Introduction
In today's competitive landscape, businesses increasingly use web scraping services to obtain valuable insights. However, the allure of cost-effective or complimentary web scraping services can be tempting. While cost-saving is a priority, it's imperative to recognize the multifaceted considerations beyond mere pricing. This blog delves into the legal, ethical, and strategic dimensions of web scraping projects, emphasizing the potential pitfalls of opting for a free web scraping service versus a paid one. Furthermore, we'll explore the role of Web Scraping APIs, the integration with Machine Learning, and the significance of robust data methodology in ensuring accurate and reliable data extraction.
Understanding Web Scraping: Its Purpose and Applications
Web scraping refers to fetching data from online platforms, acting as a sophisticated digital tool that automatically collects information from various web pages. Instead of tediously manually extracting data, web scraping leverages automated mechanisms to delve into a website's underlying HTML structure, retrieving desired elements like text, images, or hyperlinks. It streamlines the process of "harvesting" pertinent content from the vast web. This harvested data serves multiple purposes, for research endeavors, comparative pricing analysis, or establishing comprehensive databases.
While some websites facilitate data retrieval through user-friendly Web Scraping APIs, granting authorized users access to their content, others necessitate a more hands-on approach. In such scenarios, developers craft custom scripts using popular programming languages like Python, Java, or JavaScript to facilitate web scraping.
Furthermore, incorporating artificial intelligence (AI) and Machine Learning (ML) augments the efficiency of web scraping processes, refining the scraper's capability to discern and extract data with heightened precision. With this enriched data, businesses can drive data-driven decisions, researchers can unearth invaluable insights, and software developers can pioneer groundbreaking applications. Hence, web scraping emerges as an indispensable asset for harnessing and analyzing data across the digital realm.
Prioritizing Compliance: A Fundamental Approach
Before diving into the intricacies of web scraping, the foremost consideration should always be compliance, surpassing even financial considerations. Imagine compliance as the foundational framework guiding web scraping endeavors, ensuring operations remain ethical and lawful, like adhering to driving regulations on the road. It's an essential aspect that warrants unwavering attention.
Compliance acts as a protective shield, akin to exercising caution at a busy intersection; neglecting it could result in significant legal repercussions, including substantial fines and legal actions. Furthermore, compliance encompasses a respectful approach towards website proprietors and their digital domains, mirroring the respect accorded to physical assets. Forcing unauthorized entry into digital platforms isn't only impolite but also unlawful.
Securing explicit consent becomes paramount when web scraping activities encompass the extraction of personal data. Consider it analogous to seeking approval before capturing someone's image—it underscores respect and legality.
To navigate the complex landscape of web scraping with integrity and legality, adherence to two primary guidelines is indispensable:
Exercise prudence in web scraping endeavors, avoiding hasty actions that could precipitate legal challenges.
When engaging a web scraping service, gravitate towards providers exemplifying a staunch commitment to compliance, as they can adeptly navigate the maze of regulations governing web scraping activities.
In summation, compliance transcends being a mere elective; it is an indispensable pillar, ensuring web scraping initiatives' ethical and legal integrity.
