
Introduction
In today's data-driven world, the ability to gather and analyze information from online sources is invaluable. If you're interested in e-commerce and fashion, Gap.com is a prominent retailer that offers a wide range of products, making it an ideal candidate for web scraping. This tutorial will guide you through the process of web scraping Gap.com to extract valuable product data using Python.
Gap.com provides an extensive selection of clothing, accessories, and more. Whether you're a data enthusiast looking to track price fluctuations, a business owner aiming to monitor trends, or a fashion enthusiast eager to stay updated with the latest arrivals, web scraping can be an indispensable tool.
Web scraping is the technique of extracting data from websites, and Python is a powerful language for this task. In this tutorial, we'll take you through the process step by step, from setting up your environment to writing the code necessary to scrape Gap.com for product information. You'll learn how to navigate the website, locate specific data, and store it for analysis.
By the end of this tutorial, you'll have a solid foundation in web scraping and Python, equipping you with the skills to explore and collect data from Gap.com and other websites, empowering you to make informed decisions and gain valuable insights. So, let's embark on this exciting journey into the world of web scraping and product data extraction from Gap.com.
Unlocking the Benefits of Web Scraping with Gap.com
Choosing Gap.com for web scraping offers several advantages, making it an appealing choice for data extraction. Here are some reasons why Gap.com is an excellent option for web scraping:
Product Diversity: Gap.com features various products, including clothing, accessories, and footwear. This diversity provides an extensive range of data that can be valuable for market analysis, trend tracking, and competitive research.

Relevant Data: Gap.com provides detailed product information, including product names, descriptions, prices, sizes, and customer reviews. This rich data can benefit e-commerce businesses, fashion enthusiasts, and market researchers.
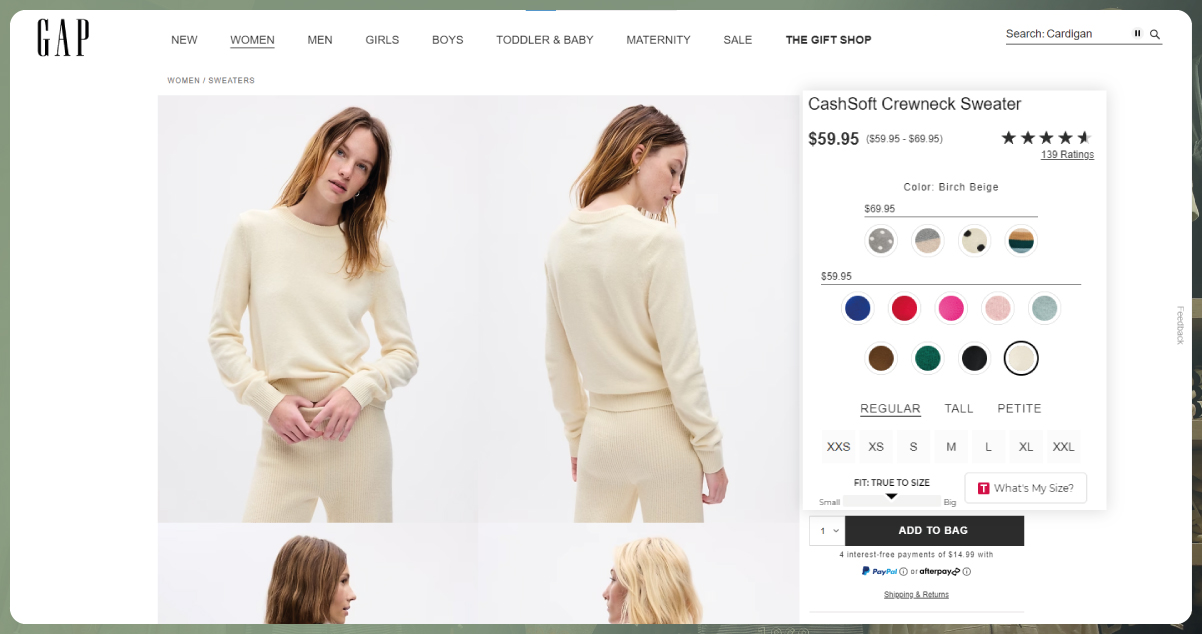
E-commerce Insights: Web scraping Gap.com can offer insights into pricing strategies, product availability, and stock levels. This information can be used for competitive pricing analysis and inventory management.

