Twitter is a prominent social media platform with valuable data and the potential for diverse applications. Yet, extracting data from Twitter via web scraping poses challenges due to its anti-scraping mechanisms. This comprehensive guide will delve into the process of extracting Twitter data using Python and Actowiz Solutions' multi-accounting browser. This strategic approach allows for circumventing Twitter's anti-scraping safeguards.
Deciphering Twitter's Measures Against Scraping
Twitter's efforts to thwart scraping are vital for upholding the platform's integrity and preserving user privacy. These protective measures aim to curtail automated software, commonly called "bots," from indiscriminately harvesting substantial amounts of data from Twitter profiles without user consent.
Embedded within its anti-scraping strategy, Twitter employs a range of countermeasures. These encompass enforcing rate limits on API requests, detecting and preventing suspicious activities, and utilizing CAPTCHAs to verify users' identities. While individuals curious about web scraping Twitter for data accumulation might perceive these safeguards as disruptive, they play a pivotal role in ensuring the safety and security of the platform.
Introducing Actowiz Solutions: Your Solution to Web Scraping Challenges
Have you ever encountered obstacles to extracting data from a website due to anti-scraping defenses? The frustration of being thwarted in your data acquisition efforts can be significant. Enter Actowiz Solutions' privacy browser, offering a remedy in such scenarios.
By creating distinctive browser fingerprints, this application effectively shields your web scraper from website detection. With this potent tool, you can effortlessly gather the required data, triumphing over anti-scraping obstacles. This article delves deep into Actowiz Solutions' functionalities, explores its application in web scraping Twitter, and elucidates how it can resolve web scraping challenges.
Installing and Configuring Actowiz Solutions: Step-by-Step Guide
Follow these outlined steps to successfully install and set up Actowiz Solutions for seamless web automation:
Download Actowiz Solutions Software: Visit the official Actowiz Solutions website and initiate the download of the software tailored for your operating system. Proceed to install the application once the download is complete.
Create a New Account: Launch Actowiz Solutions and embark on account creation by selecting the "Sign Up" option. You can use your Google credentials or manually input your details and click "Create Account."
Profile Creation: Access the main dashboard and create a new profile by clicking "Create Profile." Profiles encompass a collection of browser configurations for distinct tasks. Alternatively, use the "+" icon in the top left for a swift profile setup with automatic settings.
Profile Settings: Populate the settings for the new profile, including OS, browser type, proxy, screen size, and location. Consider adhering to Actowiz Solutions' suggested settings, as altering parameters arbitrarily could impact performance. Extensions and plugins can also be added as desired.
Proxy Configuration: If interfacing with other applications demands a proxy connection, navigate to the "Proxy" tab and meticulously configure your proxy settings as prompted.
Using Actowiz Solutions with Other Applications: Once proxy settings are established, you can engage Actowiz Solutions in conjunction with other applications by inputting the proxy address and port number.
Executing Your Profile: With the setup in place, initiate your profile to execute tasks such as web scraping, social media management, and automation. New browser windows will open, mimicking regular browser operation.
There you have it! You can now effectively employ Actowiz Solutions for your web automation endeavors.
Python Environment Setup Simplified
The process of configuring a Python environment can be streamlined into several straightforward steps:
1. Python Installation
Download and install Python onto your device from the official Python website. Ensure that you opt for the appropriate Python version tailored to your operating system.
2. Code Editor Installation
Integrate a suitable code editor like Visual Studio Code, PyCharm, or Sublime Text into your workflow. These tools facilitate the creation of Python programs.
3. Package and Library Installation
Install the requisite packages and libraries essential for your project. To accomplish this, execute the command "pip install " in the command prompt.
4. Virtual Environment Setup
While coding in Python sans a virtual environment is feasible, it's advisable to establish a virtual environment. This practice guarantees that each project maintains its distinct dependencies and packages, effectively preventing conflicts among various projects.
By adhering to these steps, you'll be equipped with a streamlined and organized Python environment for your coding ventures.