Types of Web Scraping Solutions Explored: From DaaS to IaaS
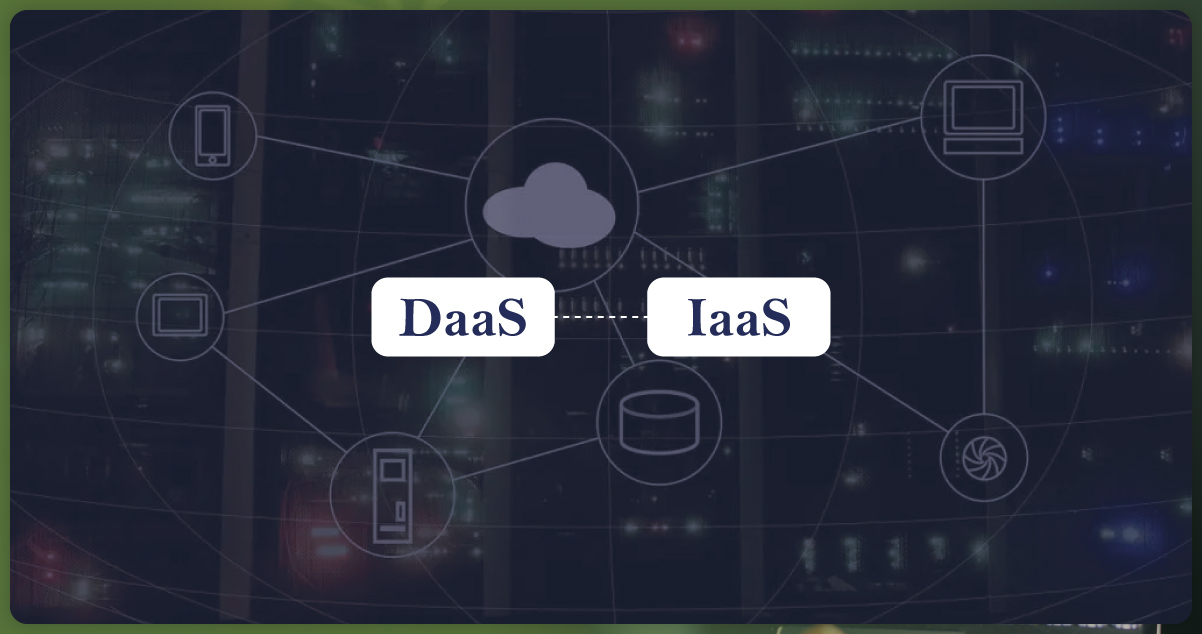
Data as a Service (DaaS)
DaaS encapsulates a comprehensive web scraping service where providers oversee the end-to-end process. They handle infrastructure components like servers, proxies, and specialized software, ensuring seamless data extraction from diverse web sources. Data is typically accessible via Web Scraping APIs, facilitating integration into various applications. While DaaS streamlines the scraping process, offering tailored solutions, it can limit direct control over the scraping methodology, which the service provider predetermines.
Self-Service Tools
Web scraping tools offer user-friendly interfaces tailored for data extraction, eliminating intricate coding requirements. Though cost-effective for smaller tasks, these tools might need help with scalability, especially for complex projects. Their adaptability to evolving website structures and handling unique scraping needs can also be limited. Nonetheless, they remain a viable option for those with basic technical proficiency.
Data APIs

Web scraping services sometimes extend APIs for structured data access from select websites. These APIs simplify data retrieval and integration processes, bypassing the complexities of HTML parsing. However, they may have limitations such as restricted availability, authentication requirements, and rate limits. While beneficial for structured data retrieval, their constraints necessitate strategic planning.
Infrastructure as a Service (IaaS)

IaaS offers a customizable solution, renting out infrastructure for tailored web scraping operations. It provides flexibility and scalability, ideal for extensive projects. However, leveraging IaaS demands a profound understanding of web scraping methodologies, including the intricacies of proxy management, CAPTCHA handling, and data methodology. The associated costs, dependent on resource utilization, require diligent oversight to avoid unexpected expenses.
Incorporating Machine Learning and advanced data methodologies can further refine these web scraping solutions, enhancing efficiency and accuracy. Whether opting for DaaS, self-service tools, Data APIs, or IaaS, understanding the nuances of each approach is crucial for successful web scraping endeavors.
Scope and Depth in Web Scraping
In web scraping, the term "coverage" encompasses multiple dimensions. At its core, coverage pertains to the spectrum of websites a web scraping service can navigate, encompassing intricate sites with multifaceted structures and those featuring dynamic content shifts.
Furthermore, coverage delves into the granularity of data retrieval. It's not merely about skimming the surface; it's about diving deep to capture intricate details. This includes nuances like comprehensive product specifications, nuanced user feedback, or data influenced by user inputs.
An exemplary web scraping service should exhibit versatility in data extraction, adeptly capturing a gamut of data formats—from textual content and imagery to multimedia elements, pricing matrices, and user testimonials. Beyond the breadth of content, geographic inclusivity is paramount. The capability to source data from diverse linguistic and regional contexts amplifies the service's adaptability, seamlessly aligning with varied business prerequisites.
The Significance of Coverage in Web Scraping

Coverage holds pivotal importance in web scraping for multiple compelling rationales. Firstly, it gives businesses a panoramic view, facilitating in-depth insights into target demographics, competitor strategies, and overarching industry trajectories. A web scraping solution boasting expansive coverage can harness data from various platforms, culminating in a comprehensive grasp of the operational landscape.