Fashion Trends: Gap is a well-known fashion brand. Scraping product data from Gap.com allows you to stay updated with the latest fashion trends, which can be particularly useful for fashion bloggers, retailers, and consumers.
Data-Driven Decisions: Web scraping empowers businesses and individuals to make data-driven decisions. By collecting data from Gap.com, you can analyze market trends, customer preferences, and product performance to inform your strategies.
Customization: Gap.com allows you to filter and sort products based on various criteria. With web scraping, you can customize your data collection to focus on specific product categories, sizes, or price ranges, tailoring the information to your needs.
Educational Value: Web scraping Gap.com is an excellent way to learn web scraping techniques using real-world data. It provides a practical and engaging environment for honing your web scraping and data extraction skills.
Legal and Ethical Considerations: Gap.com is a reputable e-commerce site, making it a suitable choice for scraping within legal and ethical boundaries. Respecting the website's terms of service and guidelines is crucial when web scraping and Gap.com's established reputation aligns with responsible scraping practices.
User Reviews: Gap.com includes user reviews and product ratings, offering insights into customer satisfaction and product quality. Accessing this information through web scraping can be valuable for businesses aiming to enhance their product offerings and customer experiences.
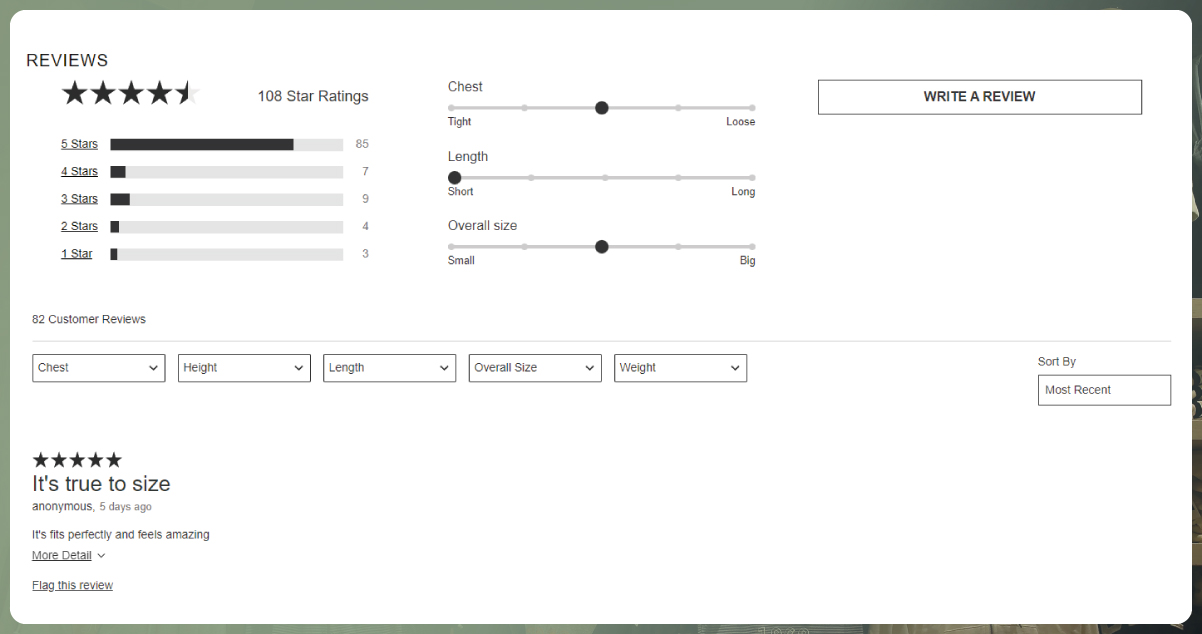
Overall, Gap.com presents an appealing opportunity for web scraping due to its diverse product range, rich data, and the potential insights it can provide to businesses, researchers, and fashion enthusiasts. When conducting web scraping on Gap.com, it's essential to adhere to best practices, respect the website's terms of service, and conduct your scraping activities responsibly and ethically.
Key Data Elements to Extract Through Web Scraping
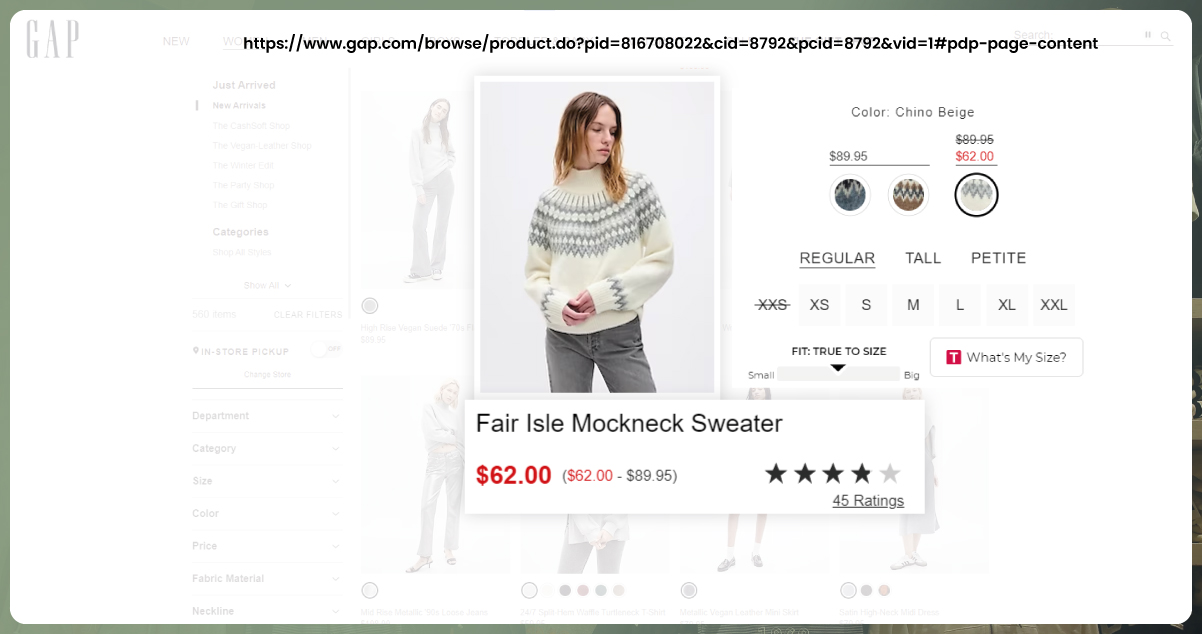
When web-scraping Gap.com, there are several vital attributes you can extract from the website. These attributes can provide valuable data for various purposes, including market analysis, trend tracking, and competitive research. Some of the attributes you may consider scraping from Gap.com include:
Product Names: Extracting product names helps you identify and categorize the items available on Gap.com.
Product Descriptions: Gathering product descriptions provides detailed information about the features, materials, and characteristics of the products.
Prices: Scraping prices allows you to monitor fluctuations, compare prices with competitors, and identify discounts or special offers.
Sizes: Extracting available sizes helps you understand the range of options for each product.
Colors: Collecting information about the available colors for each product is essential for fashion and retail analysis.
Product Ratings: Scraping customer reviews and ratings provides insights into product satisfaction and quality.
Customer Reviews: Gathering customer reviews and comments lets you understand customer feedback and sentiment regarding specific products.
Product Availability: Monitoring product availability helps inventory management and ensures products are in stock.
Category Information: Extracting category details helps organize and categorize products into relevant groups.
Product URLs: Scraping product URLs enables you to access specific product pages for further analysis or reference.
Brand Information: Gathering data about the brand and manufacturer of each product is essential for brand-specific research.
Promotional Information: Extracting information about promotions, discounts, or special offers allows you to track and analyze marketing strategies.
Images: Collecting product images can be beneficial for creating visual catalogs or conducting image analysis.
SKU (Stock Keeping Unit) or Product ID: Scraping SKU or product ID data aids in unique product identification and tracking.
Shipping and Delivery Information: Extracting information about shipping options, delivery times, and costs can be valuable for customers and retailers.
Product Specifications: Gathering technical details and specifications can be helpful for product comparisons and technical analysis.
Material Information: Scraping data about product materials is vital for fashion and product quality analysis.
Customer Q&A: Collecting questions and answers from customers can provide insights into common inquiries and product details.
These attributes, when extracted through web scraping, can empower businesses, researchers, and consumers with valuable information for informed decision-making and analysis. Remember to scrape responsibly, respecting Gap.com's terms of service and guidelines, and ensure that your web scraping activities comply with legal and ethical standards.
Incorporating Essential Python Libraries for Enhanced Functionality
The initial segment of the code focuses on importing a set of vital Python libraries, each designed to serve specific purposes, enabling a wide range of functionalities within the program. In this particular script, we harness the capabilities of seven distinct libraries, each contributing to successfully executing various tasks.
These libraries empower us to interact with web browsers through automated control of web drivers, streamlining actions like web scraping and data retrieval. Additionally, they facilitate the organization and storage of data in a structured tabular format, simplifying data management and analysis.
By incorporating these versatile libraries, the code leverages a diverse set of tools to ensure that the intended operations run smoothly and efficiently. Whether automating web interactions or structuring data for analysis, these libraries form the program's foundation, enhancing its capabilities and making it a powerful tool for various tasks.
Webdriver in the Context of Web Scraping

In web scraping, a webdriver refers to a tool or software component that allows for the automation of web interactions, navigation, and data retrieval from websites. Web scraping is the process of extracting information from web pages, and webdrivers play a crucial role in making this process efficient and effective.
A webdriver controls a web browser programmatically, enabling the automated loading of web pages, clicking on links and buttons, filling out forms, and interacting with the page's elements, such as text fields and dropdown menus. It can also retrieve the page source code and extract specific data or information. Web drivers are beneficial when dealing with websites that have complex structures, dynamic content loaded through JavaScript, or require user interactions to access the desired data.
Popular web drivers like Selenium WebDriver, Puppeteer, or headless browser drivers like ChromeDriver and GeckoDriver are commonly employed in web scraping tasks. These web drivers provide an interface for developers to script interactions with web pages, making it possible to scrape data at scale without manual intervention.
Some Popular Web Drivers for Web Scraping
Web scraping often relies on web drivers and automation frameworks to interact with web pages and extract data. Here are a few examples of popular web drivers and the associated libraries/frameworks commonly used for web scraping:
Selenium WebDriver: As you've already noted, Selenium is a widely used web automation framework. It allows you to control web browsers like Chrome, Firefox, Edge, etc., programmatically. You can interact with web elements, navigate web pages, and extract data. In your code, you're using the Selenium import web driver for importing Selenium driver.

Beautiful Soup: Beautiful Soup is a Python library parsing HTML and XML documents. It's not a web driver itself but is often used in conjunction with web drivers like Selenium to extract data from web pages. You can use it to parse the HTML source code of web pages and extract specific information. You've imported Beautiful Soup from bs4 import BeautifulSoup in your code.
The other libraries you've imported, such as time, re, random, unicodedata, and pandas, are commonly used in web scraping for tasks like managing delays, performing regular expressions, handling text data, and storing data in a structured format.
Let’s understand all one by one in detail:
1. Selenium Web Driver

Selenium WebDriver, a powerful tool for automating web browser interactions, plays a pivotal role in web scraping endeavors. With the capability to mimic human user actions, WebDriver empowers developers to automate a wide array of tasks such as website navigation, button clicks, and form submissions. This is especially valuable in web scraping where the need to interact with dynamic websites is common.
In our specific use case, we employ the Chrome WebDriver, although it's essential to note that WebDriver implementations are available for various web browsers, allowing you to choose the one that best suits your needs.
Here are some additional insights into how WebDriver proves instrumental in web scraping:
Handling JavaScript-Protected Websites: WebDriver is invaluable for scraping data from websites fortified with JavaScript. Many modern websites rely on JavaScript to load content dynamically, and traditional scraping methods may fall short in such scenarios. WebDriver, on the other hand, can interact with the web page just like a human user, allowing it to access the content generated by JavaScript.
Dealing with User Authentication: Certain websites require user authentication before granting access to specific content. WebDriver can automate the login process, providing a seamless means to scrape data from authenticated areas of websites. This functionality is especially useful for extracting information from membership-based sites or private databases.
Versatile Automation Tool: Beyond web scraping, WebDriver finds applications in automating a wide range of web-related tasks. Whether it's automating regression testing, monitoring websites for changes, or extracting data at regular intervals, WebDriver is a versatile tool with myriad applications in the realm of web development and automation.
2. Time