Twitter API Authentication with Actowiz Solutions: A Guided Approach
To initiate authentication with Twitter's API using Actowiz Solutions Browser, adhere to the ensuing steps:
1. Account Creation and Plan Selection
If you're not already an Actowiz Solutions user, commence by creating an account. Opt for a free 7-day trial of a paid plan or explore the forever-free version, granting access to three profiles.
2. Browser Profile Establishment
Launch the browser and craft a new browser profile. This enables the emulation of diverse devices and browsers each time you interact with Twitter's API, effectively evading detection.
3. Twitter Developer Account Setup
Visit https://developer.twitter.com/en/apps and log into your Twitter account.
4. App Creation
Click the "Create an app" button and complete the essential details, including the app name, description, and website. Ensure precise selection of app permissions in line with your use case.
5. Keys and Tokens Generation
Upon app creation, access the "Keys and Tokens" tab. Beneath "Consumer Keys," hit the "Generate" button to procure your API key and API secret key. Safeguard these by recording them in a secure text document or employing a reliable password manager.
6. Access Token & Secret Generation
Similarly, under "Access Token & Secret," generate your access token and access token secret. Store these securely alongside the API keys.
7. Python Script Integration
Incorporate the API keys and access tokens from your secure document or password manager into your Python script, along with the tweepy library. Tweepy will adeptly manage API requests and the authentication process. Meanwhile, Actowiz Solutions will provide the advantage of browser diversification, mitigating detection risks.
By following these steps, you will efficiently authenticate with Twitter's API while leveraging the capabilities of Actowiz Solutions Browser for enhanced detection avoidance.
Illustrative Usage of Tweepy in Python with Actowiz Solutions Browser:
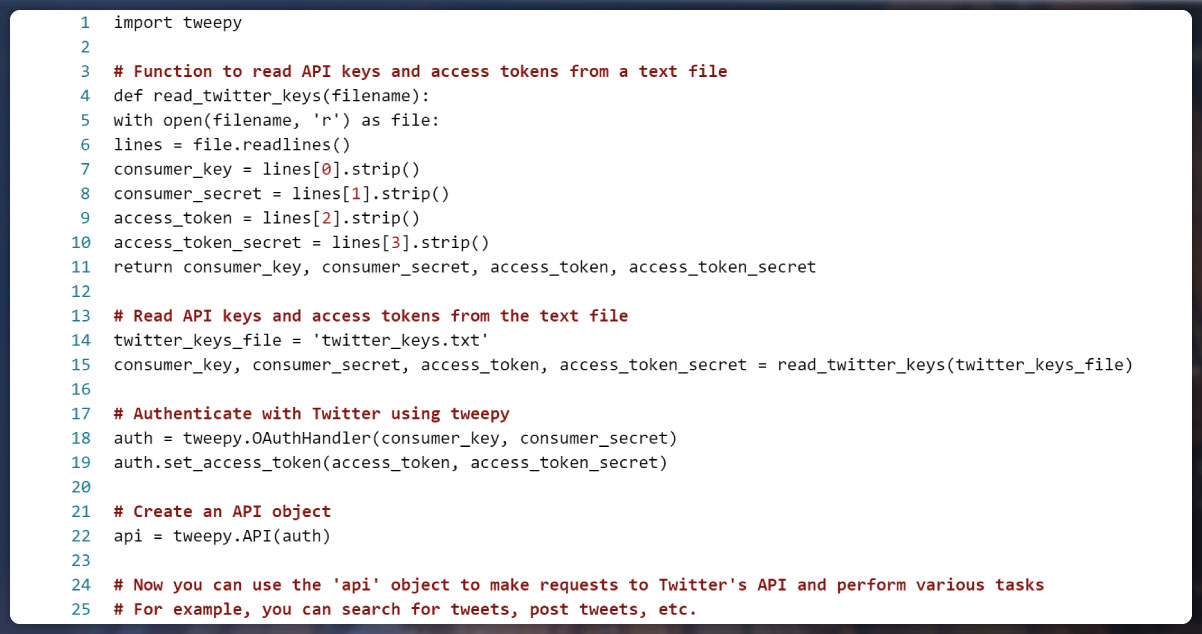
Extracting Twitter Data using Python and Actowiz Solutions
In this process, Selenium package of Python's and Actowiz Solutions' secure browser collaborate to automating log into the Twitter account, initiating searches for specific topics, and extracting relevant data points from tweets. The data extraction encompasses user tags, timestamps, textual content, response counts, retweets, and favorites.