Moreover, coverage crystallizes into a tangible competitive edge. Businesses are primed with invaluable intelligence by accessing diverse data repositories, facilitating astute decision-making, and ensuring sustained competitiveness. This enriched data reservoir fosters a nuanced comprehension of market evolutions and developing trends, laying the groundwork for refined strategic formulations.
Lastly, coverage is intrinsically tied to data fidelity. Services underpinned by extensive coverage often manifest superior data integrity, adeptly navigating diverse website architectures and content formats. This adaptability minimizes discrepancies and ensures data robustness, culminating in an accurate and trustworthy repository underpinning informed strategic initiatives.
Navigating Service Delivery Terms in Web Scraping Solutions
When considering partnerships with web scraping service providers, delving into the nuances of their service delivery terms becomes imperative. Initiate your assessment by scrutinizing their subscription frameworks, which could span tiered structures or flexible pay-as-you-go arrangements. Align your choice with both your web scraping necessities and fiscal constraints.
Vigilance regarding data access thresholds is paramount to sidestep unforeseen costs or operational halts. Understanding data retention durations is crucial, especially if your objectives involve Machine Learning or require comprehensive historical datasets. Evaluate response time commitments, noting that expedited responses might entail incremental charges.
Familiarize yourself with the spectrum of data delivery mechanisms, whether diverse file formats or seamless Web Scraping API integrations, which are pivotal for modern data methodology applications. The cognizance of scraping frequency limitations is essential, and the paramount importance of data accuracy cannot be overstated. Inaccurate datasets can precipitate additional overheads in data rectification processes.
Providers might adopt varied pricing structures contingent on the intricacy of data extraction, emphasizing the need for clarity. Gauge the caliber of customer support and maintenance provisions, and immerse yourself in their cancellation and reimbursement protocols. Above all, ascertain the service's alignment with prevailing legal paradigms and ethical benchmarks in web scraping operations.
The Importance of Service Delivery Terms in Web Scraping Solutions
Grasping the intricacies of service delivery terms holds paramount significance for several reasons. Foremost, it serves as a cornerstone for effective risk mitigation, clarifying potential pitfalls associated with data access constraints, data fidelity, and adherence to legal frameworks.
Moreover, these terms underpin informed financial planning. By elucidating the pricing matrix, they empower businesses to craft meticulous budgets, preempting unforeseen financial discrepancies.
Furthermore, the stipulated service delivery terms are emblematic of the caliber of service on offer, encapsulating metrics such as data precision, support efficacy, and data retrieval velocity.
Lastly, these terms are instrumental in shaping the scalability quotient of your web scraping endeavors. They lay the groundwork for aligning your web scraping strategy with dynamic operational needs, rendering them an indispensable facet of strategic planning in the web scraping landscape.
Maintenance in Web Scraping: Ensuring Continuity and Compliance
Maintenance is a continuous endeavor in web scraping to ensure seamless and reliable data extraction. It entails a spectrum of activities, from periodic code revisions to accommodate evolving website architectures, adept proxy management to circumvent IP restrictions, and the establishment and upkeep of robust data storage solutions, including database optimization and data purification processes.
Furthermore, meticulous planning of scraping schedules, coupled with a steadfast commitment to staying abreast of legal compliance nuances in web scraping, is paramount. This proactive approach is complemented by vigilant oversight and adept error resolution mechanisms, ensuring timely mitigation of disruptions or anomalies encountered during the scraping journey. Maintenance is a linchpin, bolstering the efficacy and regulatory adherence of web scraping initiatives.
The Significance of Scraper Maintenance
The methodology adopted by a vendor in executing maintenance holds substantial weight. It is intrinsically linked to the consistency of data retrieval, guaranteeing that the data procured remains precise and up-to-date. Effective maintenance is a bulwark against disruptions, minimizing operational hiccups and ensuring a seamless data stream.
Moreover, adherence to legal stipulations is non-negotiable, with the vendor's maintenance protocols as a pivotal determinant. Beyond mere functionality, adept maintenance bolsters data integrity by rectifying discrepancies, purging redundancies, and structuring the acquired data methodically. This meticulous approach culminates in elevated data reliability, amplifying the intrinsic value of the gleaned insights.
