Actowiz Metrics Real-time  analytics dashboard for brands! Try Free Demo
analytics dashboard for brands! Try Free Demo
Scalable web, app & AI-powered extraction. 99.9% accuracy.
All Services → Core Scraping Services
Core Scraping Services
 Top Global Platforms
Top Global Platforms
 Platforms by Region
Platforms by Region
🇦🇪 Expanding across UAE, Saudi, Qatar, Kuwait & more
Request Custom Platform →🌏 Singapore, Indonesia, Thailand, Philippines, Vietnam & Malaysia
Request Custom Platform →🌎 Brazil, Mexico, Argentina, Colombia & Chile
Request Custom Platform → Pricing & Promotions
Pricing & Promotions
 Brand & Intelligence
Brand & Intelligence
 Digital Shelf & Search
Digital Shelf & Search
 Assortment
Assortment For Retailers
For RetailersWhich solution fits?
Talk to Expert Marketplace Scrapers
Marketplace Scrapers
 Data APIs
Data APIs Universal APIs
Universal APIs Delivery & SDKs
Delivery & SDKsReady to integrate?
Start Free Trial Knowledge Center
Knowledge Center
 Guides & Playbooks
Guides & Playbooks
 Downloads & Tools
Downloads & Tools
 Trust & Company
Trust & CompanyScalable web, app & AI-powered extraction. 99.9% accuracy.
All Services → Core Scraping Services
Top Global Platforms
Pricing & Promotions
Brand & Intelligence
Digital Shelf & Search
Assortment For RetailersWhich solution fits?
Talk to Expert Marketplace Scrapers
Data APIs Universal APIs Delivery & SDKsReady to integrate?
Start Free Trial Knowledge Center
Guides & Playbooks
Downloads & Tools
Trust & Company
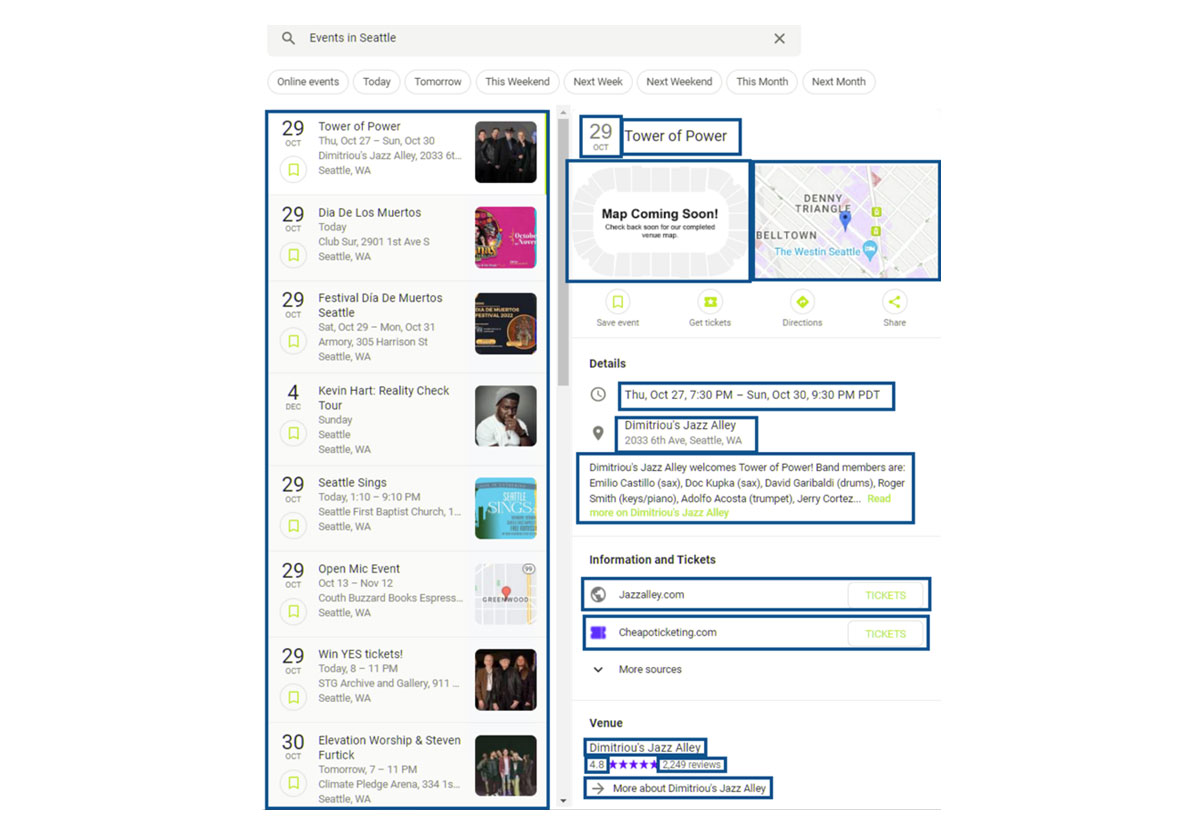
In case, you don’t want any explanation, just look at a complete code example given in online IDE