The XPATH method is employed to identify filter buttons, search box, and tweet articles on the Twitter platform to execute this. Additionally, the path to the chrome driver executable must be designated. After data extraction, there's the option to export the gathered data to a file or store it within lists for future analysis.
Unlock insights into user sentiment, trending subjects, and broader social media usage with our specialized Social Media App Scraping services. Efficiently extract relevant data from social platforms, empowering informed decision-making with valuable insights on user behaviors, preferences, and trends. Trust in our expertise to enhance your strategic analysis and planning. However, it is imperative to uphold compliance with Twitter's terms of service and refrain from using this technique to breach user privacy or engage in unethical practices. It is recommended to opt for publicly accessible Twitter data sources exclusively.
Import required libraries

The following code snippet imports essential modules from the Selenium web automation library and the time module. It establishes the foundational framework for managing a web browser using Selenium. The specific imports include the Selenium library, the webdriver module for browser control, the By class for HTML element location specification, and the Keys class for transmitting special keystrokes to the browser.
Additionally, the sleep function from the time module is integrated. Collectively, this code readies the fundamental components required to orchestrate automated web browsing activities using Selenium within the Python programming context.
Creating Webdriver and Logging into Twitter
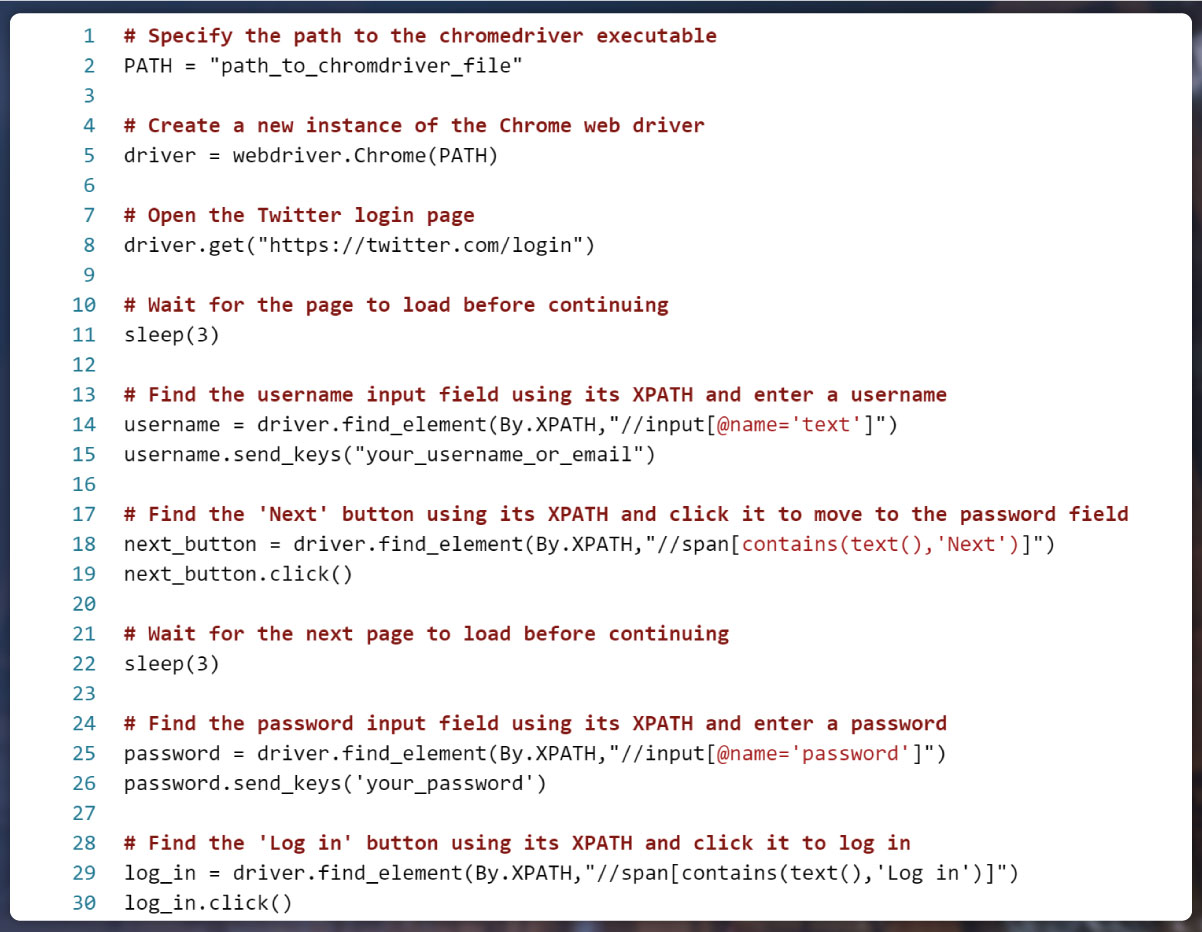
The provided code employs Selenium to automate the Twitter login procedure using a Chrome web driver. A concise breakdown of its functionality is as follows:
- Imports Relevant Modules: The script imports essential modules from the Selenium and time libraries.
- Chromedriver Path Specification: The chromedriver executable's path is defined.
- Chrome Web Driver Initialization: An instance of the Chrome web driver is created.
- Navigating to Twitter Login Page: The browser navigates to Twitter's login page.
- Page Load Waiting: The script waits for the page to fully load.
- Username Input: The username input field is located through its XPATH, and a username is entered.
- 'Next' Button Click: The 'Next' button, identified by its XPATH, is clicked to proceed to the password field.
- Page Load Waiting: Another waiting period ensures the next page fully loads.
- Password Input: The password input field is located through its XPATH, and a password is entered.
- 'Log in' Button Click: The 'Log in' button, identified by its XPATH, is clicked to initiate the login process.
In essence, this code streamlines the task of logging into Twitter through automated actions orchestrated by Selenium and a Chrome web driver.
Searching for the User
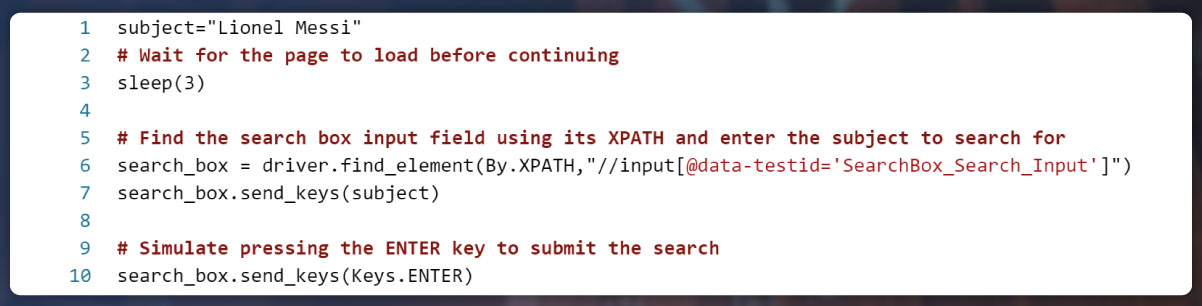
Summarizing the Code's Functionality:
- Page Load Waits: A 3-second wait ensues for the page to load fully.
- Subject Search: The code locates the search box input field using its XPATH and fills in the subject to be searched. This subject is defined by the variable named 'subject.'
- Enter Key Simulation: The code emulates the pressing of the ENTER key, initiating the search operation.
In essence, this code streamlines the procedure of conducting a subject-based search on Twitter by utilizing Selenium and a Chrome web driver.
Going to the People’s Tab

Continuing from the previous code, this script employs Selenium to further automate the process of filtering Twitter search results to display only individuals. A succinct overview of its operation includes:
- Page Load Wait: The script pauses for 3 seconds to allow the page to load completely.
