
Scraping a mobile app directly can be more challenging compared to web scraping, as you don't have the convenience of using libraries like BeautifulSoup or requests. However, you can still extract data from a mobile app by using a combination of tools and techniques. Here's a high-level overview of the process to scrape data from a travel mobile app using Python:
Reverse Engineering and Analysis
Reverse engineering and analysis are essential steps in the process of scraping a mobile app. These steps involve understanding how the app communicates with its server, identifying API endpoints, and examining the data exchange between the app and the server. Here's a more detailed explanation of these steps:
Network Traffic Capture:
- To begin the analysis, you'll need to capture the network traffic between the mobile app and the server. There are tools available that can help you intercept and inspect this traffic.
- Popular tools for this purpose include Wireshark (for desktop) and Charles Proxy (which can be set up on both desktop and mobile devices).
Setting Up Charles Proxy (Optional):
- If you decide to use Charles Proxy, you'll need to set it up properly to capture the app's network traffic. This usually involves installing the Charles certificate on your mobile device or emulator.
Reproduce User Actions:
- Use the mobile app as a regular user would, triggering various actions like searching for flights, hotels, or other travel-related information.
- While you perform these actions, the proxy tool will capture the corresponding network requests and responses.
Inspecting Network Requests:
- Analyze the captured network requests in the proxy tool. Look for patterns in the URLs, headers, and parameters used in the requests.
- Pay attention to the HTTP methods (GET, POST, etc.) and the structure of the data exchanged.
Identifying API Endpoints:
- From the network requests, try to identify the API endpoints that the app is using to fetch data from the server.
- The API endpoints are URLs that usually start with https:// and contain specific paths to request data.
Examining Request Headers and Parameters:
- Inspect the headers and parameters included in the API requests. These may contain information such as authentication tokens, user-specific data, or search filters.
- Understanding the request headers and parameters is crucial for replicating these requests in your Python script.
Analyzing API Responses:
- Examine the responses received from the API endpoints. The data is often returned in JSON format, which can be analyzed and parsed easily using Python's json library.
Handling Authentication (If Required):
- If the app requires authentication, look for any special authentication mechanisms used in the requests (e.g., API keys, OAuth tokens, cookies).
- Determine how the app manages user sessions and include appropriate authentication headers or parameters in your Python script.
Pagination and Additional Features:
- Take note of any pagination or other features that affect how data is retrieved from the server in chunks. This might require additional logic in your Python script to handle multiple API calls.
By carefully analyzing the network traffic and understanding the app's API structure, you can proceed with creating Python scripts to interact with the app's server and scrape the desired travel-related data. Always remember to respect the app's terms of service and policies while conducting this analysis.
Extracting API Endpoints
To extract API endpoints from a mobile app, you'll need to analyze the network traffic between the app and the server using tools like Wireshark or Charles Proxy. Once you've captured the network traffic, follow these steps to identify the API endpoints:
Reproduce User Actions:
- Use the mobile app as a regular user would, performing actions that trigger data requests. For example, you might search for hotels, flights, or other travel-related information.
- During this process, the proxy tool will capture the relevant network requests and responses.
Filter Captured Traffic:
- Apply filters in the proxy tool to isolate only the traffic related to API requests. You can do this by looking for URLs that start with https:// (indicating HTTPS requests) or URLs that have a consistent pattern (e.g., /api/v1/).
Inspect Request URLs:
- Analyze the URLs of the captured requests. API endpoints are usually part of the URL path and start with a specific prefix, such as /api/, /v1/, or /data/.
- Look for patterns and common elements in the URLs that may indicate API endpoints.
Examine Request Methods:
- Pay attention to the HTTP methods (GET, POST, PUT, DELETE, etc.) used in the captured requests. Different methods might correspond to different API actions (e.g., GET for data retrieval, POST for data submission).
Identify URL Parameters:
- Some API endpoints might include query parameters in the URL. These parameters could be used for filtering, pagination, or other purposes.
- Take note of the parameters and their values, as they will be necessary for replicating the requests in your Python script.
Look for Authentication Information:
- Check if the API requests include any authentication information, such as API keys, OAuth tokens, or cookies. Understanding the authentication mechanism is crucial for making successful API calls in your script.
Analyze API Responses (Optional):
- If you want to understand the data structure returned by the API, inspect the responses as well. Most APIs return data in JSON format, which is human-readable and easy to parse.
Document and Organize:
- As you identify API endpoints, document them along with any necessary headers, parameters, and authentication details.
- Organize the information in a structured manner to make it easier to refer to while creating your Python script.
After extracting the API endpoints and other relevant information, you can use Python's requests library to make HTTP requests to these endpoints and retrieve the desired data from the app's server. Remember to respect the app's terms of service and policies while accessing its APIs.
