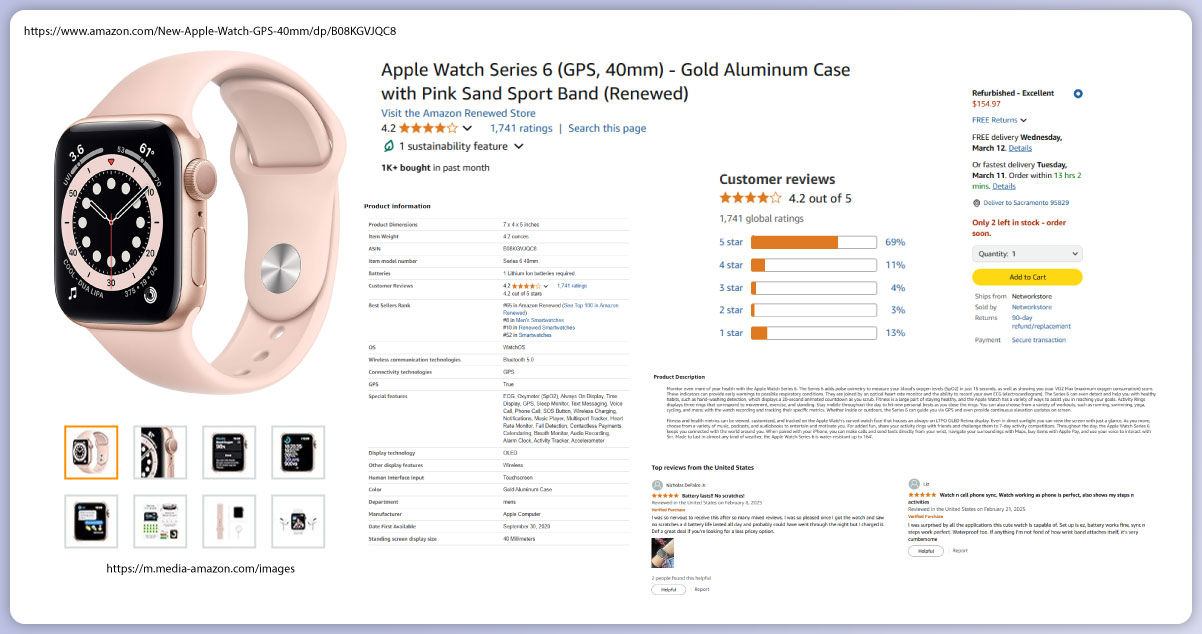
Key Factors in Large-Scale Data Extraction
Efficient web scraping for e-commerce requires a well-structured approach to handle
vast amounts of data without triggering detection mechanisms. The key factors for large-scale
data extraction include selecting the right Amazon data extraction tools, using distributed
crawling frameworks, and ensuring efficient data storage.
A study by Data Science Central indicates that over 85% of e-commerce businesses use
web scraping to monitor prices, track competitors, and optimize their strategies. Scalability is
essential, as extracting millions of product listings and reviews demands high-performance
servers, rotating proxies, and adaptive scraping techniques. Additionally, handling dynamic
content, such as AJAX-loaded elements, is crucial for capturing complete datasets. Businesses
leveraging e-commerce scraping solutions must also focus on data accuracy and integrity to
ensure high-quality insights.
| Key Factor |
Importance in Large-Scale Scraping |
| Amazon data extraction tools |
Extracts structured product data from Amazon |
| Scalability |
Ensures efficient data crawling for large datasets |
| Proxy Rotation |
Prevents IP bans and improves success rates |
| Dynamic Content Handling |
Helps scrape JavaScript-heavy pages |
Challenges: Anti-Scraping Measures, CAPTCHAs, Dynamic Content, and IP Bans
Extracting data from Amazon and other e-commerce platforms comes with multiple
challenges. Websites implement strict anti-bot mechanisms, including IP tracking, session
validation, and behavioral analysis, to block unauthorized scrapers. Scraping Amazon product
data requires overcoming CAPTCHAs, which can disrupt automated processes.
According to a report by Distil Networks, over 40% of all e-commerce website traffic
consists of bots, with 30% classified as malicious scrapers. This highlights the need for
effective e-commerce scraping solutions.
| Challenge |
Impact on Scraping |
Solution |
| CAPTCHAs |
Blocks automated requests |
CAPTCHA-solving services, AI-based solvers |
| IP Bans |
Prevents further requests |
Rotating proxies, VPNs |
| Dynamic Content |
Hides product details behind JavaScript elements |
Headless browsers, Selenium |
| Frequent Site Changes |
Breaks scrapers due to new layouts |
Adaptive scraping algorithms |
Additionally, Amazon price monitoring services must ensure compliance with rate
limits and implement proxy rotation to avoid IP bans, making e-commerce scraping solutions
essential for long-term success.