To ensure responsible and respectful scraping practices, it's important to introduce time delays between your requests. This is where the sleep() function in Python becomes indispensable. The sleep() function enables you to pause the execution of your script for a specified duration in seconds.
The rationale behind using sleep() in web scraping is twofold:
Avoiding Overloading Servers: When you scrape a website, especially one with limited server resources, making too many requests in quick succession can overload the server. This not only hampers your scraping efforts but can also lead to your IP address being blocked. By incorporating time delays between requests, you give the server breathing room, reducing the risk of overloading and subsequent blockage.
Mimicking Human Behavior: To avoid raising suspicion and bypass anti-scraping measures implemented by some websites, it's beneficial for mimicking human behavior in your web scraping script. Human users don't click links, submit forms, or navigate web pages instantly. They take a moment to read and interact. The sleep() function helps replicate this behavior, making your script appear more human-like and less likely to trigger security measures on the target website.
In essence, WebDriver and the sleep() function are two indispensable tools for web scraping. While WebDriver empowers you to interact with websites dynamically and extract data, sleep() helps you maintain ethical scraping practices by introducing delays, allowing you to scrape responsibly and efficiently. These combined tools open up a world of possibilities in web scraping, from data collection to automation and beyond.
3. BeautifulSoup or bs4
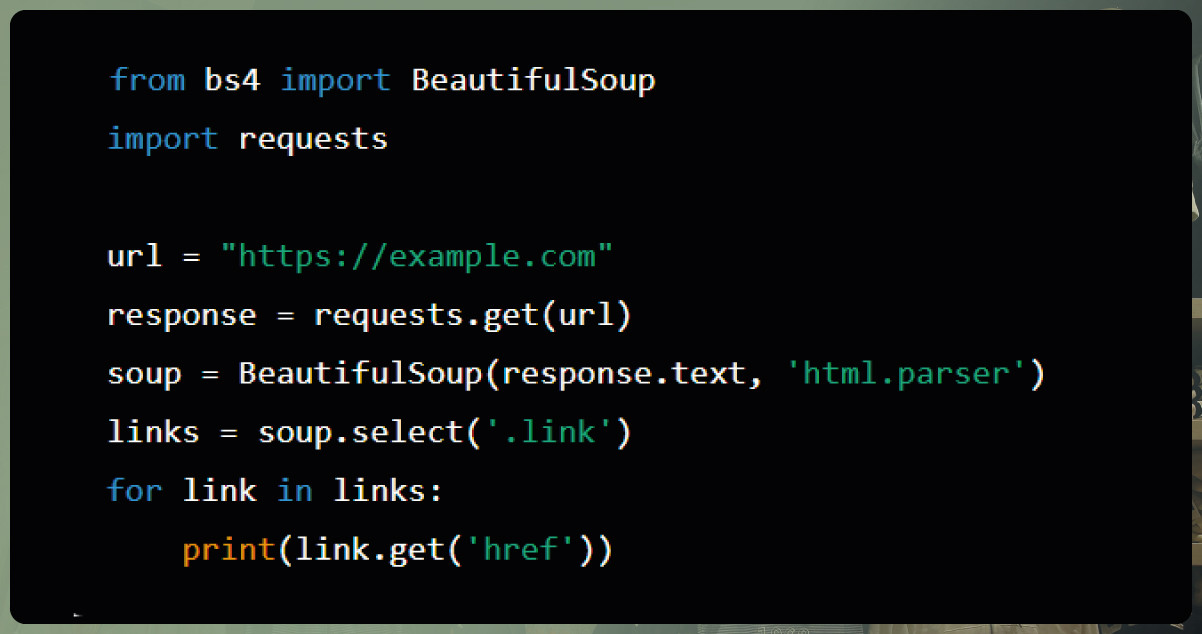
Beautiful Soup, often called "bs4," is a Python library that excels in parsing HTML and XML documents, providing the means to construct a parse tree from the document's content. This parse tree serves as a structured representation of the document's structure, allowing for easy data extraction.
Beautiful Soup is a robust and versatile tool, making it a preferred choice for web scraping tasks. Its popularity stems from several factors, making it an indispensable asset in the web scraping toolkit:
User-Friendly: Beautiful Soup is renowned for its user-friendly design, making it accessible to beginners and experienced developers. Its intuitive API simplifies navigating and extracting data from web pages.
Feature-Rich: Beautiful Soup boasts many features that facilitate data extraction. Whether you're looking to retrieve specific elements, search for patterns in the document, or manipulate the parse tree, Beautiful Soup provides many functions to cater to your needs.
Speed and Efficiency: Besides its ease of use, Beautiful Soup is known for its speed and efficiency in parsing HTML documents. This ensures that web scraping tasks can be executed swiftly, even on larger websites.
Well-Documented: Beautiful Soup's comprehensive documentation is a valuable resource for developers. It offers clear explanations, code examples, and usage guidelines, making it easier to harness the library's full potential.
Supportive Community: Beautiful Soup benefits from a large and active community of users and developers. This vibrant community not only aids in troubleshooting and problem-solving but also contributes to the continuous improvement of the library.
In practical terms, using Beautiful Soup for web scraping typically involves parsing the HTML content of a target website. Developers often specify a parser, such as the "lxml" parser, known for its speed and efficiency, making it an excellent choice for web scraping tasks.
The selected parser, in this case, "lxml," works by creating a parse tree that reflects the hierarchical structure of the HTML document. This tree structure is then leveraged to locate, extract, and manipulate data within the document, streamlining the web scraping process.
Beautiful Soup, commonly called "bs4," is a versatile and user-friendly Python library that plays a pivotal role in web scraping by parsing HTML and XML documents, enabling the extraction of valuable data. Its ease of use, rich feature set, speed, extensive documentation, and supportive community make it an ideal choice for web scraping projects of all scales and complexities.
4. Regular expressions (or regex)

Regular expressions, commonly known as "regex," are an indispensable tool for pattern matching and text manipulation. They empower users to identify specific patterns within text, extract data, and execute various text-related tasks, making them a staple in web scraping endeavors.
Python's built-in library, the "re" module, is a reliable platform for harnessing the potential of regular expressions. With this module, developers can achieve a spectrum of tasks, including:
Pattern Discovery: Regular expressions enable users to locate specific patterns within text, allowing for precise data extraction.
Data Extraction: The "re" module facilitates extracting data from text, streamlining the process of isolating relevant information from vast datasets.
Text Replacement: Regular expressions can replace specific text patterns with alternative content, facilitating data cleaning and transformation.
Text Segmentation: They can also split text into substrings, aiding in data organization and analysis.
Pattern Matching: Regular expressions are adept at matching multiple patterns within text, providing a versatile tool for various applications.
In the context of web scraping, regular expressions come into play as an invaluable resource for:
Data Retrieval: By scrutinizing the HTML source code of web pages, regular expressions can pinpoint and extract the desired data efficiently.
Data Validation: They can validate extracted data, ensuring its accuracy and conformity with predefined patterns or criteria.
Data Cleansing: Regular expressions are a crucial asset for cleaning and refining scraped data, ensuring it adheres to specific formatting or quality standards.
While mastering regular expressions can be challenging due to their syntax intricacies, they are an indispensable asset for automating an array of tasks in web scraping. Their capacity to navigate, extract, and manipulate data, in tandem with Python's "re" module, empowers developers to create robust web scraping scripts capable of handling diverse data sources and patterns.
5. The random Module