- 'People' Filter Button: The code locates the 'People' filter button utilizing its XPATH.
- Click Action: The 'People' filter button is clicked, thereby activating the filtration of search results to exclusively showcase individuals.
In essence, this code augments the automation process by facilitating the filtering of Twitter search outcomes to solely present individuals, all executed through the collaborative effort of Selenium and a Chrome web driver.
Click on a User’s Profile
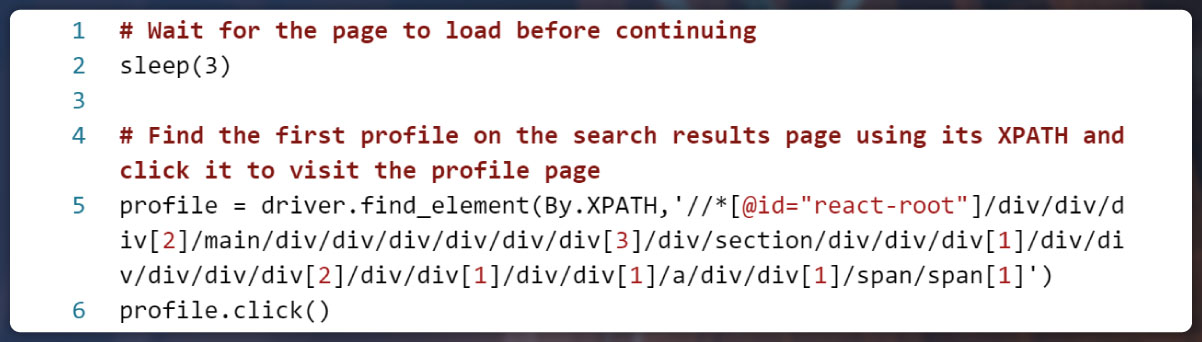
Continuing the prior code, this script leverages Selenium to further automate the procedure of navigating to the profile page of the initial search outcome on Twitter. A succinct overview of its functioning encompasses:
- Page Load Wait: The script introduces a 3-second pause to accommodate the complete page loading.
- First Profile Selection: The code identifies the first profile listed on the search results page through its XPATH.
- Profile Page Visit: An action is performed to click on the first profile, facilitating the redirection to its profile page.
In essence, this code extends the automation sequence by enabling the seamless navigation to the profile page of the primary search result on Twitter. This entire process is orchestrated by the collaborative influence of Selenium and a Chrome web driver.
Scraping a User’s Tweets

Incorporating Selenium, this code engages in data scraping from the previously visited Twitter search result page. A concise overview of its functionality encompasses:
- Empty Lists Initialization: Commencing with the creation of empty lists, designated to accommodate the scraped data.
- Tweet Article Identification: The code employs XPATH to locate all tweet articles present on the page.
- Information Extraction Loop: An iterative process ensues, where each article undergoes examination. Relevant information including user tag, timestamp, tweet content, reply count, retweet count, and like count is extracted.
- Data Accumulation: Extracted data is subsequently appended to their respective lists for storage.
In essence, this code amalgamates Selenium and a Chrome web driver to automate the process of extracting data from a Twitter search result page. This data is then organized within lists, primed for further analytical endeavors.
Results


Leveraging Actowiz Solutions for Web Scraping
Once your proxy settings and browser profile are configured, you're ready to initiate web scraping activities. A scripting language like Python is indispensable for crafting a web scraping script. This script, utilizing the browser profile furnished by Actowiz Solutions, should interface with the target website and extract pertinent information.