Sending API Requests
Once you have identified the API endpoints and gathered the necessary information like request headers, parameters, and authentication details, you can use Python's requests library to send API requests. Here's a step-by-step guide on how to send API requests using Python:
1. Install the requests library:
If you haven't already installed the requests library, you can do so using pip in your terminal or command prompt:
pip install requests
2. Import the requests module:
In your Python script, import the requests module at the beginning of the code:
import requests
3. Prepare the API URL and Parameters:
Construct the full API URL by combining the base URL with the endpoint path and any necessary query parameters. For example:

4. Set Request Headers (if needed):
If the API requires specific headers, such as authentication tokens, user-agent, or content-type, include them in the request headers:

5. Sending a GET Request:
Use requests.get() to send a GET request to the API endpoint:
response = requests.get(url, headers=headers, params=params)
6. Sending a POST Request (if applicable):
If the API requires data submission, use requests.post() to send a POST request:

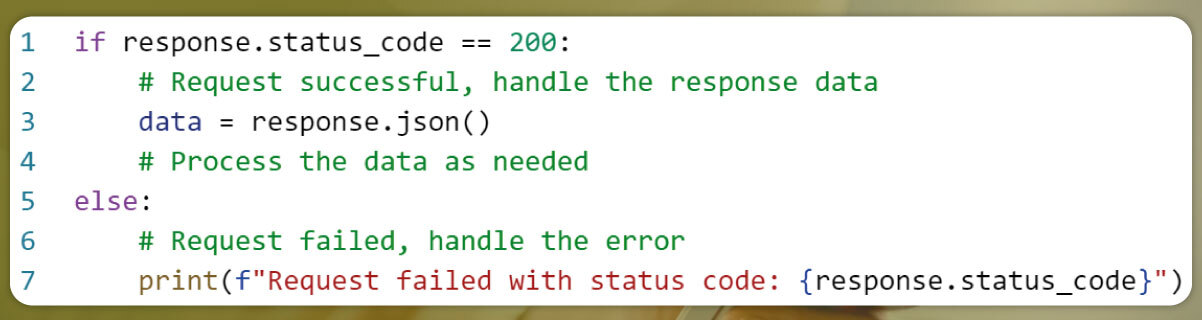
7. Handling the API Response:
Check the response status code to ensure the request was successful (status code 200):
8. Pagination and Looping (if needed):
If the API response is paginated and returns only a limited number of results, you may need to implement a loop to fetch multiple pages of data:
Remember to handle exceptions and error cases appropriately in your code, and always respect any rate limiting or usage restrictions specified by the API documentation. Additionally, ensure that you have permission to access and scrape data from the API as per the app's terms of service and policies.
Handling Authentication
Handling authentication is a crucial step when sending API requests to a mobile app's server. Many APIs require some form of authentication to verify the identity of the user or application accessing the data. Here are the common methods for handling authentication in Python when scraping a mobile app's API:
1. API Key Authentication:
Some APIs require an API key, which is a unique identifier associated with your app or account. To include the API key in your requests, add it to the request headers.

2. OAuth Token Authentication:
OAuth is a widely used authentication protocol that allows apps to access resources on behalf of users. You'll need to obtain an access token from the server after the user authenticates your app. Include the token in the headers.

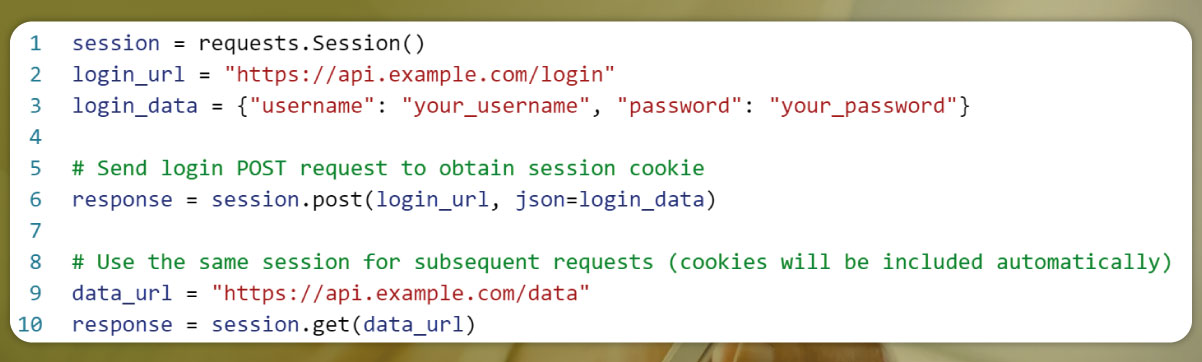
3. Session-based Authentication (Cookies):
Some APIs use cookies for session-based authentication. When a user logs in, the server sets a session cookie, which must be included in subsequent requests.