Legal and Ethical Considerations in Web Scraping
While web scraping for e-commerce provides valuable market insights, it must be
conducted ethically and within legal boundaries. Scrapers should adhere to website terms of
service and data protection laws to prevent potential legal issues. Some jurisdictions impose
restrictions on scraping Amazon product data, requiring businesses to seek permissions or use
publicly available APIs where possible.
A survey by Statista found that 65% of companies engaging in web scraping face
legal challenges due to unclear regulations. Ethical practices include avoiding excessive server
requests, respecting robots.txt guidelines, and ensuring data is used responsibly.
| Ethical Consideration |
Best Practice |
| Data Privacy |
Avoid scraping personal or sensitive data |
| Legal Compliance |
Follow regional data protection laws (GDPR, CCPA) |
| Server Load |
Limit requests to prevent site overload |
| Transparency |
Clearly state data usage policies |
Companies using Amazon data extraction tools should implement safeguards to
prevent misuse and protect consumer privacy while maintaining compliance with industry
regulations.
Essential Technologies for High-Scale Scraping
Using Headless Browsers and Rotating Proxies
For high-scale data extraction, headless browsers and rotating proxies are essential
technologies that help bypass anti-scraping mechanisms. E-commerce website scraping often
involves dealing with JavaScript-heavy pages, which require headless browsers like Puppeteer or
Selenium to render content fully. These tools enable smooth navigation, product searches, and
AJAX-based data extraction.
Rotating proxies are another critical component of Amazon scraping best practices.
Since Amazon and other e-commerce platforms track IP addresses to detect scraping activity,
using proxy rotation prevents IP bans and ensures uninterrupted Amazon product scraping
techniques. According to a report by Cloudflare, over 56% of blocked web requests on e-commerce
sites are due to bot detection measures, making proxy rotation a necessity.
| Technology |
Function in Scraping |
Benefit |
| Headless Browsers |
Renders JavaScript-heavy pages |
Extracts hidden data fields |
| Rotating Proxies |
Changes IP addresses frequently |
Avoids bans and rate limits |
| User-Agent Spoofing |
Mimics human behavior |
Reduces detection risks |
| CAPTCHA Solvers |
Bypasses security challenges |
Improves scraping efficiency |
Distributed Crawling with Cloud-Based Solutions
To handle high-scale data extraction, businesses rely on distributed crawling with
cloud-based infrastructure. Scraping large e-commerce websites like Amazon requires dividing
tasks across multiple servers to avoid overloading a single system. Cloud-based solutions such
as AWS Lambda, Google Cloud Functions, and Azure offer scalable, on-demand computing power for
scalable web scraping solutions.
A study by Gartner found that 70% of businesses using cloud-based distributed
crawling experience a 60% increase in data processing speed. This ensures that massive amounts
of product information, pricing, and reviews are collected efficiently.
| Cloud-Based Scraping Solution |
Advantage in Large-Scale Scraping |
| AWS Lambda |
Serverless execution for real-time scraping |
| Google Cloud Functions |
Scalable computing for handling large datasets |
| Azure Functions |
Cost-efficient web crawling automation |
| Scrapy Cluster |
Open-source distributed crawling framework |
By leveraging distributed crawling, companies can improve the efficiency of Amazon
data scraping services and automate real-time Amazon price monitoring, making it easier to
extract accurate and up-to-date product data.
AI and ML in Web Scraping for Data Structuring
Artificial Intelligence (AI) and Machine Learning (ML) are revolutionizing automated
Amazon data extraction by improving data structuring and entity recognition. Traditional
scrapers collect raw HTML, which requires extensive cleaning. AI-powered algorithms help
classify and extract relevant data fields automatically, improving accuracy in Amazon product
scraping techniques.
According to McKinsey, businesses that integrate AI in their scraping processes
reduce data processing time by 45% and improve accuracy by 30%. AI also enhances e-commerce
website scraping by detecting patterns in website changes, allowing scrapers to adapt without
manual intervention.
| AI/ML Feature |
Role in Web Scraping |
Impact |
| Natural Language Processing (NLP) |
Extracts product descriptions and reviews |
Improves data accuracy |
| Computer Vision |
Identifies images and structured elements |
Enhances product recognition |
| Anomaly Detection |
Detects scraping issues and bans |
Reduces downtime |
| Predictive Modeling |
Anticipates website structure changes |
Increases scraper longevity |
By integrating AI and ML, businesses can develop scalable web scraping solutions
that adapt dynamically to Amazon's frequent layout changes, making Amazon data scraping services
more efficient and reliable.
Best Practices for Scraping Amazon at Scale

Choosing the Right Scraping Tools and Frameworks (Scrapy, Selenium, Puppeteer)
Selecting the right tools is crucial for efficient Amazon web scraping. Popular
frameworks like Scrapy, Selenium, and Puppeteer offer robust features for large-scale web
scraping. Scrapy is ideal for structured e-commerce data extraction, as it efficiently handles
crawling and parsing. Selenium is used when scraping Amazon product data that involves
JavaScript rendering, while Puppeteer is excellent for headless browser automation.