First, we have to make a Node.js* project as well as add npm packages to parse parts of a HTML markup, as well as axios to make the request for a website.
To make this in a directory with project, open a command line to enter:

And after that:

*In case, you don’t get Node.js installed, it’s easy to download from nodejs.org as well as follow an installation documentation.
Initially, we have to scrape data from an HTML elements. The procedure of having the correct CSS selectors is very easy through SelectorGadget Chrome extension that help us take CSS selectors by clicking on a desired element in a browser. Though, it doesn’t always work perfectly, particularly when a website is weightily utilized by JavaScript.
The Gif given here shows an approach of choosing various parts of results.
State constants from axios and cheerio libraries:

After that, we write about what we need to search with request options: HTTP headers having User-Agent that is used for acting as the "real" user visiting, and the required parameters to make a request:


Note: Default axios request’s user-agent is axios/
After that, we write the function, which makes a request as well as returns the required data from a page. We established the reply from axios request, which has a data key, which we de-structure and parse that using cheerio:

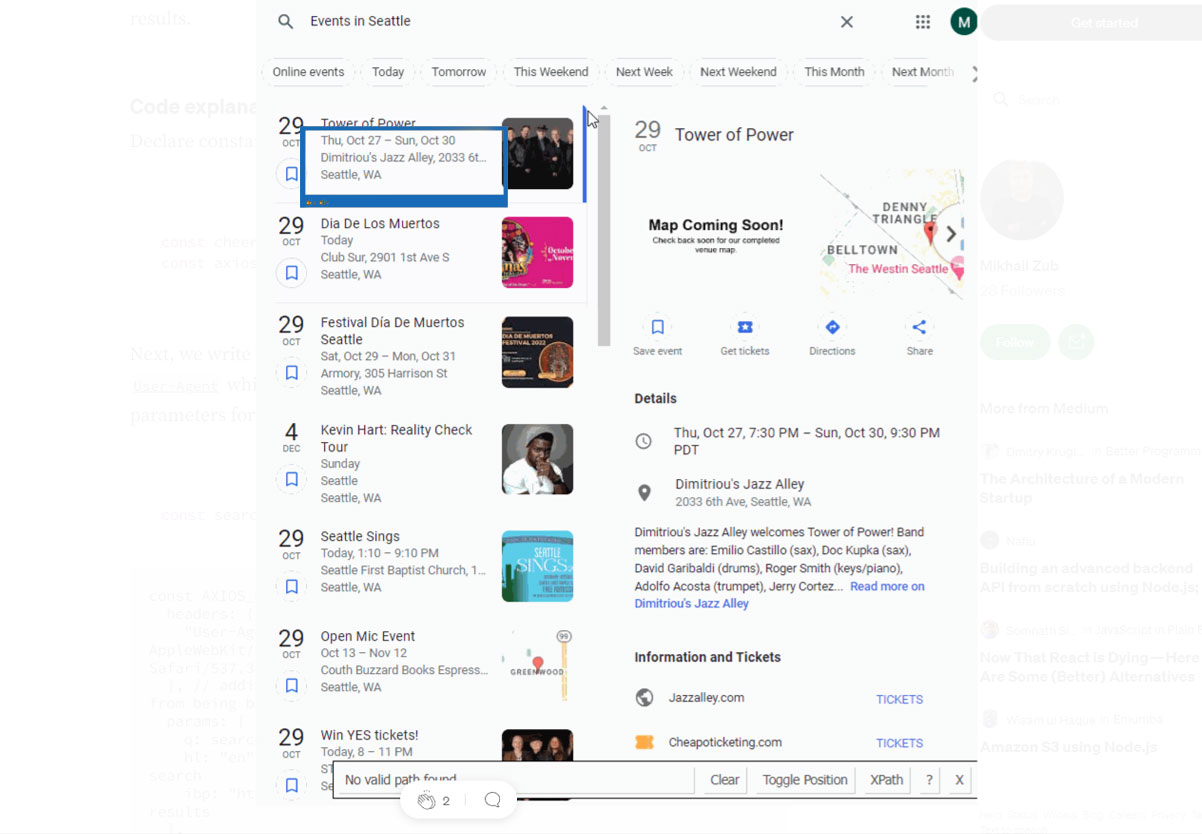
After that, we check in case no “events” results on a page, we revert null. We do it to stop the scraper while there are no pages left:
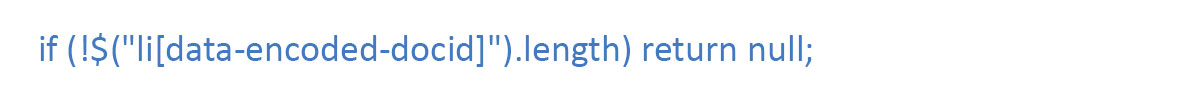
After that, we have to find images data from a script tags, as when a page loads for thumbnails as well as images utilize placeholders having resolution 1px x 1px with the real images and thumbnails are set with JavaScript in a browser.
Primary, we outline imagesPattern, then use spread syntax to create an array from the iterable iterators of matches, established from matchAll technique.
After that, we take results and create objects with the image url and id. To offer a valid url we have to remove "\x" chars (with replaceAll technique), decode that (with decodeURIComponent technique) and make from the objects images aray:

After that, we have to get various parts of a page with next methods:


After that, we write the function where we find results from every page (with while loop), check in case results are available, add them in the events array (push technique) and set request params newer start value (meaning that number from where we wish to see different results on next page).
While no more results on a page (else statement) we stop a loop and return events array:


Now we could launch a parser:

 Use Google Event API from Actowiz Solutions
Use Google Event API from Actowiz Solutions
This section shows a comparison between a DIY solution and Actowiz solution.
The largest difference is, you don’t have to make a parser from the scratch and preserve it.
There’s also an opportunity that a request could be blocked from Google, we deal with that on backend therefore, there’s no requirement to find out how to make that yourself or find out which proxy provider or CAPTCHA to use.
Initially, we have to install google-search-results-nodejs:

Here’s the complete code example, in case, you don’t want any explanation:


Primary, we have to declare Actowiz Solutions from google-search-results-nodejs library as well as get new search example with the API key from Actowiz Solutions:

After that, we write what is needed to search ( a searchQuery constant) and essential parameters to make a request:


After that, we wrap a search method from Actowiz Solutions library in the promise to work further with search results:

And lastly, we declare a function getResult which gets data from every page as well as return it:
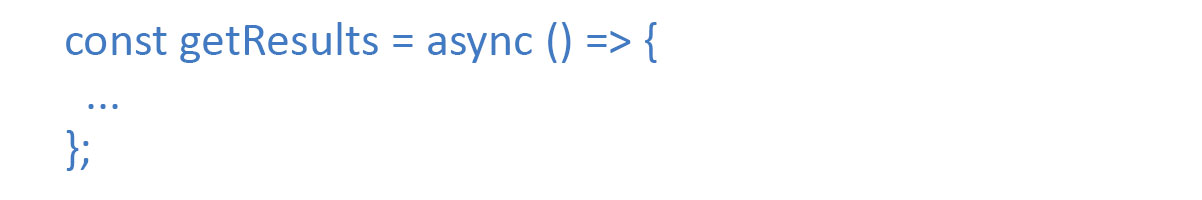
With this function, we find json with different results from every page (with while loop), observe if events_results are available, add them with eventsResults array (push technique) and set request new start value (meaning a number from where we wish to get results on next page).
While no more results on a page (else statement), stop a loop as well as return an eventsResults array:

After that, we run a getResults function as well as print all the collected information in a console with console.dir technique that helps you to utilize an object using the required parameters to alter default output alternatives:


And that’s it, the desired data is scraped!
For more information, contact Actowiz Solutions now!
You can also contact us for your mobile app scraping and web scraping services requirements.
Our web scraping expertise is relied on by 4,000+ global enterprises including Zomato, Tata Consumer, Subway, and Expedia — helping them turn web data into growth.
Watch how businesses like yours are using Actowiz data to drive growth.
From Zomato to Expedia — see why global leaders trust us with their data.
Backed by automation, data volume, and enterprise-grade scale — we help businesses from startups to Fortune 500s extract competitive insights across the USA, UK, UAE, and beyond.






We partner with agencies, system integrators, and technology platforms to deliver end-to-end solutions across the retail and digital shelf ecosystem.







Aggregate RERA data across all 28 Indian states + UTs. Real-time project, builder, and compliance intelligence for India ?40+ trillion real estate market.

Discover how a Q-commerce startup saved ₹2.8 Cr annually by tracking Blinkit, Zepto, and Instamart in real time. Learn how data-driven pricing and inventory insights boost efficiency and profitability.

Scrape In-N-Out Burger locations data in the USA in 2026 to analyze store expansion, regional coverage, and market trends.
Whether you're a startup or a Fortune 500 — we have the right plan for your data needs.



 E-commerce & Retail
E-commerce & Retail Grocery & FMCG
Grocery & FMCG Travel & Hospitality
Travel & Hospitality Food & Restaurants
Food & Restaurants Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Real Estate & Local
Real Estate & Local Automotive & Mobility
Automotive & Mobility Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries




