4. Handling Token Expiration and Refresh:
Some OAuth tokens have a limited validity period. If your token expires, you'll need to handle token refresh to obtain a new one without requiring the user to reauthenticate. Check the API documentation for details on token expiration and refresh.
5. Basic Authentication (Less Secure):
Some APIs may use basic authentication, where you encode a username and password in the request headers. However, this method is less secure and should be avoided if possible.

6. Multi-factor Authentication (MFA):
If the API requires multi-factor authentication, you'll need to handle the additional authentication steps, such as sending verification codes or handling authentication challenges.
Always check the API documentation for specific authentication requirements and follow best practices for securely storing sensitive information like API keys and tokens. Additionally, consider using environment variables or configuration files to manage sensitive data separately from your code.
Remember that unauthorized access to an app's API may be against the app's terms of service and could lead to legal consequences. Always ensure you have the proper permissions and authorization to access and scrape the app's data.
Parsing and Extracting Data
Once you've successfully sent API requests and received responses from the mobile app's server, the next step is to parse and extract the relevant data from the API response. Since APIs often return data in JSON format, you can use Python's built-in json module to parse the JSON data. Here's how you can do it:
1. Parse JSON Data:
Use the json.loads() function to convert the JSON response into a Python dictionary, which you can then work with in your code.

2. Extract Data from the Dictionary:
The parsed JSON data will be in the form of a Python dictionary. You can now navigate through the dictionary to access the specific data you need. This may involve using keys to access nested dictionaries or lists.

3. Handling Nested Data:
If the JSON response contains nested data (objects within objects or lists within lists), you'll need to traverse the structure accordingly.

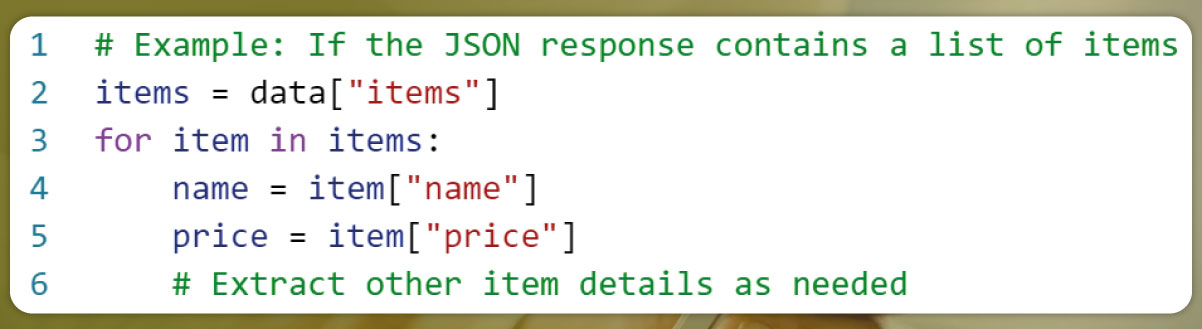
4. Iterating Through Lists:
If the JSON response contains a list of objects, you can use a loop to iterate through the list and extract data from each object.
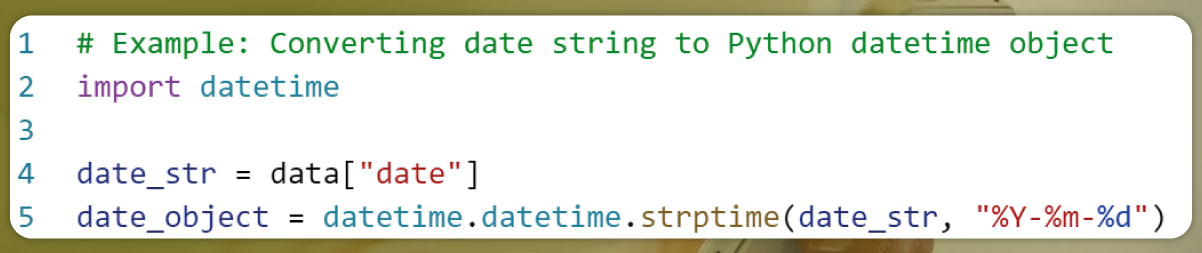
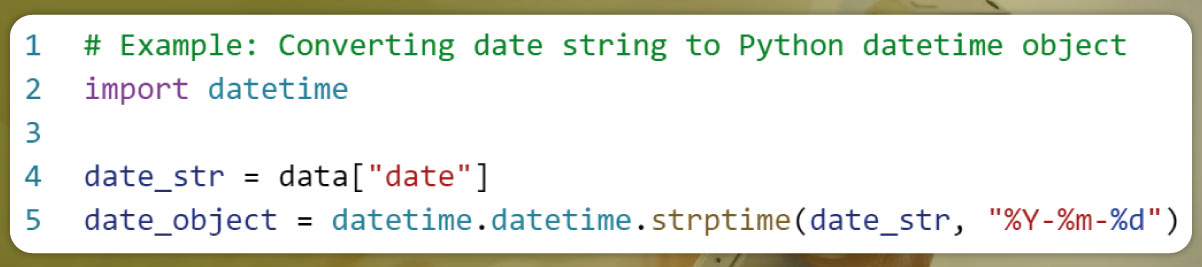
5. Data Conversion and Cleaning:
Sometimes, the JSON response may contain data in a specific format (e.g., date strings, numeric values). Convert or clean the data as required to match your desired output format.