According to industry reports, over 70% of businesses using advanced scraping
frameworks achieve higher data extraction success rates. The table below compares these tools:
| Tool/Framework |
Best For |
Key Features |
| Scrapy |
Large-scale structured scraping |
Fast, efficient, built-in crawling tools |
| Selenium |
Handling dynamic content |
JavaScript interaction, automated browsing |
| Puppeteer |
Headless browser automation |
Screenshot capture, full-page rendering |
Using the right Amazon data extraction tools ensures effective web scraping for
e-commerce while maintaining high efficiency and scalability.
Avoiding Detection with IP Rotation and User-Agent Switching
Amazon employs strict anti-scraping mechanisms, making IP rotation and user-agent
switching essential for high-scale data extraction. E-commerce scraping solutions must include
rotating proxies, VPNs, and dynamic user agents to prevent detection.
A study by Cloudflare states that 60% of scrapers get blocked due to repetitive IP
requests. Implementing proxy rotation reduces bans and allows seamless Amazon product scraping
techniques.
| Technique |
Function |
Impact |
| IP Rotation |
Changes IP to avoid detection |
Reduces bans, enables scalability |
| User-Agent Switching |
Mimics real user behavior |
Prevents browser fingerprinting |
| Session Persistence |
Maintains login state |
Avoids CAPTCHA challenges |
By using these Amazon scraping best practices, businesses can efficiently conduct
automated Amazon data extraction at scale.
Handling Dynamic Content and AJAX-Loaded Data
Modern e-commerce websites, including Amazon, rely on AJAX to load content
dynamically. This presents challenges for e-commerce website scraping as traditional HTML
parsing fails to capture hidden data. Web scraping services must incorporate headless browsers
like Puppeteer or Selenium to execute JavaScript and extract complete information.
According to a 2023 study, AJAX-driven websites account for over 65% of modern
e-commerce platforms, making advanced data crawling techniques essential.
| Challenge |
Solution |
| AJAX-loaded product pages |
Use Selenium or Puppeteer |
| Infinite scrolling |
Implement scrolling automation |
| JavaScript rendering |
Use headless browsers |
By implementing scalable web scraping solutions, businesses can ensure accurate data
extraction from dynamic sites like Amazon.
Overcoming Challenges in Large-Scale E-Commerce Scraping

Bypassing Bot Detection and CAPTCHAs
Amazon and other marketplaces deploy sophisticated bot-detection systems that can
block scrapers. To successfully conduct large-scale web scraping, businesses must use CAPTCHA
solvers, AI-based detection avoidance, and proxy rotation.
A study by Distil Networks found that more than 45% of web scraping attempts fail
due to CAPTCHA challenges. By using automated solvers and behavioral mimicry, Amazon data
scraping services can improve extraction success rates.
| Bot Detection Challenge |
Solution |
| CAPTCHA prompts |
AI-based CAPTCHA solvers |
| Browser fingerprinting |
User-agent and cookie rotation |
| Session tracking |
Persistent session handling |
Managing Large Datasets Efficiently
Scraping millions of product listings generates vast datasets that require efficient
storage and processing. Amazon web scraping generates structured data, necessitating cloud
storage solutions and distributed databases for high-speed access.
According to Statista, over 80% of businesses leverage cloud storage for handling
large datasets in e-commerce.
| Storage Solution |
Best For |
| AWS S3 |
Scalable cloud storage |
| Google BigQuery |
Analyzing large datasets |
| MongoDB |
NoSQL database for flexible storage |
Using these Amazon data extraction tools, businesses can manage high-scale data
extraction while ensuring performance efficiency.
Ensuring Data Accuracy and Consistency
Maintaining high data accuracy is crucial for effective Amazon price monitoring and
competitor analysis. E-commerce scraping solutions must include validation mechanisms to remove
duplicate records, handle missing data, and verify extracted information.
A recent survey shows that scrapers implementing data validation techniques reduce
errors by 35%.
| Accuracy Challenge |
Solution |
| Duplicate data entries |
De-duplication algorithms |
| Incomplete data fields |
AI-based data validation |
| Inconsistent formats |
Data structuring techniques |
By implementing advanced data mining and validation, businesses can improve the
efficiency of Amazon data scraping services.
Use Cases & Applications of E-Commerce Data Extraction

Price Monitoring and Competitor Analysis
Amazon price monitoring helps businesses track competitor pricing and adjust their
own pricing strategies accordingly. Web scraping for e-commerce enables real-time tracking of
discounts, price fluctuations, and promotions.