The "random" module in Python is a versatile and powerful library that provides a wide array of functions for generating pseudo-random numbers and performing various randomization tasks. This module is a valuable tool in programming, statistics, simulations, and game development, among other domains.
Critical functions within the "random" module allow developers to create randomness in their programs, adding unpredictability and variability. Some of the prominent features of this module include:
Number Generation: The module offers functions to generate random integers, floating-point numbers, and sequences. These numbers are not truly random but are based on deterministic algorithms, making them suitable for various applications.
Seeding: Developers can control the randomness by setting a seed value. This ensures that the sequence of random numbers remains consistent across different program runs, making it useful for debugging and reproducibility.
Shuffling and Sampling: The "random" module allows the shuffling of sequences like lists, enabling the creation of randomized orderings. It also supports random sampling from sequences, making it a valuable tool for data analysis and simulations.
Random Choices: You can make random selections from a sequence with varying probabilities, providing flexibility for scenarios like weighted random choices.
Cryptographically Secure Randomness: For applications requiring higher security, Python offers the "secrets" module, which builds on "random" but is designed for cryptographic purposes.
The "random" module is an essential component in Python's standard library, facilitating the introduction of randomness and unpredictability in programs. Its broad spectrum of features makes it an invaluable tool for tasks ranging from game design and statistical simulations to cryptographic applications and everyday programming where controlled randomness is needed.
6. Unidecode
Unicode, a universal character encoding system, serves as the linchpin for representing an extensive array of characters from diverse writing systems, spanning Latin, Greek, Chinese, and countless others. It is the predominant character encoding system utilized by contemporary computers, ensuring seamless cross-system compatibility and representation.
Python's "unicodedata" module is a crucial component that grants access to the Unicode Character Database. Within this database lies a wealth of information regarding every character encompassed by the Unicode standard, encompassing their respective names, code points, and properties.
In web scraping, the "unicodedata" module emerges as a formidable ally, addressing text encoding intricacies and cleansing challenges that often arise. Its utility spans:
Text Encoding Harmony: The module plays a pivotal role in harmonizing text encoding discrepancies, mainly when the text employs a different encoding than anticipated by the code. This ensures that text data is seamlessly interpreted and processed.
Invisible Character Removal: "unicodedata" can effectively excise invisible characters, such as non-breaking spaces, from the text. These characters, while not visible, can significantly impact data parsing and integrity.
Text Standardization: The module lends itself to the task of standardizing text, converting it into a consistent and recognizable format, which simplifies downstream data processing.
In web scraping, where data integrity and consistency are paramount, the "unicodedata" module emerges as a potent tool. For instance, it can be employed to normalize zero-width space characters, which often denote line breaks and can cause interpretation issues in web scraping. By normalizing such characters, web scrapers can ensure that text is devoid of unwanted anomalies, resulting in cleaner and more straightforward parsing.
7. Pandas

Pandas, a versatile Python library, is an invaluable tool for managing and analyzing tabular data, offering high-performance data structures and user-friendly data analysis capabilities. Its widespread usage extends to data cleaning, transformation, and detailed data examination.
At the heart of Pandas lies the DataFrame data structure, which mirrors the spreadsheet format with rows and columns, enabling efficient data organization and storage. This structure is precious in web scraping, where the need to manage and process structured data extracted from web pages is paramount.
The DataFrame proves indispensable in various aspects of web scraping, allowing practitioners to:
Data Storage: With Pandas, web scrapers can seamlessly store and organize extracted data from web pages, providing a structured and easily accessible repository.
Data Enhancement: The library facilitates data cleaning and manipulation, enabling the transformation of raw web data into a refined, usable format.
Data Exploration: Pandas empowers users to delve into in-depth data analysis, offering tools and functions for tasks like aggregation, summarization, and visualization.
Data Export: To facilitate further analysis or data sharing, Pandas offers the convenient .to_csv() method, allowing users to export a DataFrame to a CSV file effortlessly. A CSV file, as a text-based format, simplifies data exchange and storage by structuring data into rows and columns, separated by commas.
In essence, Pandas streamlines the entire data lifecycle in web scraping, from data extraction and storage to cleaning, analysis, and export. Its user-friendly interface and robust feature set make it an indispensable companion for web scrapers, enabling them to work with structured data efficiently and effectively.
Global Constants
You can define these global constants in your Python script as follows:

In the code above, PLP_URL represents the URL of the web page you want to scrape data from, and CSV_FILENAME is the name of the output CSV file where the scraped data will be stored. You can replace these values with the specific URL and file name relevant to your web scraping project. These constants can be accessed and used throughout your script as needed.
Set the WebDriver
You can set the Chrome WebDriver using the selenium library as follows:
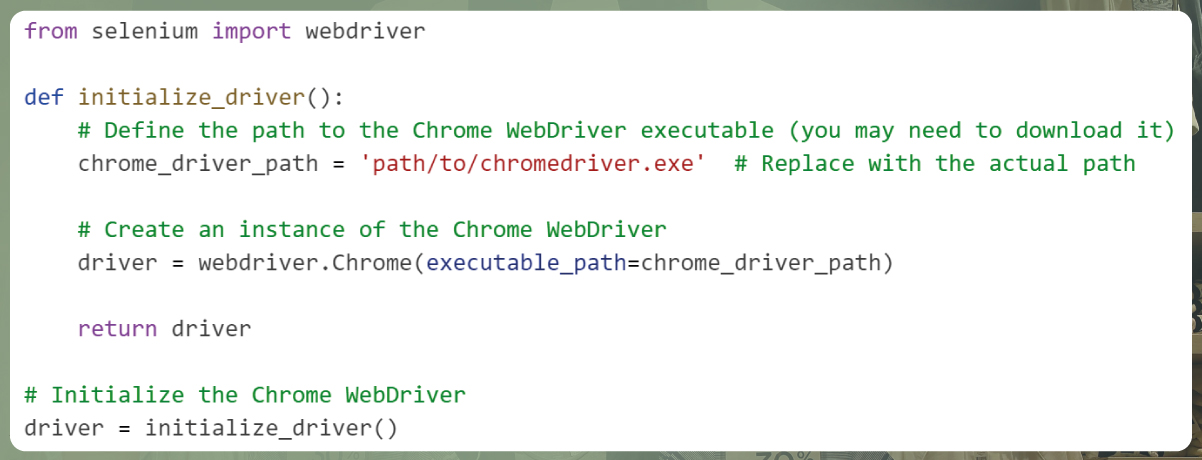
In the code above, you first import the webdriver module from selenium. Then, you define a function called initialize_driver() that creates an instance of the Chrome WebDriver. You need to specify the path to the Chrome WebDriver executable (replace 'path/to/chromedriver.exe' with the actual path on your system).
After defining the function, you call it to initialize the Chrome WebDriver, and the instance is stored in the driver variable. This driver variable can be used to control the web browser and interact with the web page, activating the elements on the dynamic website for web scraping.
Scrolling Down the Page
To scroll down the page multiple times to activate elements, you can use the following code as an example:
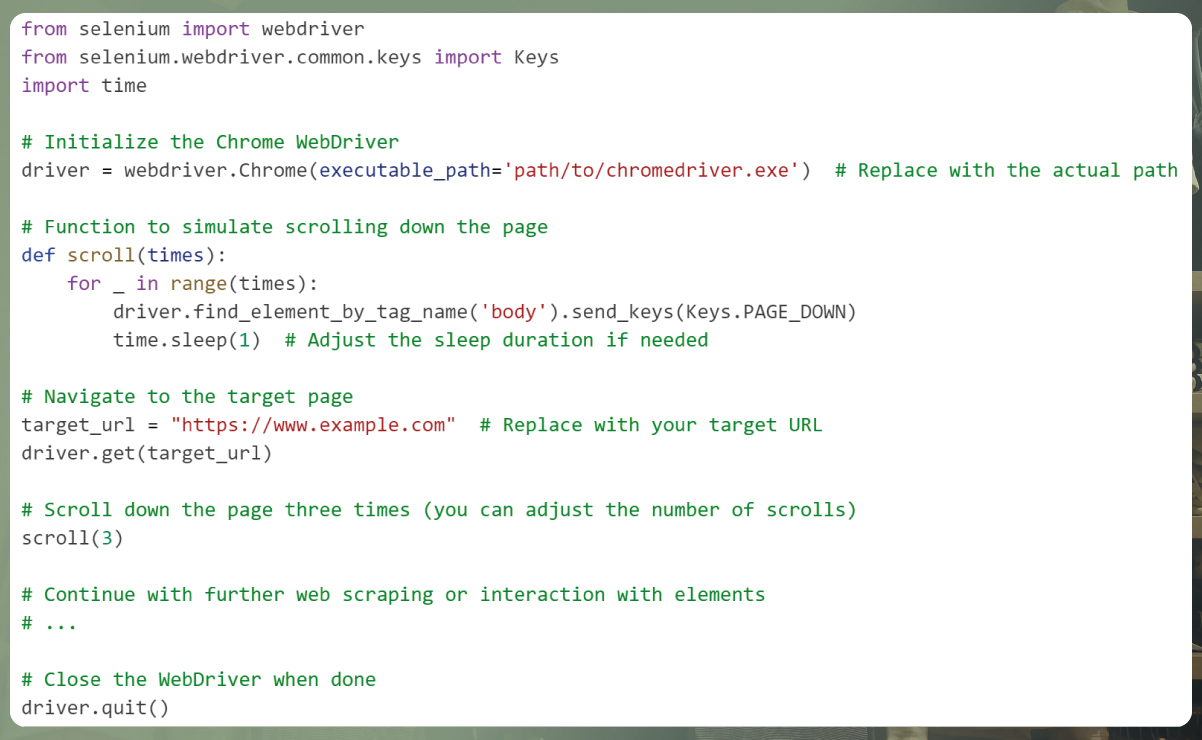
In this code:
We import the necessary modules, including webdriver for controlling the browser, Keys for keyboard actions, and time for adding delays.
We initialize the Chrome WebDriver with the path to the Chrome WebDriver executable.
We define a scroll() function that simulates scrolling down the page using the Keys.PAGE_DOWN action. You can call this function with the desired number of scrolls.
We navigate to the target URL and perform the specified number of scrolls to load more content.
After scrolling, you can continue with your web scraping or interaction with the loaded elements.
Finally, we close the WebDriver when the scraping is complete.
Please make sure to replace 'path/to/chromedriver.exe' with the actual path to your Chrome WebDriver executable and https://www.example.com with the URL of your target web page. Adjust the number of scrolls and sleep duration as needed for your specific scraping scenario.
Mimic Human Behavior
To incorporate random delays in your script to mimic human behavior, you can use the random module to create the random_sleep() function. Here's the code to achieve this:

In this code:
We import the random module for generating random numbers and the time module for adding delays.
The random_sleep() function generates a random delay between 4 to 7 seconds using random.uniform(4, 7). The uniform function returns a floating-point number within the specified range, which is ideal for simulating more natural human behavior.
You can call random_sleep() at appropriate places in your script to introduce random delays, making the web scraping script appear less robotic and more like human behavior. This helps in avoiding detection or anti-scraping measures on some websites.
Getting BeautifulSoup Object
To parse the HTML source code of a web page using the BeautifulSoup library with the "lxml" parser, you can create a get_soup() function as described. Here's the code to achieve this:
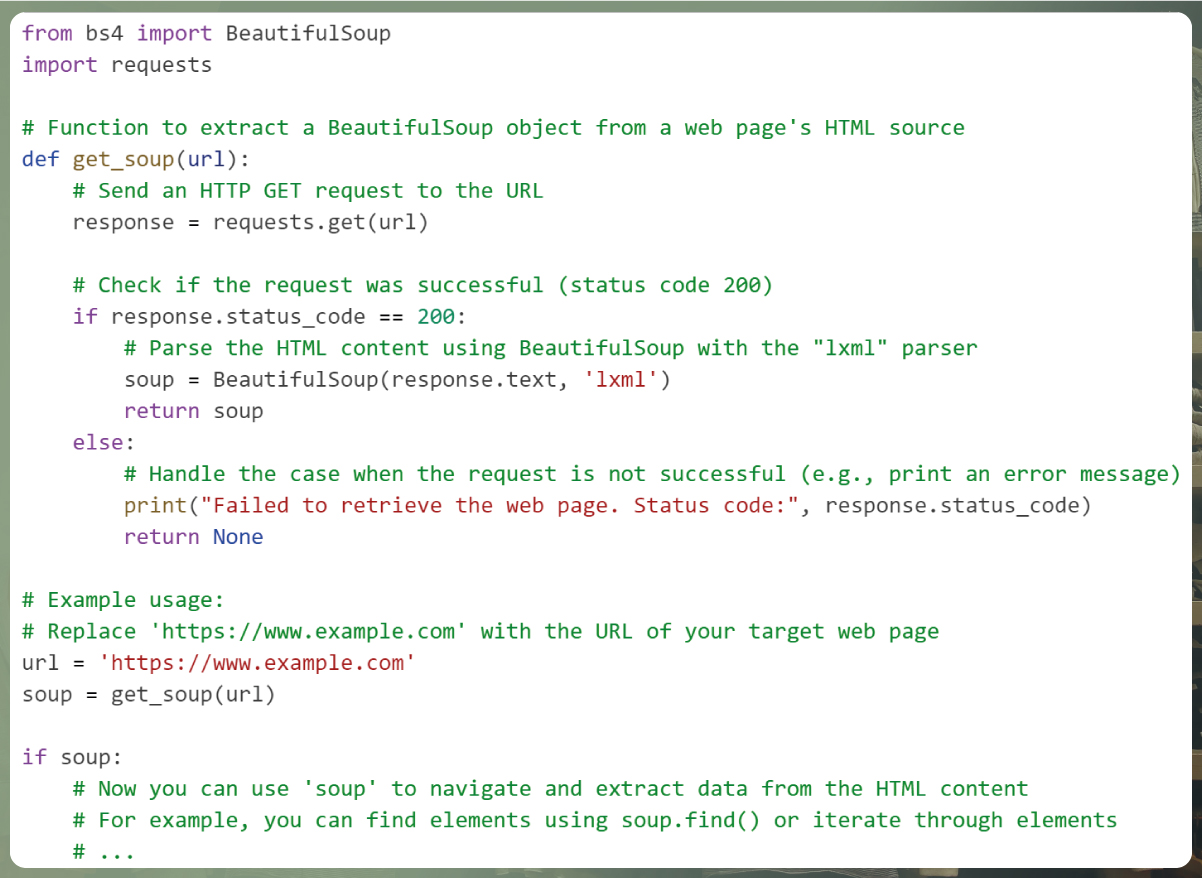
In this code:
We import the necessary libraries, including BeautifulSoup from bs4 and requests for making HTTP requests.
The get_soup() function takes a URL as input, sends an HTTP GET request to that URL, and checks if the request is successful (status code 200).
If the request is successful, it parses the HTML content using BeautifulSoup with the "lxml" parser.
The BeautifulSoup object, soup, is returned, which you can then use to navigate the HTML content and extract data.
In the example usage, you provide the URL of your target web page, and the function retrieves the HTML source and creates a BeautifulSoup object. You can then proceed to extract data from the web page using soup.
Flow of Main Program
Certainly, here's an example of the main program that calls the defined functions to perform web scraping and stores the extracted data. It also includes a check to ensure that it's executed directly and not imported as a module:

In this code:
We define the global constants and functions for initializing the WebDriver, scrolling, adding random sleep delays, and extracting a BeautifulSoup object.
The main() function is where the main scraping process occurs. It initializes the WebDriver, navigates to the target page, scrolls down to activate elements, extracts data using BeautifulSoup (which you can customize), stores the data in a DataFrame, exports it to a CSV file, and closes the WebDriver.
The if __name__ == "__main__": block ensures that the main() function is executed when the script is run directly.
Please make sure to replace 'path/to/chromedriver.exe' with the actual path to your Chrome WebDriver executable, and customize the data extraction process according to your specific web scraping requirements.
Flow of Main Program - pdp url extraction
Let's break down the description and provide you with the code for the specific function that extracts the PDP URLs from the "div" elements.
Description:
The target web page, "Men New Arrivals at Gap," contains 288 products.
A BeautifulSoup object is used to parse the HTML of the page.
We navigate the HTML to extract the "div" elements that represent each of the 288 products.
The PDP URL of each product is obtained from these "div" elements.
The URLs are cleaned to ensure they don't contain unnecessary parts and are stored in a list for reference.
Code for extracting PDP URLs:
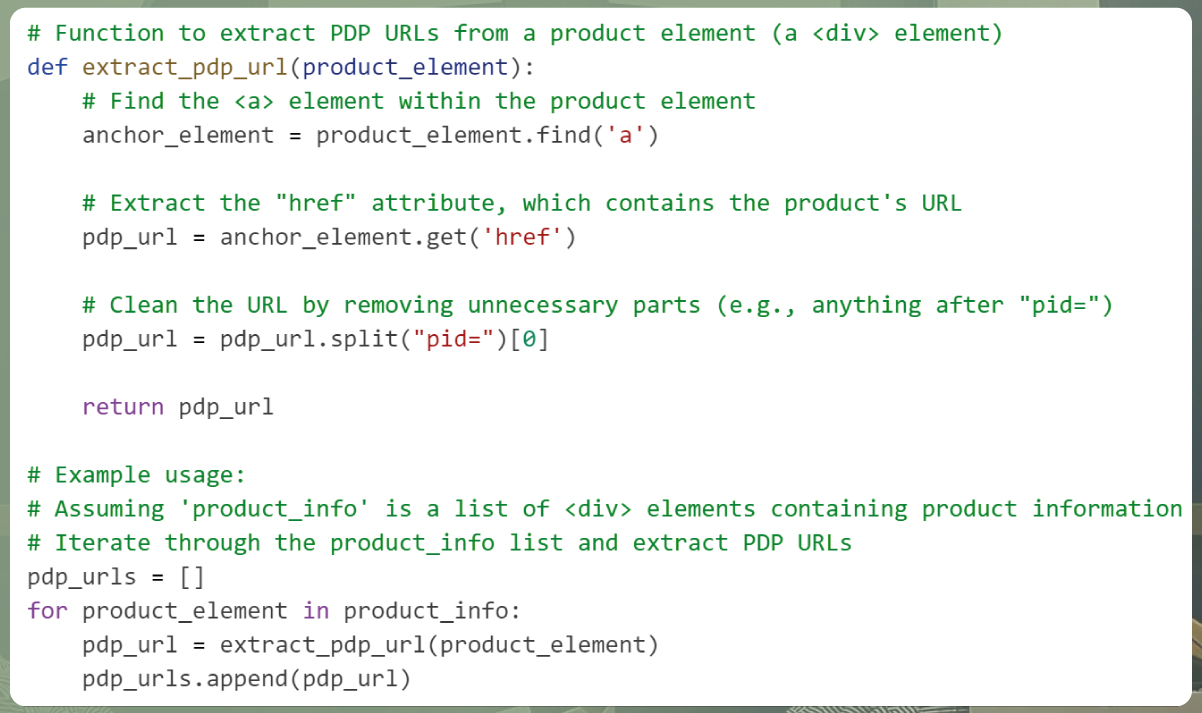
In this code:
The extract_pdp_url() function takes a product element (a
Flow of Main Program Flow - product data extraction
The primary program extracts product data from each PDP (Product Description Page) URL. It does so by iterating through the list of PDP URLs, visiting each URL, and parsing the HTML source code of the respective product page using BeautifulSoup with the "lxml" parser. After parsing, the extracted data is obtained using specific functions designed for each aspect of the product. The program keeps track of the count of products for which data has been successfully extracted.
Code for product data extraction:
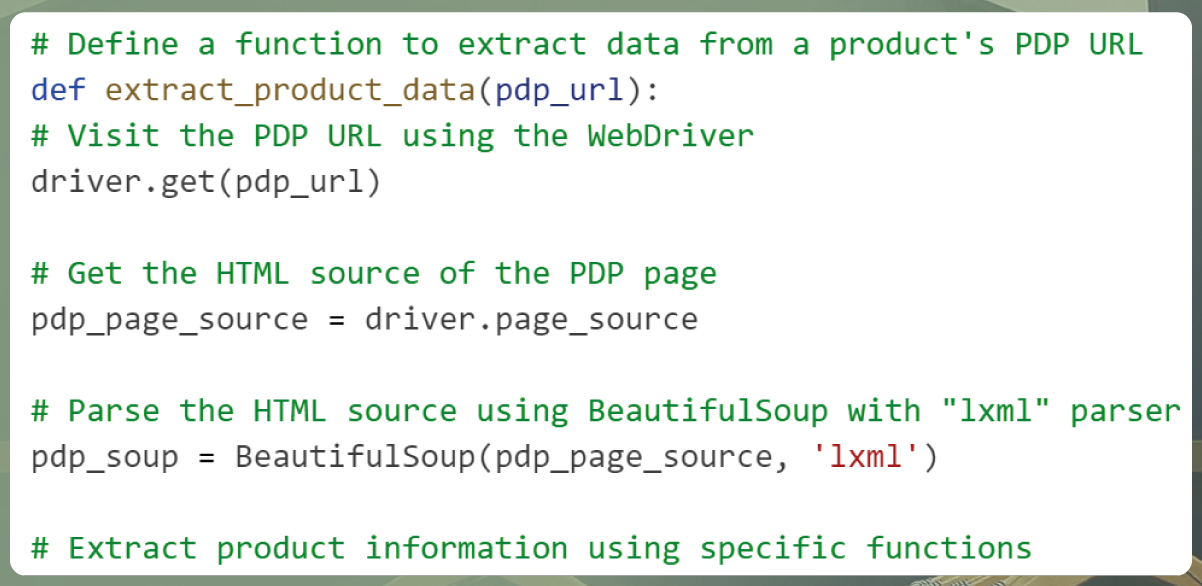
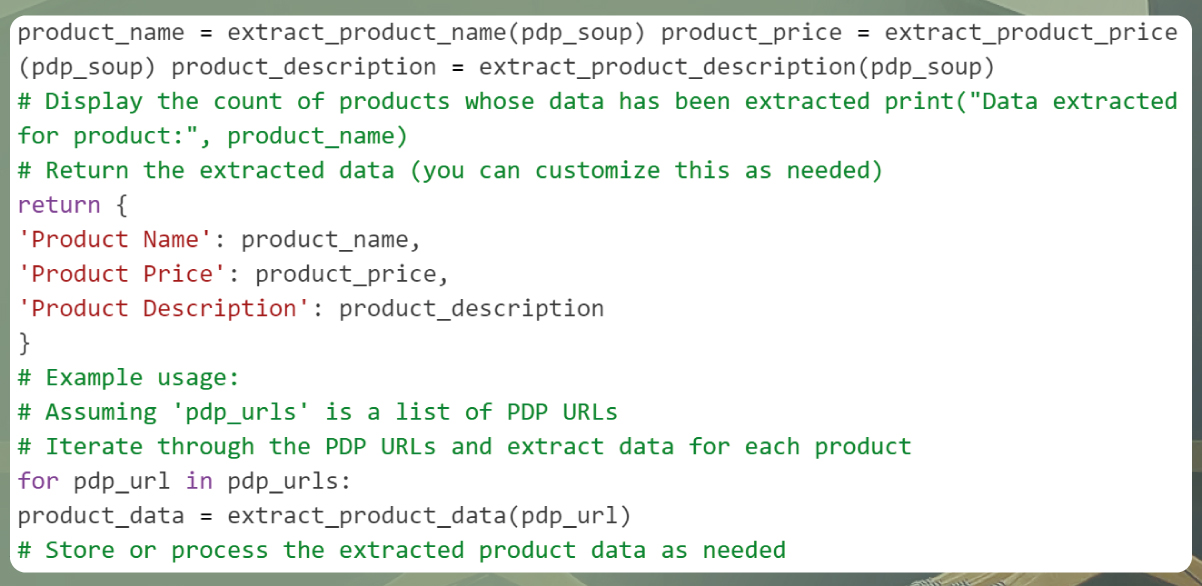
In this code:
The extract_product_data() function takes a PDP URL as input.
It navigates to the PDP URL using the WebDriver, retrieves the HTML source of the page, and parses it with BeautifulSoup using the "lxml" parser.
The product information, such as name, price, and description, is extracted using specific functions (e.g., extract_product_name(), extract_product_price(), and extract_product_description()). You can customize these functions to match the structure of the product pages you are scraping.
The count of products for which data has been successfully extracted is displayed for tracking.
The extracted data is returned as a dictionary for further processing or storage. You can adapt the returned data structure based on your requirements.
You can use this code to extract data from each PDP URL in the list and store or process the product data as needed.
Scraping Product Information
Lset's provide an explanation and code examples for each of the functions responsible for extracting various product information from the product pages.
Extracting Product Type:
This function retrieves the product category or type from a product page through identifying a targeted
Extracting Product Name:
Explanation: This function captures the product name from the product page by seeking out an < h1 > element with a class attribute that commences with "pdp-mfe-". It retrieves the text content within this element, thereby obtaining the product's name. The rationale for searching for class attributes beginning with "pdp-mfe-" is that various product names on different pages have different class names, all sharing the common prefix of "pdp-mfe-."
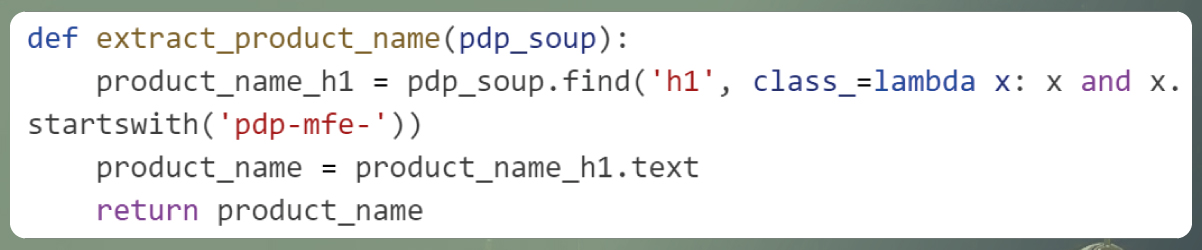
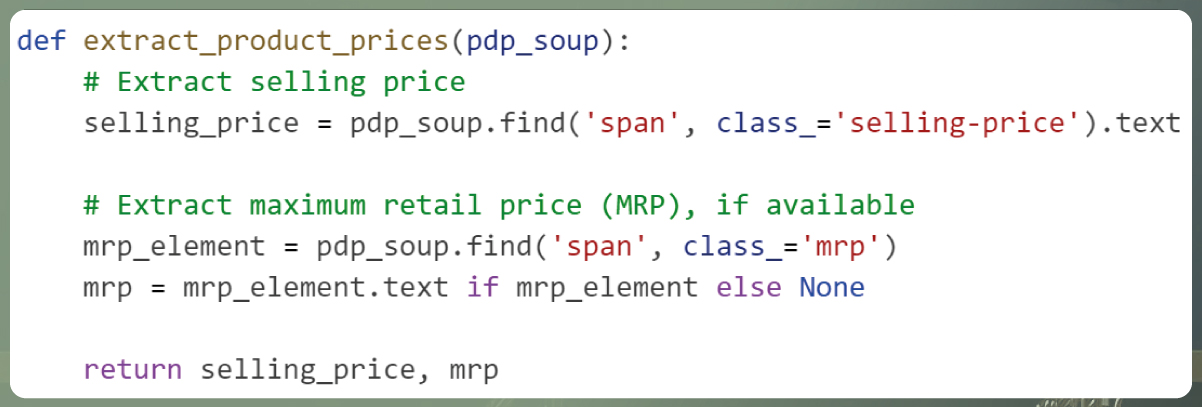
Extracting Product Prices:
Explanation: This function retrieves the product's pricing details, encompassing both the selling price and the maximum retail price (MRP), from the product page. It identifies pricing-related elements and extracts the pertinent text information. This function is designed to handle scenarios where either a single price is displayed or where a price range is presented.
Extracting Product Rating:
Explanation: This function acquires the product's rating, specifically the average star rating, from the product page. It locates a element with the class "pdp-mfe-3jhqep" that contains the rating information, extracts the rating value, and ensures it is presented in a cleaned format.