Commencing the process entails importing requisite libraries, including sys, selenium, chrome options, time, and Actowiz Solutions. To achieve this, the following lines of code have been introduced at the beginning of the file:

Setting Up Actowiz Solutions and Selenium WebDriver
As part of the enhancement process, the installation of Selenium WebDriver and Actowiz Solutions takes precedence. This entails appending the subsequent lines of code to the file's outset:
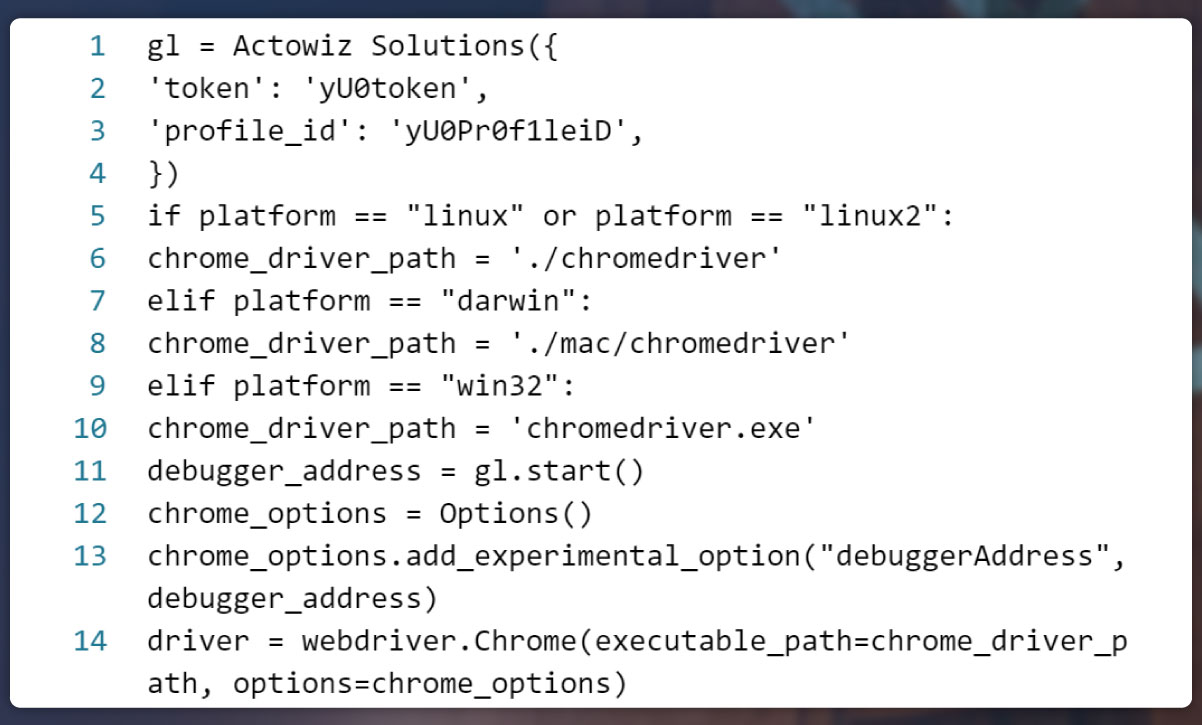
Configuring Actowiz Solutions and Integrating WebDriver
This code segment orchestrates the configuration of Actowiz Solutions in conjunction with the requisite platform-specific WebDriver path, token, and profile id. Subsequently, Actowiz Solutions is initiated, and WebDriver is aligned with the pertinent debugger URL for seamless integration.
Transition to WebDriver Utilization
In the most recent iteration, the code underwent an update that pivots towards WebDriver for navigation and scraping. This transformation entails the following modifications:
Code modification to employ driver.page_source for scraping purposes, replacing the previous usage of response.content.
Code adaptation to utilize driver.object in lieu of the 'requests' library for navigation functionalities.
By incorporating these changes, the code attains an enhanced level of integration and effectiveness in leveraging WebDriver for navigation and data retrieval.