6. Data Storage or Further Processing:
Once you've extracted the relevant data, you can store it in a database, write it to a CSV file, or process it further for analysis or visualization.
7. Error Handling:
Always include error handling when parsing JSON data. If the API response format is unexpected or there are missing keys, your code should handle these situations gracefully.
Remember that the structure of the JSON response can vary depending on the API endpoint and the data you requested. Make sure to review the API documentation to understand the data structure and key names to extract the data accurately.
If the API returns data in a format other than JSON (e.g., XML or HTML), you'll need to use different parsing methods or libraries accordingly. For XML, you can use the xml.etree.ElementTree module, and for HTML, you can use libraries like BeautifulSoup or lxml.
Handling Pagination
Handling pagination is necessary when the API response is paginated, meaning it only returns a limited amount of data per request. To retrieve all the data, you'll need to make multiple API calls, incrementing the page number or using a cursor-based approach. Here's how you can handle pagination in Python when scraping a mobile app's API:
1. Identify Pagination Information:
Look for pagination information in the API response. The API may provide details such as the current page number, the total number of pages, a "next" page URL, or a cursor to fetch the next set of data.
2. Pagination Parameters:
Determine the parameters needed to request specific pages or sets of data. Some APIs use a page parameter, while others may use offset or cursor.
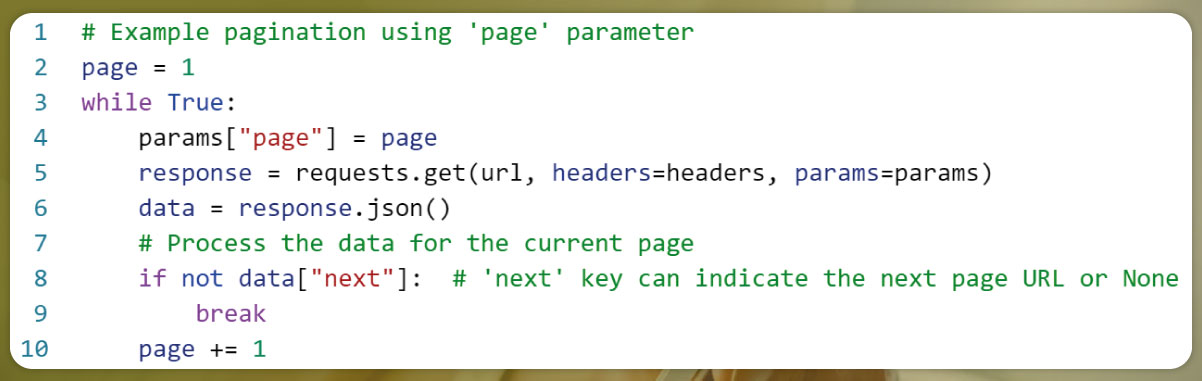
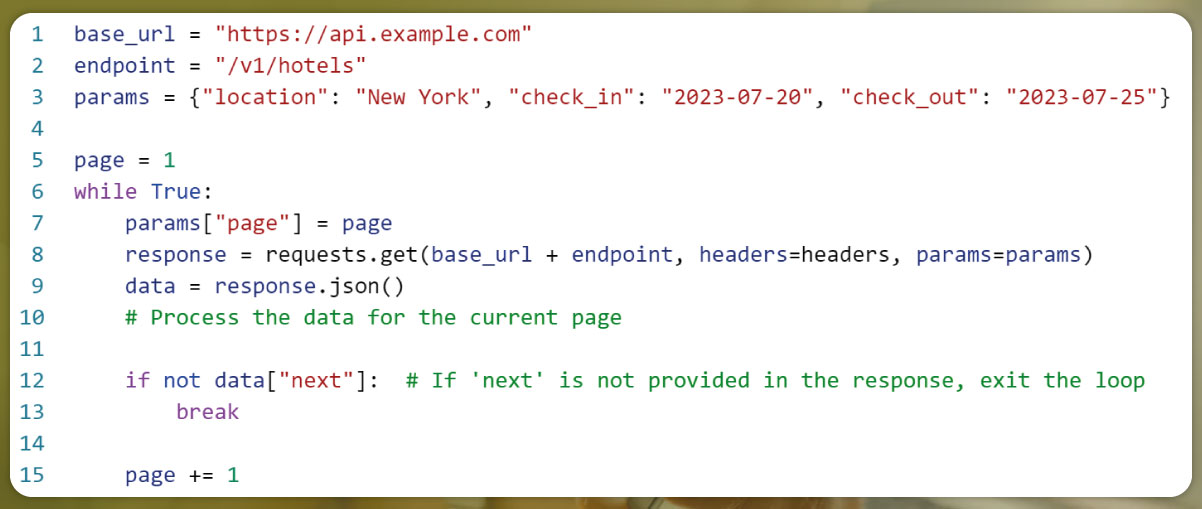
3. Loop through Pages:
Use a loop to iterate through the pages and make subsequent API requests to fetch all the data. Depending on the API's pagination information, you might use a while loop or a for loop.