Extracting Number of Ratings:
Explanation: This function retrieves the count of the product ratings from a product page. It scans for the
element tagged with a class "pdp-mfe-17iathi" and isolates the initial portion of text contained within this element.

Extracting Product Color:
Explanation: This function obtains a product's color details from a product page through identifying the element distinguished by a class called "swatch-label__value" and extracting the text enclosed within this element.

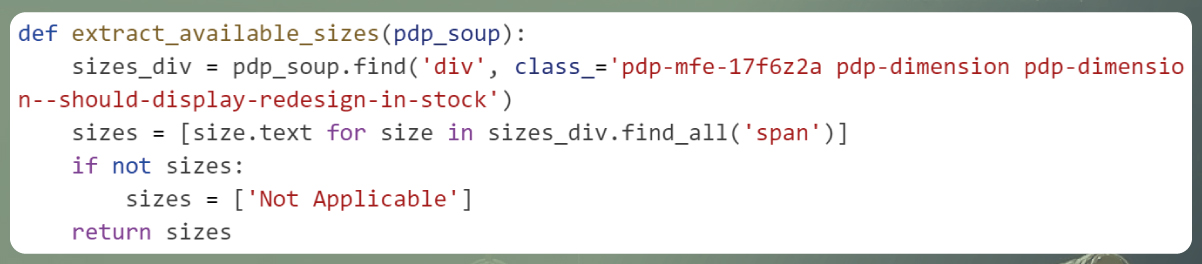
Extracting Available Sizes:
Explanation: This function retrieves the available sizes for the product by examining the product page for elements associated with size information. It compiles the text corresponding to each available size into a list. In situations where certain products (e.g., bags, caps) lack traditional sizes, the function returns "Not Applicable."
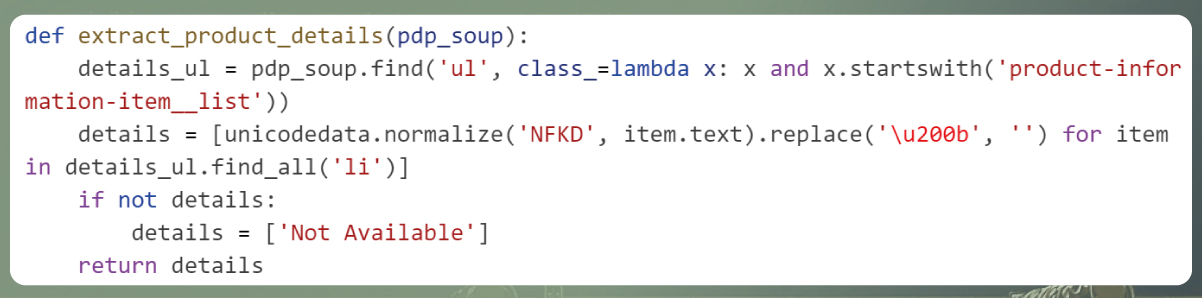
Extracting Additional Product Details:
Explanation: This function is tasked with extracting diverse product details, encompassing aspects like fit & sizing, product specifics, and fabric & care instructions. These details are identified and extracted from the
element distinguished by a class attribute that begins with "product-information-item__list." To ensure standardized character representation, the extracted text undergoes Unicode normalization, eliminating any "ZERO WIDTH SPACE" characters.
Flow of Main Program with data storage
In the main function, once the data scraping is completed, the collected data needs to be stored for proper analysis. To achieve this, we save the data into a CSV (Comma-Separated Values) file.
Here's the flow of this process:
After obtaining the product information in each iteration, we initialize a pandas DataFrame. A DataFrame is a powerful data structure for working with tabular data, making it suitable for storing the scraped product details.
During each iteration, the product information obtained from the product page is added to the initialized DataFrame.
After iterating through all 288 products, we write the DataFrame to a CSV file. This CSV file will contain the structured product data, making it easy to analyze and work with in various data analysis tools.
A positive message is then displayed to indicate the successful data storage process.
Finally, the Chrome WebDriver instance is closed using the driver.quit() command to clean up resources.
Here's the code to accomplish this data storage process:
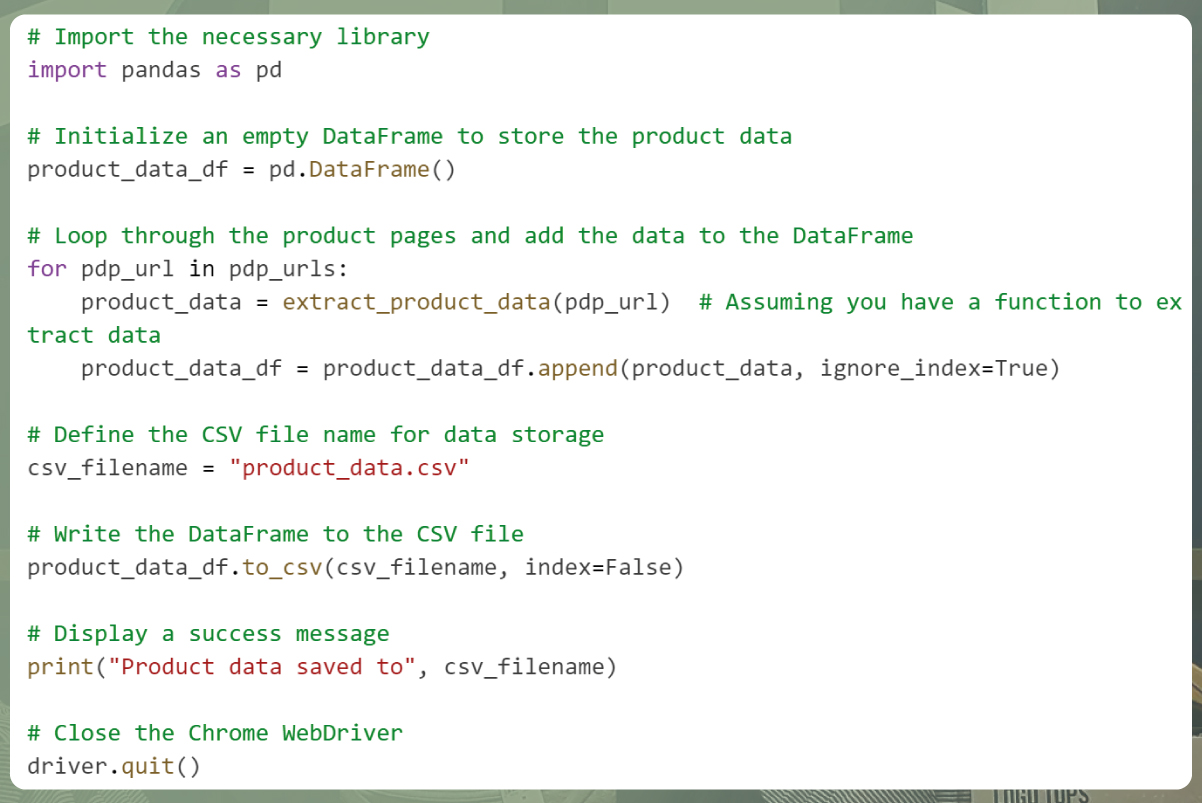
In this code:
We create a DataFrame called product_data_df to store the product data.
During the loop where we extract data for each product, we append the extracted data to the DataFrame using the append() method.
After processing all products, we define the CSV file name and write the DataFrame to the CSV file using to_csv().
A success message is displayed to inform that the product data has been saved to the CSV file.
Finally, we close the Chrome WebDriver instance to release resources.
This approach ensures that the product information is saved in a structured format in a CSV file for further analysis and use.
Conclusion
For those individuals looking to harness the power of web scraping tools or APIs for retrieving product data from Gap, this script offers a valuable resource. The data it extracts can be a goldmine for in-depth analysis, unveiling a wealth of insights into market trends and consumer preferences. Stay tuned for our upcoming blog post, where we'll delve into our analysis of this data, sharing exciting and informative findings.
Whether your focus is on Gap or any other e-commerce platform, Actowiz Solutions is your trusted partner for streamlining your web scraping requirements. Explore the efficiency of our E-commerce Data Scraping Services to gather valuable insights and stay ahead in the competitive e-commerce landscape. Feel free to contact us and discover how we can empower your business with data-driven insights!
With the capabilities of web scraping and data analysis, you can gain a competitive edge in understanding market dynamics, pricing strategies, and consumer behavior. Take advantage of the opportunity to leverage data for informed decision-making and strategic planning. You can also reach us for all mobile app scraping, instant data scraper and web scraping service requirements.
Real Results from Real Clients
Hear It Directly from Our Clients
Watch how businesses like yours are using Actowiz data to drive growth.
★★★★★
"Actowiz Solutions offered exceptional support with transparency and guidance throughout. Anna and Saga made the process easy for a non-technical user like me. Great service, fair pricing!"
TG
Thomas Galido
Co-Founder / Head of Product at Upright Data Inc.