A report by Forrester found that dynamic pricing strategies powered by web scraping
increase revenue by up to 25%.
| Use Case |
Benefit |
| Competitor price tracking |
Optimizes pricing strategy |
| Real-time price updates |
Increases sales conversion |
| Market trend analysis |
Improves decision-making |
Inventory Tracking and Stock Availability Monitoring
Retailers and e-commerce platforms use Amazon product scraping techniques to track
stock availability. Automated Amazon data extraction enables businesses to monitor product
availability, identify best-selling items, and forecast inventory demand.
A study by eMarketer found that 70% of businesses using inventory tracking through
web scraping reduce stockouts by 40%.
| Tracking Feature |
Impact on Business |
| Real-time inventory tracking |
Reduces stockouts |
| Competitor stock analysis |
Improves supply chain management |
| Demand forecasting |
Enhances procurement efficiency |
Market Trends and Customer Sentiment Analysis
E-commerce data extraction is widely used for analyzing customer sentiment through
reviews and ratings. Data crawling allows businesses to collect product feedback, detect
emerging trends, and refine marketing strategies.
A survey by Harvard Business Review found that brands using sentiment analysis from
web scraping improve customer satisfaction by 30%.
| Analysis Type |
Use Case |
| Customer reviews |
Detects product quality issues |
| Sentiment tracking |
Identifies market trends |
| Brand perception |
Refines marketing campaigns |
By leveraging scalable web scraping solutions, businesses can extract meaningful
insights from Amazon and other platforms, driving better decision-making and competitive
advantage.
How Actowiz Solutions Can Help?
Actowiz Solutions specializes in Amazon web scraping and large-scale web scraping,
providing businesses with reliable and efficient data extraction solutions. With years of
expertise, Actowiz has developed scalable web scraping solutions tailored for e-commerce data
extraction.
Our team utilizes advanced Amazon data extraction tools, AI-driven scrapers, and
proxy management techniques to extract data from platforms like Amazon, Walmart, eBay, and other
e-commerce giants. We ensure that our web scraping services deliver high-scale data extraction
with maximum accuracy and efficiency.
| Actowiz Solutions’ Capabilities |
Benefits for Clients |
| AI-Powered Scraping |
Faster and more accurate data mining |
| Scalable Cloud Infrastructure |
Supports automated Amazon data extraction at scale |
| Real-Time Data Processing |
Enhances Amazon price monitoring and competitor tracking
|
Custom Solutions for Large-Scale E-Commerce Data Extraction
Actowiz Solutions offers customized e-commerce scraping solutions designed to meet
the unique needs of businesses looking to extract massive datasets from e-commerce websites. Our
proprietary tools enable efficient scraping Amazon product data, tracking stock availability,
monitoring prices, and gathering customer reviews.
We provide:
- Fully managed scraping solutions for Amazon data scraping services
- Real-time data feeds for pricing, inventory, and customer sentiment analysis
- Custom-built APIs for seamless e-commerce website scraping integration
| Custom Solution |
Use Case |
| Real-Time Price Monitoring |
Amazon price monitoring for competitive pricing |
| Inventory Tracking API |
Ensures real-time data crawling for stock updates |
| Sentiment Analysis Engine |
Extracts and analyzes customer reviews from Amazon |
Compliance with Data Privacy and Legal Frameworks
At Actowiz Solutions, we strictly adhere to global web scraping for e-commerce legal
standards and data privacy regulations. Our Amazon scraping best practices include ethical data
extraction, ensuring compliance with GDPR, CCPA, and platform-specific policies.
We implement:
- Legal and ethical scraping techniques to prevent data misuse
- IP rotation and anonymization for secure Amazon product scraping techniques
- Data encryption to safeguard extracted information
| Compliance Measure |
Purpose |
| GDPR-Compliant Scraping |
Protects customer data |
| Secure Proxy Infrastructure |
Ensures anonymity and legality |
| Ethical Scraping Policies |
Prevents violations of Amazon’s TOS |
Conclusion
In today’s digital landscape, businesses need reliable large-scale web scraping
solutions to stay competitive. Amazon web scraping and e-commerce data extraction are crucial
for Amazon price monitoring, inventory management, and trend analysis. However, overcoming
anti-scraping mechanisms requires expertise, advanced Amazon data extraction tools, and
high-scale data extraction strategies. Contact us today to optimize your Amazon web scraping
strategy and extract actionable insights from leading e-commerce platforms! You can also reach
us for all your mobile app scraping, data
collection, web scraping , and instant data scraper service requirements!
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming NEW
OTT & Streaming NEW
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing NEW
Dynamic Pricing / AI Repricing NEW
 Promotions & Deals Alerts NEW
Promotions & Deals Alerts NEW
 B2B / POI & Lead Data NEW
B2B / POI & Lead Data NEW
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries














