Here's an example of pagination using the page parameter:
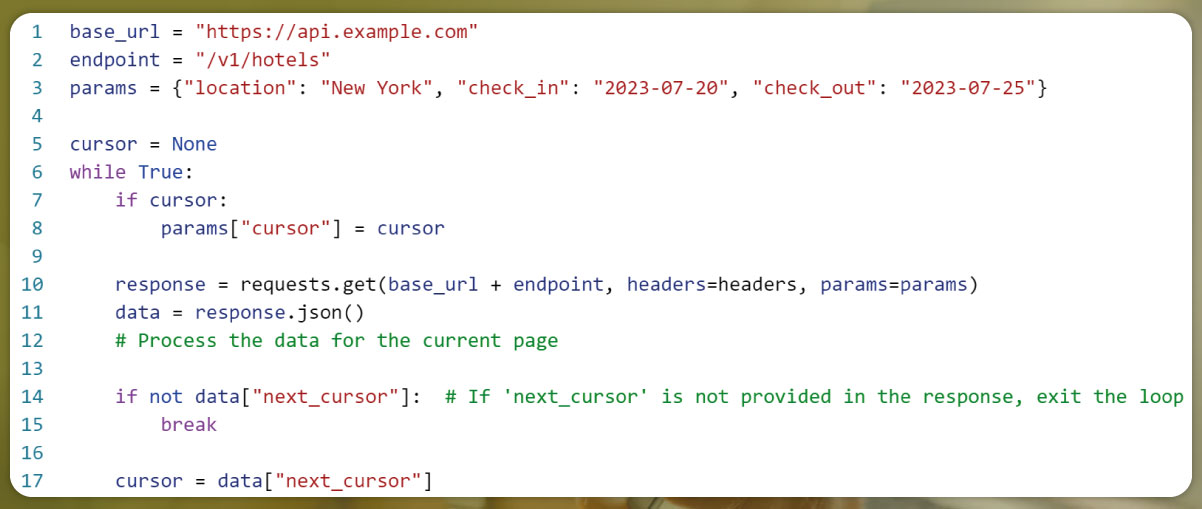
4. Cursor-Based Pagination (if applicable):
Some APIs use a cursor-based approach instead of page numbers. In this case, the API may provide a "next" cursor in the response that you'll need to use in subsequent requests to fetch the next set of data.
Here's an example of cursor-based pagination:
5. Rate Limiting and Delays:
When handling pagination, be mindful of rate limiting imposed by the API. Avoid making requests too frequently to avoid getting blocked.
Implement a delay between consecutive API calls to respect the API's rate limits and avoid overloading the server.
6. Combining and Storing Data:
Depending on your use case, you may need to combine the data from different pages into a single dataset or store each page's data separately.
Remember that the pagination approach may vary depending on the API's design and documentation. Always review the API documentation to understand the specific pagination method used and how to navigate through the pages correctly.
Rate Limiting and Respectful Scraping
Rate limiting and practicing respectful scraping are essential to ensure that you don't overload the server with too many requests and comply with the API's usage policies. Adhering to rate limits and being respectful in your scraping practices will help maintain a positive relationship with the app's server and reduce the risk of getting blocked or banned. Here are some tips on rate limiting and respectful scraping:
1. Read the API Documentation:
Before you start scraping, thoroughly read the API documentation to understand the rate limits, usage policies, and any specific guidelines on scraping the data. Different APIs may have varying rate limits, which dictate the maximum number of requests allowed per unit of time (e.g., requests per minute).
2. Implement Delays Between Requests:
- Add a time delay (sleep) between each API request to ensure that you're not making requests too frequently. The delay should align with the rate limits specified in the API documentation.
- Use Python's time.sleep() function to introduce delays in your script.

3. Use Exponential Backoff (Optional):
In some cases, APIs may return specific error codes when you exceed the rate limits. If you encounter such errors, consider implementing an exponential backoff strategy, where you progressively increase the delay between requests after receiving rate-limit-related errors.