★★★★★
"Actowiz delivered impeccable results for our company. Their team ensured data accuracy and on-time delivery. The competitive intelligence completely transformed our pricing strategy."
II
Iulen Ibanez
CEO / Datacy.es
★★★★★
"What impressed me most was the speed — we went from requirement to production data in under 48 hours. The API integration was seamless and the support team is always responsive."
FC
Febbin Chacko
-Fin, Small Business Owner
 4.8/5
4.8/5 Average Rating
 50+
50+ Video Testimonials
 92%
92% Client Retention
 50+
50+ Countries Served
Join 4,000+ Companies Growing with Actowiz
From Zomato to Expedia — see why global leaders trust us with
their data.
Why Global Leaders Trust Actowiz
Backed by automation, data volume, and enterprise-grade scale — we help businesses from startups to
Fortune 500s extract competitive insights across the USA, UK, UAE, and beyond.

7+
Years of Experience
Proven track record delivering enterprise-grade web scraping and data intelligence
solutions.

4,000+
Projects Delivered
Serving startups to Fortune 500 companies across 50+ countries worldwide.

200+
In-House Experts
Dedicated engineers across scrapers, AI/ML models, APIs, and data quality assurance.

9.2M
Automated Workflows
Running weekly across eCommerce, Quick Commerce, Travel, Real Estate, and Food
industries.

270+ TB
Data Transferred
Real-time and batch data scraping at massive scale, across industries globally.

380M+
Pages Crawled Weekly
Scaled infrastructure for comprehensive global data coverage with 99% accuracy.
AI Solutions Engineered
for Your Needs
→
LLM-Powered Attribute Extraction: High-precision product matching
using large language models for accurate data classification.
→
Advanced Computer Vision: Fine-grained object detection for
precise product classification using text and image embeddings.
→
GPT-Based Analytics Layer: Natural language query-based reporting
and visualization for business intelligence.
→
Human-in-the-Loop AI: Continuous feedback loop to improve AI
model accuracy over time.
 Product Matching
Product Matching
 Attribute Tagging
Attribute Tagging
 Content Optimization
Content Optimization
 Sentiment Analysis
Sentiment Analysis
 Prompt-Based Reporting
Prompt-Based Reporting
Connect the Dots Across
Your Retail Ecosystem
We partner with agencies, system integrators, and technology platforms to deliver end-to-end solutions
across the retail and digital shelf ecosystem.

Analytics Services

Ad Tech

Price Optimization

Business Consulting

System Integration

Market Research
Become a Partner →
Latest Insights & Resources
View All Resources →
Blog
Salla Store Product Data Scraping: Prices, SKUs, Inventory & Seller Insights
Salla Store Product Data Scraping by Actowiz Solutions � extract SKU-level prices, inventory status, deals and seller performance data across Sallas merchant network.
Case Study
Real Estate Listing & Price Intelligence Across Portals
Monitor real estate listings, property prices, availability, and market trends across leading property portals. Gain real-time intelligence to benchmark competitors, optimize pricing, and identify investment opportunities.
Report
Saudi Arabia Quick Commerce Market Data Report 2026
KSA quick commerce mapped from public data — Nana, Rabbit, Jahez & HungerStation coverage zones, pricing & assortment across Saudi cities.
Start Where It Makes Sense for You
Whether you're a startup or a Fortune 500 — we have the right plan for your data needs.

Enterprise
Book a Strategy Call
Custom solutions, dedicated support, volume pricing for large-scale needs.

Growing Brand
Get Free Sample Data
Try before you buy — 500 rows of real data, delivered in 2 hours. No strings.

Just Exploring
View Plans & Pricing
Transparent plans from $500/mo. Find the right fit for your budget and scale.
Our perks are irreplaceable
Time Zone Flexibility
Benefit from the ease of collaboration with Actowiz
Solutions, as our team is aligned with your preferred time zone, ensuring smooth communication
and timely delivery.
Clear Communication
Our team focuses on clear, transparent communication
to ensure that every project is aligned with your goals and that you’re always informed of
progress.
Uncompromising Quality
Actowiz Solutions adheres to the highest global
standards of development, delivering exceptional solutions that consistently exceed industry
expectations
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming NEW
OTT & Streaming NEW
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing NEW
Dynamic Pricing / AI Repricing NEW
 Promotions & Deals Alerts NEW
Promotions & Deals Alerts NEW
 B2B / POI & Lead Data NEW
B2B / POI & Lead Data NEW
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries
