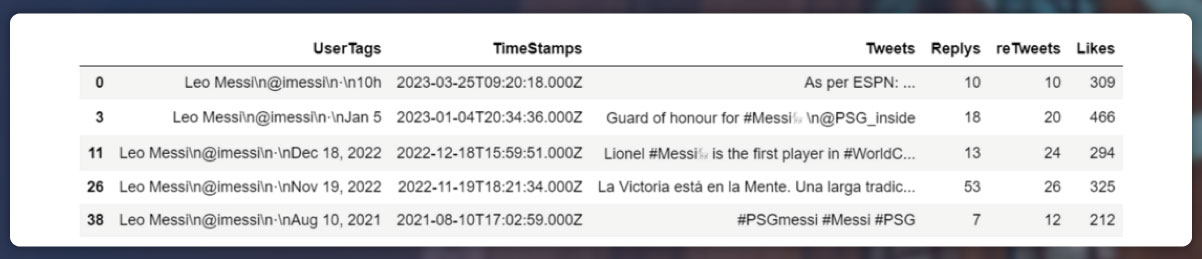
Making dataframe from a list
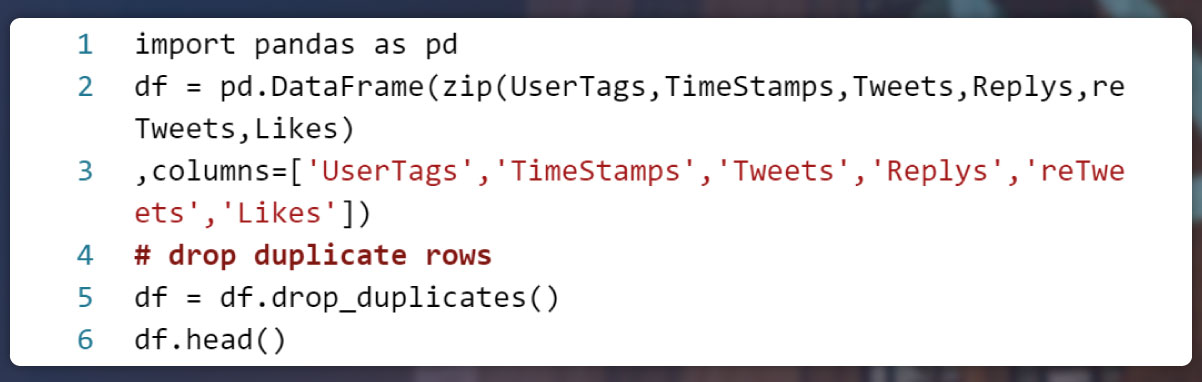
Results
Advanced Techniques for Twitter Scraping with Actowiz Solutions and Python
Unlocking more intricate dimensions of Twitter scraping involves harnessing Actowiz Solutions and Python in tandem. Here's an array of advanced techniques that can elevate your Twitter scraping endeavors:
Proxy Utilization: Implementing proxies introduces an additional layer of complexity for Twitter to discern your scraping operations. Actowiz Solutions streamlines proxy integration, facilitating seamless adoption in your web scraping endeavors.
User-Agent Rotation: Combat Twitter's detection mechanisms by cycling through various User-Agent headers. This tactic obfuscates your scraper's identity, making it harder to flag as a bot. Actowiz Solutions conveniently facilitates the setup of User Agent rotation.
Leveraging Headless Browsers: Employing headless browsers like Chrome or Firefox empowers data extraction without initiating a visible browser window. This improves efficiency and minimizes detection risks. Actowiz Solutions synergizes with headless browsing across popular browsers.
Precision with XPaths: Employing XPaths allows you to precisely target specific page elements, such as tweets or user profiles. This precision extraction technique enables the isolation of relevant data, circumventing unnecessary scraping of irrelevant content.
Selenium for Automated Interaction: Selenium proves invaluable for automating web page interactions. With Actowiz Solutions, you seamlessly merge the prowess of Selenium for tasks like Twitter login or page navigation.
Real-Time Monitoring via Streaming APIs: Twitter's streaming API furnishes real-time tweet monitoring. This avenue is ideal for brand mention tracking, keyword monitoring, or hashtag analysis.
Cumulatively, these advanced methodologies augment the efficacy and potency of your Twitter scraping initiatives. Actowiz Solutions and Python harmonize to equip you with robust scraping capabilities, allowing you to efficiently harvest Twitter data while minimizing exposure to detection risks.