4. Crawl Conservatively:
Start with a low request rate and gradually increase it based on the API's guidelines and your needs. Avoid making many requests in a short period, especially when you're still exploring the API's capabilities.
5. Cache Data (If Possible):
If the data you are scraping doesn't change frequently, consider caching the results locally to reduce the need for repeated API requests. Cache data for an appropriate duration and refresh it periodically.
6. Handle Rate-Limiting Errors Gracefully:
If you encounter rate-limiting errors (e.g., HTTP status code 429), handle them gracefully in your code. You can log the error, introduce a delay, or take other appropriate actions based on the specific error response.
7. Monitor Server Response Headers:
Some APIs provide rate-limit-related information in the response headers. Keep an eye on these headers to understand your remaining request quota and reset time.
8. Avoid Scraping Too Many Pages at Once:
When paginating through multiple pages, avoid making too many requests concurrently. Stick to a reasonable number of parallel requests to avoid overwhelming the server.
9. Follow the App's Terms of Service:
Always comply with the app's terms of service and usage policies. Unauthorized scraping or excessive requests may result in legal actions or being blocked from accessing the app's data.
By practicing rate limiting and respectful scraping, you not only ensure a positive relationship with the server but also contribute to the stability and reliability of the app's API for other users. Respectful scraping is essential for sustainable and ethical data collection practices.
Data Storage
Once you've successfully scraped and extracted the data from the mobile app's API, the next step is to store the data for further analysis, visualization, or other purposes. There are several options for data storage in Python. Here are some common approaches:
1. CSV (Comma-Separated Values):
If your data is relatively simple and tabular, you can store it in a CSV file using the csv module in Python. Each row in the CSV file represents a data record, and the columns contain the individual data fields.

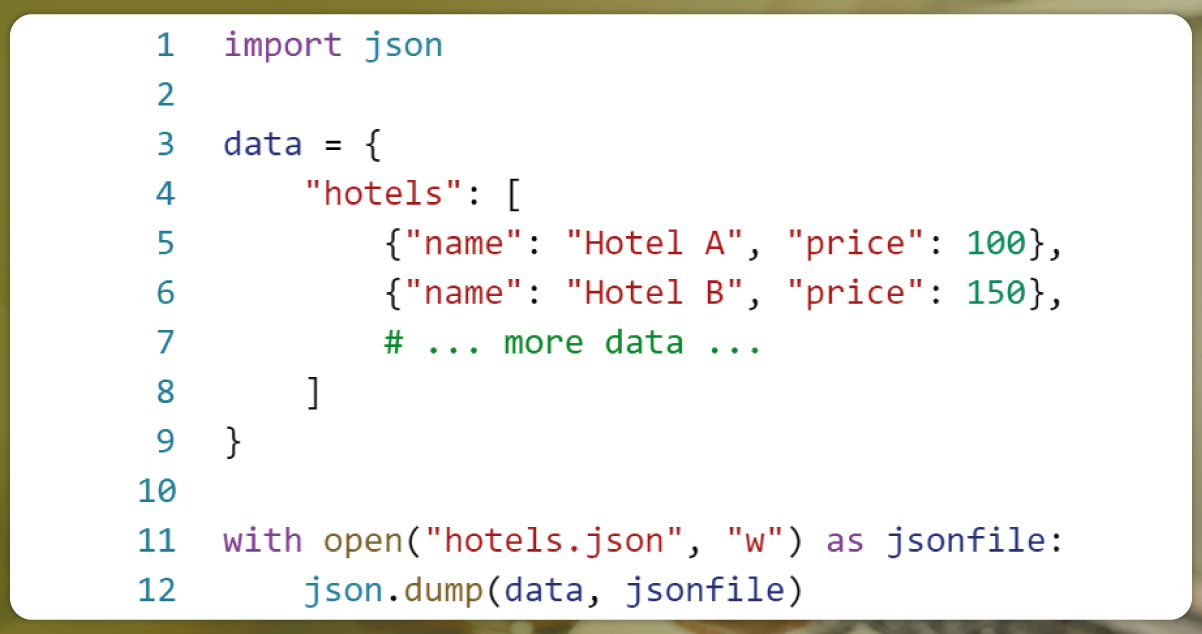
2. JSON (JavaScript Object Notation):
If your data is nested and requires more complex structures, you can store it in a JSON file. JSON is a lightweight data interchange format that is easy to work with in Python.
3. SQLite (Relational Database):
If you have a large amount of structured data and need to perform complex queries, you can store it in an SQLite database using the built-in sqlite3 module in Python.
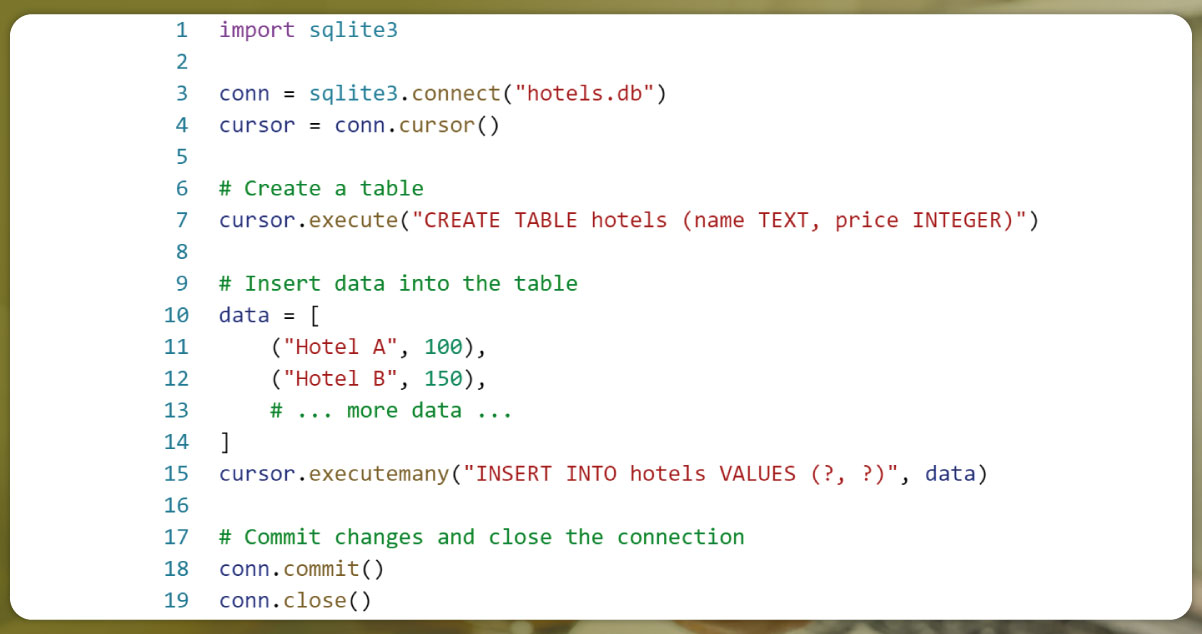
4. Pandas DataFrames (Tabular Data):
If you are working with tabular data, you can use the Pandas library to create DataFrames and manipulate the data easily. Pandas can also export the data to various formats, including CSV, Excel, and more.
Choose the storage method that best suits your data structure and future data processing needs. For large-scale projects or long-term data storage, a database like SQLite or PostgreSQL is usually a better choice. For smaller projects or quick data export, CSV or JSON files might suffice.
Remember to consider data security and privacy concerns when storing data. If your data contains sensitive information, take appropriate measures to protect it, such as encryption or access control.
Continuous Monitoring and Maintenance
Continuous monitoring and maintenance are crucial aspects of any scraping project, especially when scraping a mobile app's API. Mobile apps and APIs can undergo changes over time, which may impact your scraping code. Here are some tips for continuous monitoring and maintenance:
1. Monitor API Changes:
Regularly check the mobile app's API documentation for updates, changes in endpoints, authentication methods, rate limits, or any other modifications that might affect your scraping code.
2. Handle API Versioning:
If the API provides versioning, consider using a specific version of the API in your code. This way, you can ensure your scraping code continues to function as expected even if the API is updated.
3. Logging and Error Handling:
Implement robust logging and error handling in your scraping code. Log important events and errors to a file or database, so you can review and troubleshoot any issues that may arise.
4. Monitor Rate Limits:
Keep track of your scraping rate and adhere to the rate limits specified by the API. If your application starts hitting rate limits or receiving errors due to rate limiting, adjust your scraping frequency accordingly.
5. Alerts and Notifications:
Set up alerts or notifications to inform you if your scraping code encounters errors, rate-limiting issues, or other unexpected behavior. This way, you can respond promptly to any problems.
6. Test and Validate Regularly:
Regularly test your scraping code to ensure it is functioning correctly and that the data is being scraped accurately. Validate the scraped data against real-world data when possible.
7. Backup Data:
Back up your scraped data regularly to avoid losing it in case of unexpected issues or server failures.
8. Maintain Code Documentation:
Keep your code well-documented, explaining the purpose of different functions, how to set up the environment, and any configuration requirements. This will make it easier for you or others to maintain the code in the future.
9. Version Control:
Use version control (e.g., Git) to track changes to your scraping code. This allows you to revert to previous versions if needed and helps manage collaboration if multiple developers are involved.
10. Stay Compliant with Terms of Service:
Continuously review the app's terms of service and usage policies to ensure that your scraping practices comply with the app's guidelines.
11. Adapt to Changes:
Be prepared to modify your scraping code when the app's API or data structure changes. Adapt your code accordingly to handle new data formats or endpoints.
Remember that scraping an app's data without proper authorization or in violation of its terms of service may have legal implications. Always ensure you have the necessary permissions and adhere to ethical and legal practices when scraping data from mobile apps.
Legality and Terms of Service
The legality of scraping data from a mobile app's API depends on various factors, including the app's terms of service, copyright laws, data protection regulations, and the jurisdiction in which you operate. Before engaging in any scraping activity, it's essential to review the app's terms of service and ensure that you comply with all relevant laws and regulations.
Here are some important points to consider regarding the legality of scraping:
1. Terms of Service (ToS) and Robots.txt:
Many apps have specific terms of service that govern how their data can be accessed and used. Some apps explicitly prohibit scraping, while others may provide guidelines or APIs for data access.
Additionally, check if the app's website has a robots.txt file, which may include rules for web crawlers and scrapers. Following the rules in robots.txt is considered a standard practice in web scraping.
2. Obtain Permission (if required):
If the app's terms of service explicitly state that scraping is not allowed or require you to obtain permission, you must comply with those requirements. In some cases, you may need to contact the app's owners to seek permission for data scraping.
3. Respect Copyright and Intellectual Property:
Ensure that the data you are scraping is not protected by copyright or other intellectual property rights. Scraping copyrighted data without permission could lead to legal consequences.
4. Data Protection and Privacy Regulations:
Be aware of data protection and privacy laws that govern the handling of personal or sensitive data. Ensure that your scraping practices comply with applicable privacy regulations, such as the General Data Protection Regulation (GDPR) in the European Union.
5. Avoid Disruptive Scraping:
Your scraping activities should not overload the app's servers or disrupt its services. Respect rate limits, avoid making too many requests too quickly, and implement proper error handling to avoid unnecessary strain on the server.
6. Public vs. Private Data:
Data that is publicly accessible and freely available is generally considered more scrapeable than data that requires login credentials or is behind paywalls.
7. Scraper Identity and User-Agent:
Some apps may require you to include specific identification details, such as a valid user-agent, in your scraping requests to identify your scraper.
8. Jurisdictional Considerations:
Be aware of the legal landscape in your jurisdiction and the jurisdiction of the app's server. Laws regarding scraping can vary significantly from one country to another.
Always prioritize legal and ethical practices when scraping data from mobile apps or any other sources. If in doubt about the legality of scraping a particular app, consult legal experts or reach out to the app's owners for clarification. Respectful and responsible scraping practices will help you avoid legal issues and maintain a positive relationship with the app's owners and users.
Remember that mobile app scraping can be a complex and time-consuming process, and it might be subject to changes in the app's structure or API, making maintenance necessary.
Conclusion
Actowiz Solutions presents a comprehensive guide on "How To Scrape Travel Mobile App Using Python," empowering businesses in the travel industry with the knowledge and expertise to harness the power of web scraping ethically and effectively.
As a leader in data solutions, Actowiz Solutions understands the importance of accurate and up-to-date information in driving business growth and competitiveness. Our commitment to responsible scraping practices ensures that businesses can access valuable travel-related data without compromising the integrity of the mobile app or violating its terms of service.
With the expertise of our skilled Python developers, Actowiz Solutions offers custom scraping solutions tailored to the specific needs of each client. From identifying API endpoints and handling authentication to parsing and extracting data, our team employs industry-best practices to deliver accurate, reliable, and actionable insights for our clients in the travel sector.
By adhering to the principles of respectful scraping, Actowiz Solutions empowers businesses to make informed decisions, streamline operations, and stay ahead in a dynamic and ever-evolving travel industry. Our commitment to data integrity and legal compliance ensures that businesses can embrace web scraping as a powerful tool for growth without encountering any legal hurdles.
At Actowiz Solutions, we believe that ethical web scraping is the gateway to unlocking a wealth of opportunities in the travel sector. Our dedication to delivering high-quality scraping solutions is a testament to our commitment to excellence and the success of our clients.
Contact Actowiz Solutions today to embark on a journey of responsible web scraping and leverage the vast potential of data-driven insights for your travel business. You can also reach for all your mobile app scraping, instant data scraper and web scraping service requirements.
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming SOON
OTT & Streaming SOON
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing SOON
Dynamic Pricing / AI Repricing SOON
 Promotions & Deals Alerts SOON
Promotions & Deals Alerts SOON
 B2B / POI & Lead Data SOON
B2B / POI & Lead Data SOON
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries














