Understanding Total Cost of Ownership (TCO) in Web Scraping
-in-Web-Scraping.jpg)
Total Cost of Ownership (TCO) is a pivotal metric for gauging the financial viability of web scraping initiatives. It encapsulates all associated costs, both direct and indirect, incurred throughout the lifecycle of web scraping operations.
Initiation costs form the foundational layer, encompassing expenditures for setting up the web scraping infrastructure. This phase includes investments in server configurations, software licenses, and the developmental outlay for crafting scraping scripts or applications.
After the initial setup, ongoing operational expenses come into play. This encompasses recurrent charges like cloud hosting tariffs, periodic server upkeep, and potential augmentations to cater to evolving scraping prerequisites. Notably, ancillary costs such as proxy services and CAPTCHA solutions, essential for circumventing web scraping challenges, should be integrated into the TCO framework.
Expenditures associated with software licenses, specialized scraping utilities, and continuous developmental and maintenance costs—encompassing script updates, bug rectifications, and adaptability to evolving website structures—are also integral components.
Furthermore, data management expenses tied to database hosting and costs for data cleansing utilities or services merit consideration. The fiscal outlay for ensuring legal conformity, from legal counsel fees to potential penalties for breaches, is a salient aspect of TCO. As operations scale, anticipating scalability-related expenses becomes imperative, emphasizing the need for proactive resource allocation.
Lastly, personnel-related costs, spanning remunerations for developers, data analysts, IT support personnel, and contingencies for risk mitigation—addressing challenges like IP restrictions, legal intricacies, or data accuracy issues—round off the TCO spectrum. Together, these facets provide a holistic perspective on the financial dimensions of web scraping initiatives.
The Significance of TCO in Web Scraping Operations
Total Cost of Ownership (TCO) is a pivotal metric for organizations navigating web scraping complexities. Its relevance manifests in multiple dimensions:
Informed Budgeting: TCO offers a panoramic perspective of all associated expenses, empowering businesses to craft meticulous budgets, thereby averting unforeseen financial challenges.
Cost-Benefit Evaluation: By juxtaposing the expenses against the accrued value from web scraping, TCO facilitates a nuanced cost-benefit analysis. This scrutiny illuminates whether the investment in web scraping aligns with the anticipated returns, aiding businesses in discerning the cost-effectiveness of their chosen web scraping solutions.
Strategic Resource Allocation: TCO is seminal in guiding resource distribution, especially in scenarios necessitating a delicate equilibrium between budgetary confines and expansive data requirements. This equilibrium is instrumental for the sustainable evolution of web scraping endeavors.
ROI Insights: At its core, TCO empowers organizations to gauge the Return on Investment (ROI) by juxtaposing the cumulative costs against the tangible benefits reaped from the harvested data. This comparative analysis is a barometer of the efficacy and potency of web scraping initiatives, steering organizations toward data-driven decision-making paradigms.
Drawbacks of Opting for Free Web Scraping Services
While the allure of free web scraping services is undeniable, it's essential to recognize the inherent limitations they present:
Limited Functionality: Free offerings often come with rudimentary scraping capabilities, making them less suitable for intricate or specialized data extraction endeavors. These platforms need to catch up for projects demanding sophisticated data collection.
Data Volume Restrictions: Many free services impose constraints on the volume of data that can be scraped in a single operation. Such limitations can impede large-scale data-gathering efforts, potentially hampering the efficiency and pace of your project.
Usage Limitations: Some free tools, although equipped with user-friendly interfaces, may impose caps on data extraction volumes or scraping frequencies. These constraints can curtail the scope and frequency of your scraping activities.
Opaque Pricing Models: The cost structure of free services can be ambiguous, with potential hidden charges lurking if you surpass predefined usage thresholds. This unpredictability can disrupt budgetary planning and inflate project costs unexpectedly.
Limited Support: The absence of robust customer support is a common drawback of free services. In the event of technical glitches or challenges during the extraction process, the lack of timely assistance can escalate operational hurdles.
While free web scraping services suffice for rudimentary tasks, weighing their constraints against the project's requirements and potential hidden expenses is imperative.
Is Web Scraping Permissible Under the Law?
Navigating web scraping requires a nuanced understanding of its legal implications. The legality of web scraping is multifaceted, primarily based on the methodologies employed and the nature of the data harvested. A prevalent application of web scraping lies in competitive analysis, enabling businesses to glean insights about market rivals to bolster strategic decision-making. However, extracting sensitive or confidential information, such as personal data, can potentially result in legal repercussions.
Furthermore, the ambiguity surrounding the legality of many free web scraping services necessitates a meticulous evaluation of data protection statutes and adherence to website-specific terms of service. The limited or absent customer support characteristic of numerous free platforms further exacerbates the challenges, particularly when navigating intricate legal or technical difficulties. Conversely, premium web scraping services typically proffer enhanced customer support mechanisms, catering mainly to marketing professionals reliant on data-driven insights. Moreover, the pricing frameworks of paid services are more transparent, mitigating the risk of unforeseen expenditures and fostering a more consistent user experience.
Anonymization in Web Scraping: A Critical Consideration
While free web scraping tools may offer basic functionalities, they often need to provide robust anonymization capabilities. Anonymization techniques in web scraping, such as IP rotations and proxy utilization, are instrumental in obscuring the scraper's identity during data extraction. However, implementing and maintaining these anonymizing measures entail substantial resources, particularly in curating a diverse network of rotating IP addresses and dependable proxies.
Given the resource-intensive nature of these anonymization methods, it's uncommon to encounter complimentary offerings in this domain. These anonymization safeguards are indispensable for ensuring the ethical integrity and operational efficacy of web scraping endeavors, reducing the risk of detection or blockages by targeted websites. For enterprises engaged in large-scale data extraction initiatives, incorporating robust anonymization mechanisms becomes not merely advisable but imperative.
Is Coding Essential for Effective Web Scraping?

While basic web scraping tasks can be accomplished using user-friendly tools, coding in web scraping must be considered, especially when precision and customizability are paramount. Coding proficiency empowers users to craft bespoke scripts tailored to specific data extraction requirements, facilitating enhanced control and efficiency in data handling processes.
For tasks involving intricate websites or when confronted with challenging scenarios, the capabilities conferred by coding expertise are invaluable. Furthermore, as web scraping continues to intersect with advanced domains like Machine Learning and sophisticated data methodologies, the ability to code becomes increasingly indispensable.
While certain web scraping services and Web Scraping APIs offer streamlined solutions for rudimentary tasks, a foundational understanding of coding equips individuals and enterprises alike with the agility and adaptability needed to navigate the evolving landscape of web scraping effectively.
Conclusion
In concluding the pivotal aspects of web scraping for enterprises, it's paramount to recognize that the allure of budget-friendly solutions may only sometimes translate to long-term cost efficiency. Prioritizing legal adherence, ethical integrity, and honoring the proprietary rights of data originators is foundational to any robust web scraping strategy.
The selection of an optimal approach—whether through specialized web scraping services, self-service platforms, Web Scraping APIs, or Infrastructure as a Service (IaaS)—should be informed by a meticulous assessment of your organizational requirements and the inherent benefits each modality offers. A comprehensive grasp of service delivery nuances, consistent maintenance protocols, and the overarching Total Cost of Ownership (TCO) is imperative. This encompasses the initial financial commitment and the sustained implications of your chosen web scraping methodology, especially as it intersects with advanced domains like Machine Learning and evolving data methodologies.
For enterprises aiming to capitalize on web scraping's transformative potential, striking a synergistic equilibrium between financial prudence, regulatory compliance, and operational longevity is indispensable. By conscientiously factoring in these elements, organizations can harness web scraping services to propel data-driven insights, fortify strategic initiatives, and navigate the contemporary business landscape with acumen.
Discover Actowiz Solutions' cutting-edge web scraping services, meticulously designed to align with regulatory frameworks, uphold ethical standards, and deliver unparalleled data quality. Engage with Actowiz Solutions today and journey towards astute, data-driven decision-making excellence. You can also reach us for all your mobile app scraping, instant data scraper and web scraping service requirements.
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming NEW
OTT & Streaming NEW
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing NEW
Dynamic Pricing / AI Repricing NEW
 Promotions & Deals Alerts NEW
Promotions & Deals Alerts NEW
 B2B / POI & Lead Data NEW
B2B / POI & Lead Data NEW
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries















