Best Practices for Successful Twitter Scraping with Multi Accounting Browsers
Engaging in Twitter scraping through multi accounting browsers demands a methodical approach due to the challenges posed by Twitter's active blocking measures against scraping and bot-like activity. Yet, by adhering to the following best practices, you can enhance the prospects of effective scraping using multi accounting browsers:
Emulate Human Behavior: Infuse your scraping bot with human-like traits. This entails replicating mouse movements, typing cadence, and scrolling patterns. Introduce randomized delays between actions and avoid inundating the platform with a flurry of rapid requests.
IP Address Rotation: Prevent detection by Twitter through IP address rotation. Regularly switch IP addresses to sidestep scrutiny. Leveraging a proxy server pool or a rotating residential IP service enables seamless IP rotation between requests.
User Agent Utilization: Guard against detection by deploying a user agent that mirrors popular web browsers like Chrome or Firefox. Periodically alter the user agent string to evade detection.
Leverage Headless Browsers: Employ headless browsers, which operate sans a graphical user interface. This tactic mimics user interaction while minimizing the overhead of graphical rendering.
Focused Scraping: Streamline your scraping efforts by targeting specific pages or segments of relevance. By concentrating on pertinent data, you mitigate both detection risks and data volume.
Moderate Scraping: Avoid triggering alarms by refraining from excessive data retrieval in a condensed timeframe. Disseminate your scraping over time and circumvent intense request surges. Constrain your scraping activities to public data exclusively.
Monitor Vigilantly: Continuously oversee your scraping bot's performance for errors and obstructions. Implement tools such as log files, monitoring services, and alert systems to maintain awareness of your bot's actions and status.
In sum, the realm of web scraping on Twitter with multi accounting browsers necessitates meticulous planning, meticulous attention to detail, and unwavering adherence to best practices. By meticulously incorporating these guidelines, you heighten the probability of accomplishing successful scraping endeavors, all while mitigating the risk of detection and obstruction by Twitter.
Conclusion
Within this comprehensive guide, we have navigated the intricate landscape of web scraping Twitter data, harnessing the synergies of Python and Actowiz Solutions' multi accounting browser. Our intent has been to equip you with an informed foundation for delving into the realm of Twitter data scraping, empowering you to undertake progressively sophisticated web scraping ventures.
As you depart from this guide, armed with newfound knowledge, you are poised to embark on a journey of crafting advanced web scraping projects with Twitter data. By merging the capabilities of Python and Actowiz Solutions, you have at your disposal a potent toolkit to navigate the intricate terrain of web scraping while achieving your data acquisition objectives.
Frequently Asked Questions (FAQs)
Is Web Scraping Allowed on Twitter?
Web scraping on Twitter is not permitted without proper authorization, as outlined in Twitter's Terms of Service. Although web scraping itself is not illegal according to US and EU laws, it's crucial to note that scraping data from Twitter requires adherence to their policies. Publicly available data can be scraped, but causing significant harm to private companies should be avoided.
Does Twitter Prohibit Scraping?
Yes, Twitter explicitly bans scraping activities. Twitter's terms explicitly state that data collection or scraping from their platform without permission is not allowed. Violations can lead to account suspension and even legal action if substantial harm is caused to businesses. Twitter has also implemented temporary reading restrictions to counter excessive data scraping.
Which Tool is Best for Scraping Twitter?
The choice of a scraping tool depends on your specific needs, skills, and budget. Open-source options like BeautifulSoup and Scrapy are popular due to their effectiveness. However, adhering to Twitter's rules is paramount. Using Twitter's official API in conjunction with established scraping tools such as Tweepy, Twint, or Snscrape is a recommended approach.
How to Scrape Twitter Without Using API?
While scraping without Twitter's API is discouraged and goes against their rules, tools like Beautiful Soup and Scrapy in Python can be used for academic or research purposes. It's essential to respect privacy and legal constraints when scraping data from Twitter or any other source.
For mode details, contact Actowiz Solutions now! You can also reach us for all your mobile app scraping, instant data scraper and web scraping service services.
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming NEW
OTT & Streaming NEW
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing NEW
Dynamic Pricing / AI Repricing NEW
 Promotions & Deals Alerts NEW
Promotions & Deals Alerts NEW
 B2B / POI & Lead Data NEW
B2B / POI & Lead Data NEW
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries