
Automating web scraping has become increasingly important in today's data-driven world, allowing businesses and individuals to gather information from various online sources efficiently. However, for beginners, web scraping can often be a daunting task. Fortunately, with the help of language models like ChatGPT, the learning curve for web scraping has been significantly reduced.
ChatGPT, the popular language model, is a valuable resource for beginners, providing guidance and support as they navigate the web scraping process. With ChatGPT, beginners can efficiently and effectively scrape data from websites, enabling them to gain valuable insights to inform their decision-making processes. Additionally, experienced individuals can leverage ChatGPT to enhance productivity and efficiently complete tasks.
Using ChatGPT, beginners can ask specific questions about web scraping, such as how to extract data from a particular website, which tools and technologies to utilize, and how to clean and analyze the collected data. ChatGPT responds with detailed and user-friendly explanations, enabling beginners to learn and apply web scraping techniques quickly. This helps build their knowledge and confidence, leading to more accurate and efficient data acquisition.
In this blog post, we will delve into the art of asking precise questions to learn scraping coding with the assistance of ChatGPT quickly. As an illustrative example, we will demonstrate how to scrape the Amazon website using ChatGPT. Following along, readers can gain practical insights and develop the skills to automate web scraping tasks effectively.
Steps Associated with Web Scraping
Web scraping involves several steps that need to be followed to extract data from websites effectively. Let's outline the steps involved:
Identify the target website: Determine the website from which you want to scrape data.
Choose a web scraping tool: Select a suitable tool or library that fits your requirements. Popular options include BeautifulSoup, Scrapy, Selenium, and Playwright.
Inspect the website: Use your web browser's developer tools to inspect the website's HTML and CSS code. Understand the structure of the website and how the data is presented.
Build a web scraper: Develop a script or program using your chosen web scraping tool to extract the desired data. Set up your development environment accordingly.
Fetch the HTML content: Write a function to send a request to the target website and retrieve the HTML content of the desired web page. Handle possible scenarios like timeouts and error handling.
Parse the HTML content: Use a parsing library from your web scraping framework to extract specific data attributes from the HTML content.
Handle pagination: If the data is spread across multiple pages, implement logic to handle pagination or interaction requirements such as clicking buttons or submitting forms.
Handle anti-scraping measures: Some websites employ anti-scraping techniques to prevent web scraping. You should implement strategies like rotating proxies and user mediators or presenting delays between the requests to disable these procedures.
Test a scraper: Run a web scraper on the smaller data subset to make sure it scrapes the desired information correctly. Debug and make necessary adjustments if any issues arise.
Run the scraper on a production server: Once the web scraper is tested, deploy it on a production server or environment for regular or automated scraping.
Store the data: Save the extracted data in a database or export it to a suitable format such as CSV or JSON.
Clean and process the data: Depending on your use case, you may need to clean and preprocess the data before further analysis or usage.
Monitor the website: If you plan to scrape the website regularly, set up a monitoring system to detect any changes in the website's structure or content.
Respect website policies: Adhere to the website's terms of service and data policies. Avoid overloading the website with requests and refrain from scraping sensitive or personal information.
Following these steps, you can effectively automate web scraping and extract valuable data from websites.
Web scraping is an automated process of extracting data from websites. It typically involves fetching the HTML content of a web page and then parsing and extracting the relevant information for further analysis or storage. However, the techniques and approaches used in web scraping can vary significantly depending on the type of website being scraped. Understanding the different types of websites based on their characteristics and behavior is essential before embarking on a web scraping project.
There are several types of websites that you may encounter when scraping:
Static Websites: These websites have fixed content that stays mostly the same. The HTML structure remains the same each time you visit the site. Scraping data from static websites is generally straightforward since the structure and location of the desired information are consistent.
Dynamic Websites: Dynamic websites produce content using AJAX, JavaScript, or other client-side technologies. The content on these websites might change depending on data retrieved or user interactions from external resources. Scraping data from dynamic websites requires additional techniques to handle the dynamic nature of the content.
Websites having JavaScript Rendering: Some websites severely depend on JavaScript for rendering content dynamically. The data might be asynchronously loaded, and an HTML structure might undergo changes after the initial page load. Scraping data from these websites often requires using tools that can execute JavaScript, such as Selenium or Playwright, to retrieve the fully rendered content.
Websites with Captchas or IP Blocking: Certain websites use Captchas or blocking IP addresses to stop automated scraping. Overcoming these obstacles often requires specialized techniques and may be best handled by professional web scraping services.
Websites with Login/Authentication: Some websites require user login or authentication to access specific data. Scraping data from these websites typically involves employing proper authentication techniques to access and scrape the desired content.
Websites having Pagination: Websites that show data across different pages, often using infinite scrolling and pagination links, require special handling to navigate and scrape content from multiple pages. Tools like Scrapy are well-suited for handling pagination and efficiently scraping data from such websites.
Choosing the appropriate web scraping techniques and tools depends on the characteristics and behavior of the target website. For static websites, libraries like BeautifulSoup provide efficient parsing and extraction capabilities. Tools like Selenium or Playwright, which can handle JavaScript rendering, are more suitable for dynamic websites. Scrapy is a robust framework for handling pagination and scraping data from websites with multiple pages.
Considering these characteristics and behaviors is crucial when selecting the right tools and techniques for your web scraping project. By understanding the type of website you are dealing with, you can choose the most effective approach to extract the desired data accurately and efficiently.
Static websites are those that have fixed content, and the HTML structure remains the same each time you visit the site. These websites are relatively straightforward to scrape, as the data extraction process can be achieved by using libraries like BeautifulSoup, a popular Python library for parsing and navigating HTML/XML documents. BeautifulSoup offers efficient parsing capabilities, making it well-suited for extracting data from static websites.
In contrast, dynamic websites present a more complex challenge for web scraping due to their reliance on technologies like JavaScript and AJAX. This dynamic nature of the content means that the data retrieval process becomes more intricate. Unlike static websites, where the HTML structure remains constant, dynamic websites may alter their content in real-time based on user interactions or data fetched from external sources.
To tackle the task of scraping dynamic websites effectively, specialized tools like Selenium come into play. Selenium is a powerful web automation framework that empowers you to control web browsers programmatically. Its main advantage lies in its ability to interact with dynamic elements on a web page, simulate user actions like clicking buttons or filling out forms, and retrieve the HTML content after JavaScript has executed and the page has fully loaded. This versatility makes Selenium a great option for extracting dynamic websites whereas conventional parsing libraries including BeautifulSoup might fail.
By utilizing Selenium, you can automate the process of navigating through a dynamic website and extract the desired information. Since Selenium allows you to control a web browser, you can trigger the execution of JavaScript, which in turn generates the dynamic content you wish to scrape. Once the page is fully loaded, you can access the updated HTML and extract the required data.
One of Selenium's notable strengths is its interaction with dynamic elements. For instance, if a website displays additional content when a "Load More" button is clicked or when scrolling to the bottom of the page, Selenium enables you to simulate these actions programmatically. This capability ensures that you can access and retrieve all the data available on the website, even if it is loaded dynamically.
Additionally, Selenium supports various web browsers, such as Chrome, Firefox, and Safari, allowing you to choose the browser that best fits your needs. Moreover, it offers functionalities for handling cookies, managing sessions, and dealing with authentication requirements, making it suitable for scraping websites that require login or authentication.
It is important to keep in mind that while Selenium is highly effective for scraping dynamic websites, it can be slower compared to parsing libraries like BeautifulSoup. This is due to the additional overhead of automating a web browser. Therefore, it is advisable to use Selenium selectively and consider other alternatives for simpler scraping tasks or when the dynamic aspects of a website can be bypassed.
When dealing with dynamic websites that generate content using JavaScript and AJAX, Selenium emerges as a reliable a
For more complex scenarios, websites with JavaScript rendering, Playwright can be considered. Playwright is a powerful automation library that provides a unified API to influence different web browsers, like Firefox, Chromium, and WebKit. It offers advanced capabilities to interact with dynamic web pages and can be used for complex scraping tasks.
When dealing with websites that implementing Captchas or blocking IP addresses for preventing automated scraping, overcoming these obstacles requires specialized techniques. In such cases, approaching a professional web scraping company may be necessary, as these challenges are beyond the capabilities of regular web scraping tools.
Websites with login/authentication systems present another challenge as they require proper authentication techniques to access and scrape the desired content. Depending on the specific requirements, you might need to use techniques like sending login credentials or handling authentication tokens to access the data.
For websites that show data across different pages, pagination handling is crucial. These websites typically use pagination links and infinite scrolling to navigate through and access content from various pages. Tools like Scrapy, a powerful and flexible web scraping framework, are well-suited for handling pagination and efficiently scraping data from multiple pages.
In the context of e-commerce websites like Amazon, there are various product details such as titles, images, ratings, and prices that can be scraped from product pages. However, Amazon is a dynamic website that heavily relies on JavaScript rendering to display content, so using tools like Selenium or Playwright would be more appropriate for this task.
Choosing the right web scraping technique and tools depends on the specific characteristics and behaviors of the target website. For static websites, BeautifulSoup is an efficient choice, while dynamic websites may require Selenium or Playwright. Scrapy is suitable for handling pagination, and in more complex scenarios, considering professional web scraping services may be necessary. Proper consideration of these factors will help you extract the desired data effectively and efficiently from your target website.
How to Scrape Amazon Website Using Chat GPT?
When scraping the Amazon website, the initial step is to extract the product URLs from a webpage. To achieve this, you need to identify the HTML element on the page that corresponds to the desired product URL. You can inspect the webpage's structure by right-clicking on any component of interest and selecting the "Inspect" option from the context menu. This will open the browser's developer tools, allowing you to analyze the HTML code and locate the necessary data for web scraping.
By inspecting the webpage's HTML code, you can identify the specific elements that contain the product URLs. Look for HTML tags, classes, or IDs associated with the product links. These elements may vary depending on the webpage's structure, so it's crucial to understand the specific layout of the Amazon webpage you are targeting.
Once you have identified the relevant HTML element, you can use web scraping libraries like BeautifulSoup or Scrapy to extract the product URLs programmatically. These libraries provide convenient methods for parsing HTML and navigating through the document structure. With the identified element, you can extract the URLs and store them for further processing.
For example, using BeautifulSoup, you can locate the desired HTML element using its associated tag, class, or ID. Then, you can extract the URLs by iterating over the matched elements and accessing the appropriate attribute.
To generate the code for scraping Amazon product URLs using Beautiful Soup, you can follow these steps:

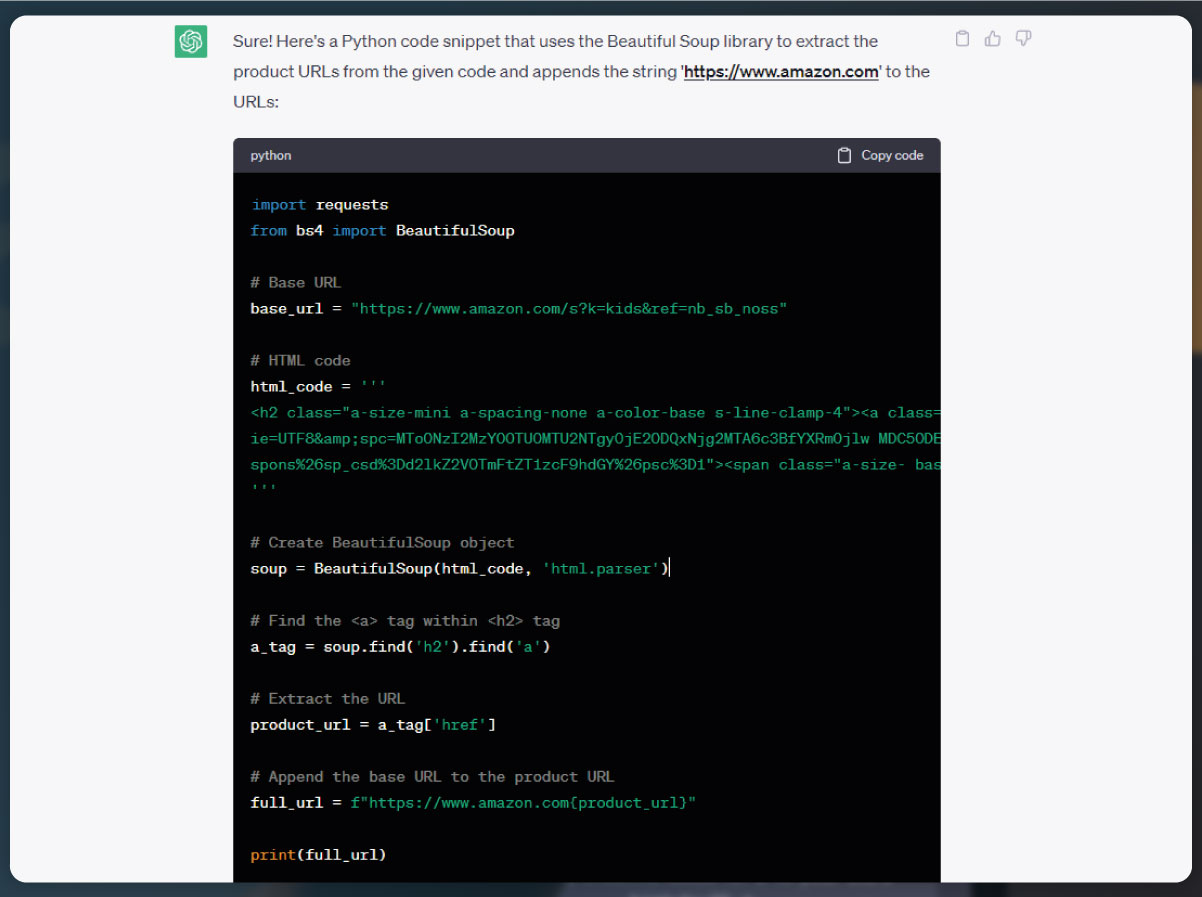
In this code, we import the necessary libraries, including requests for sending HTTP requests and BeautifulSoup for parsing HTML. We set the base URL to the Amazon India search page for toys for kids and send a GET request to retrieve the HTML content.
Using BeautifulSoup, we create a BeautifulSoup object from the response content. We then search for all elements with the classes "a-link-normal" and "a-text-normal" which typically contain the product URLs. We iterate over these elements, extract the "href" attribute, and form the complete URL by appending it to the base URL. The extracted URLs are stored in the product_urls list.
Finally, we print the extracted product URLs for verification.

After sending the request and storing the response in the response variable, we create a BeautifulSoup object from the response content using the HTML parser.
To locate the URL elements, we generate a CSS selector that targets the specific anchor elements () that contain the URLs of the products. We then use the find_all method of BeautifulSoup to find all elements matching the CSS selector.
We initiate an empty list called product_urls to store the extracted URLs. Using a for loop, we iterate through each element in product_links. For each element, we extract the href attribute using the get method of BeautifulSoup. If a valid href is found, we append the base URL to it, forming the complete URL of the product. The complete URL is then added to the product_urls list.
Finally, we print the list of extracted product URLs for verification.
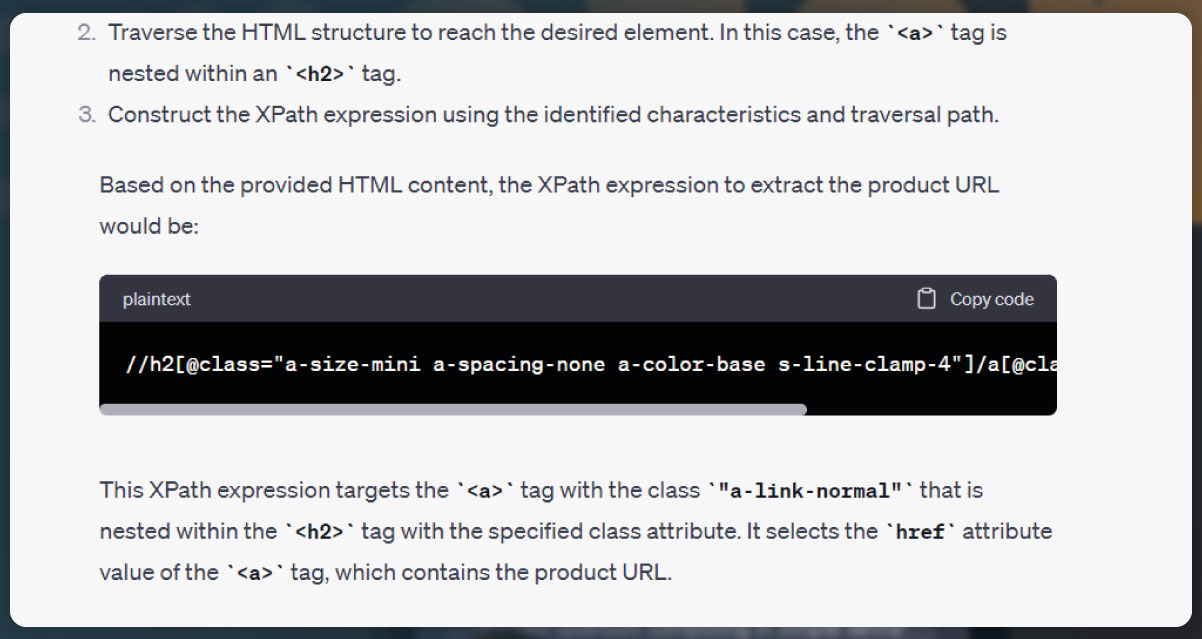
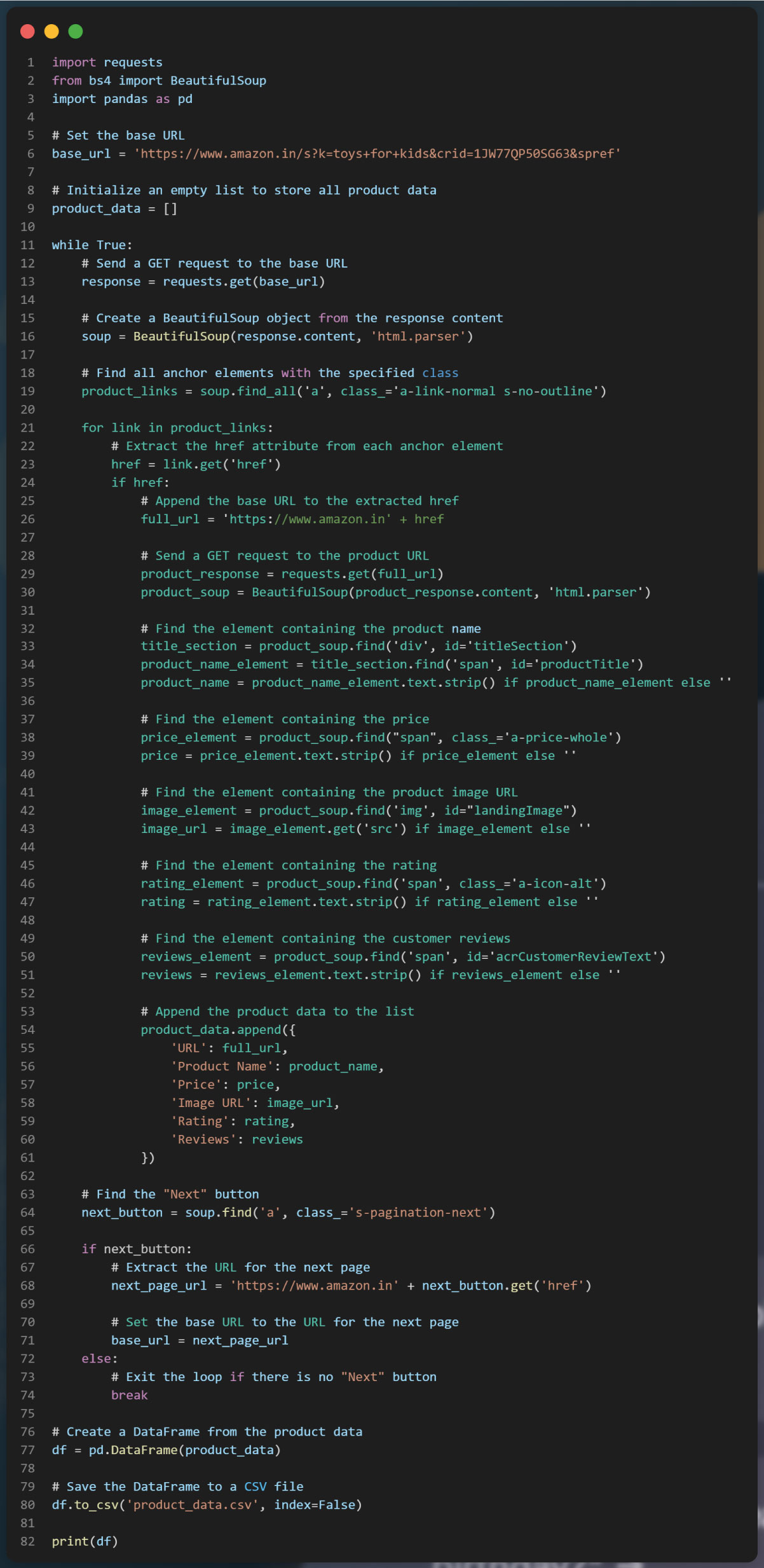
In this web scraping task, we aim to extract data from individual product description pages, and we need to handle pagination to navigate through multiple pages. To do this, we will inspect the next button on each page and copy its content to prompt ChatGPT.
We define a function scrape_product_data that takes a product description page URL as input and uses BeautifulSoup to extract data such as product title, price, and ratings. You can modify this function and add additional code to extract other relevant data based on your specific requirements
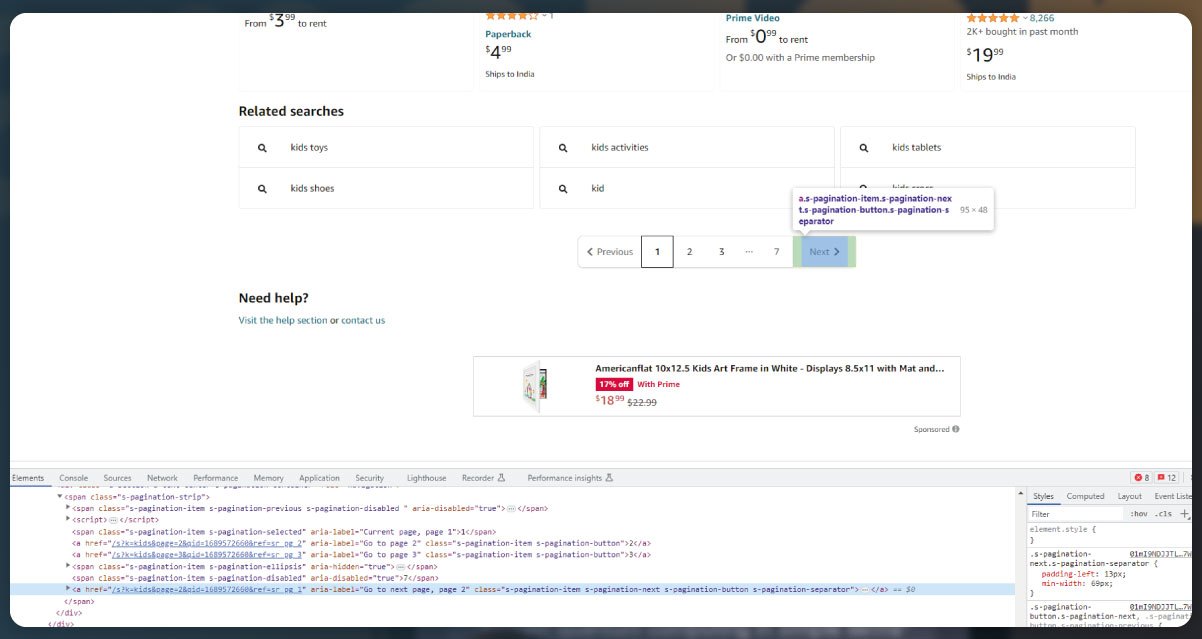
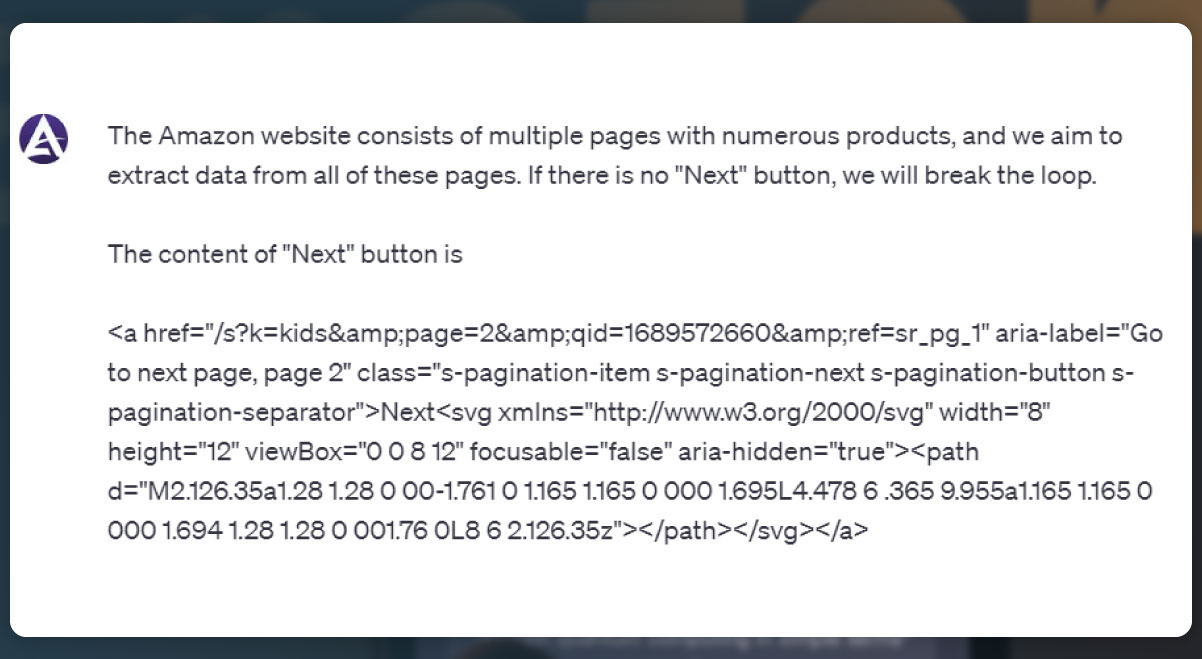
After scraping data from the individual product description pages, the next step is to handle pagination. The provided code demonstrates how to extract the URLs of products from the search page. To handle pagination, you will need to find the "next" button element and extract the URL to the next page. You can then continue scraping data from each page until there is no "next" button available
You can achieve pagination handling using a while loop or any other suitable method.
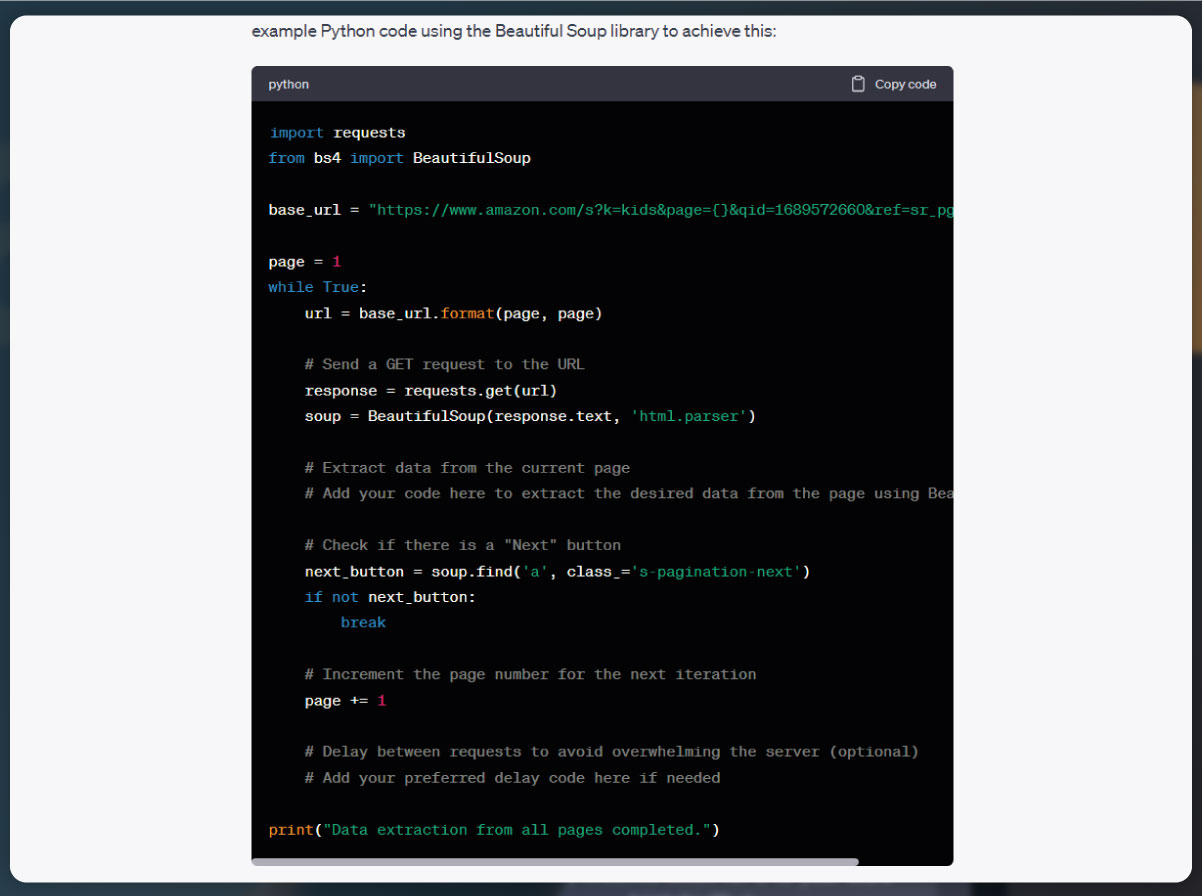
To scrape product names from the Amazon product pages, we can modify the existing code to include the necessary steps.
We have updated the scrape_product_data function to extract the product name from the product description page. We use BeautifulSoup's find method to locate the element containing the product name. In this case, we are using the "span" tag with the id attribute set to "productTitle" to identify the product name element. The extracted product name is then returned by the function.
Within the main code, after obtaining the product URLs from the search page, we iterate through each URL and call the scrape_product_data function to extract the product name. The extracted product name is printed for each product.
You can modify this code further to scrape additional information from the product pages by locating the appropriate elements using BeautifulSoup's methods.
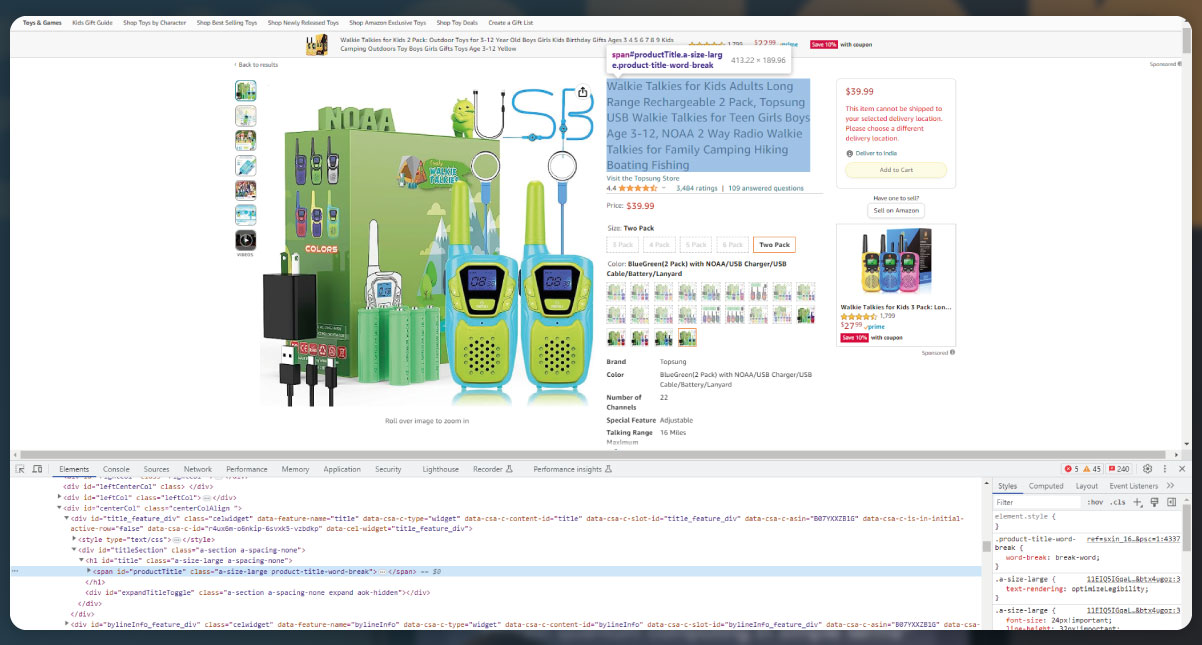
Usually, we study product names as well as copy content of the product names.

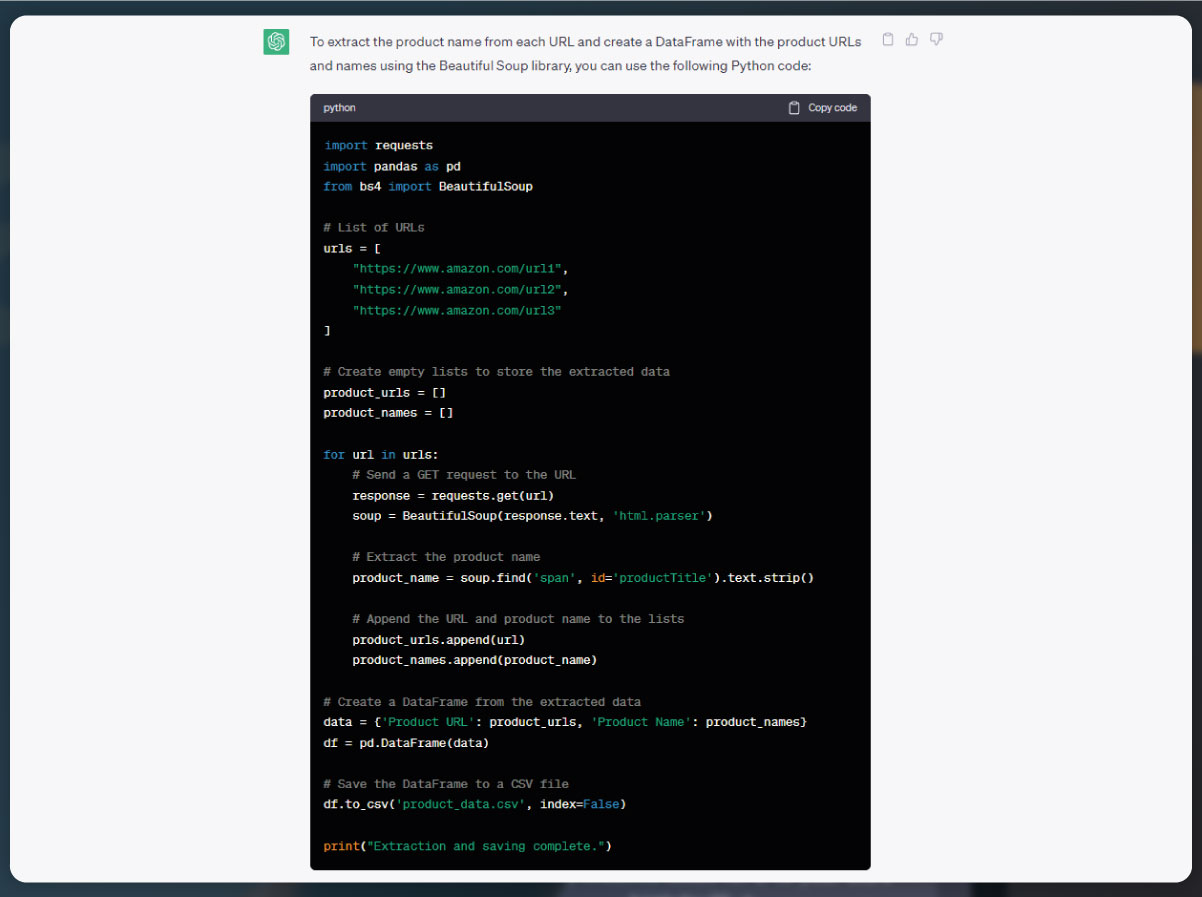
In this code snippet, we have added a product_data list to store the extracted product URLs and names. After scraping each product URL and name, they are appended to the product_data list as a dictionary. Once the scraping process is complete, a DataFrame is created from the product_data list using the Pandas library. The DataFrame organizes the product URLs and names into separate columns. Finally, the DataFrame is saved in the CSV file named "product_data.csv" using the to_csv() method.
We have modified the scrape_product_data function to also extract the product price from the product description page. The product price is extracted using a CSS selector or any other method that is appropriate for the specific Amazon product page structure. The price is then added to the product_data list along with the product URL and name. The resulting DataFrame now includes columns for the product URL, name, and price. The data is then saved into the CSV file called "product_data.csv" using the to_csv() method.
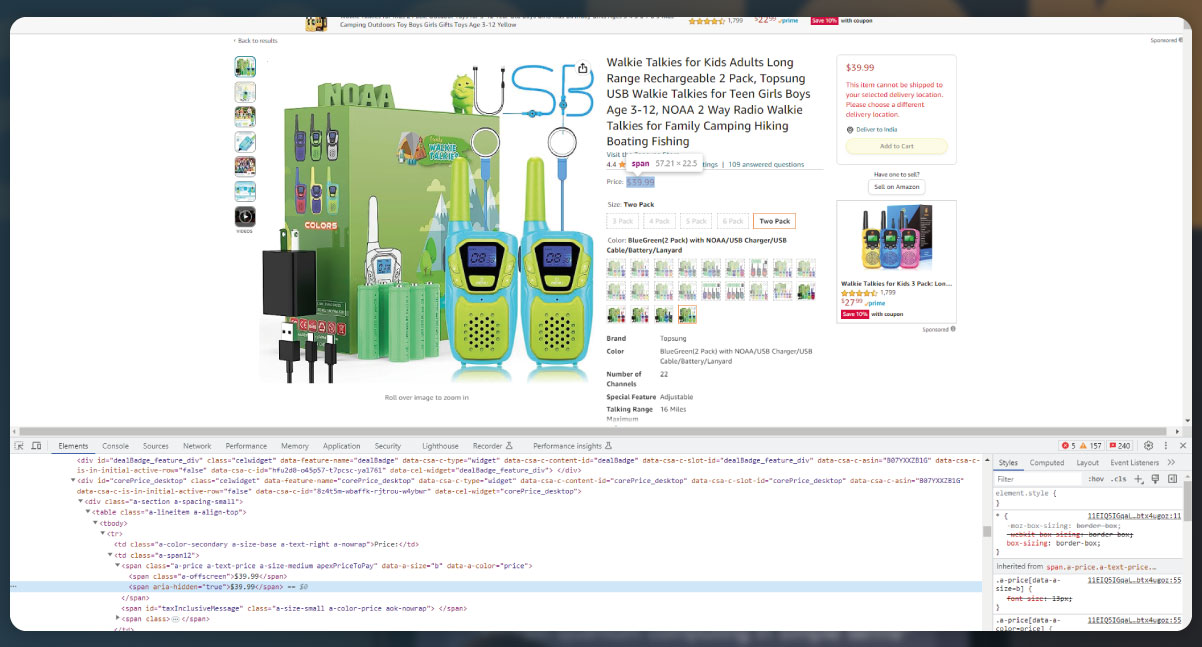

Additionally, we can scrape other product information such as ratings, number of reviews, product images, and more. The process involves inspecting the corresponding elements on the product page and extracting the desired data using BeautifulSoup or other suitable methods. By locating and parsing the relevant HTML elements, we can scrape and include these additional details in our web scraping process.
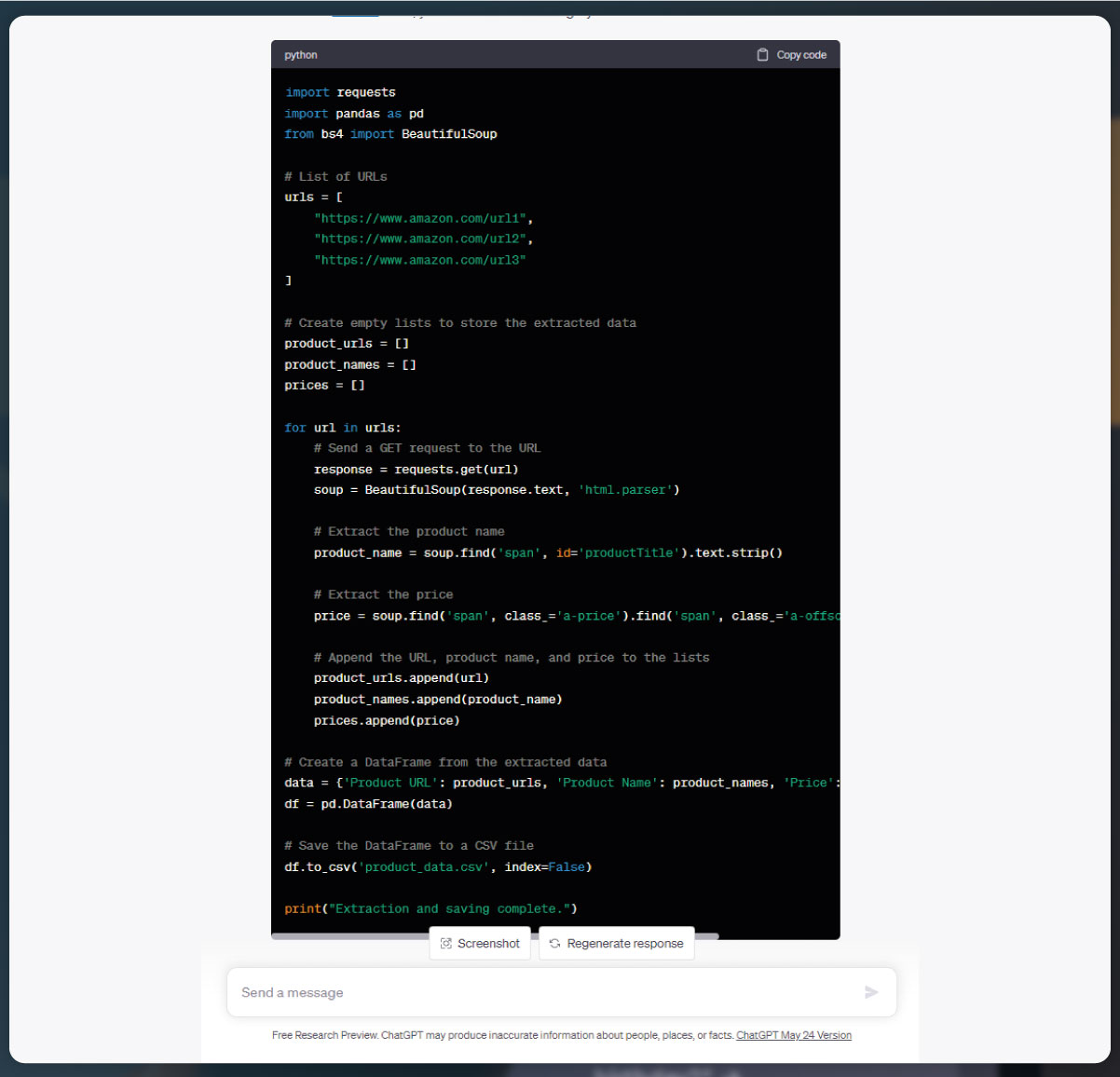
Ratings:
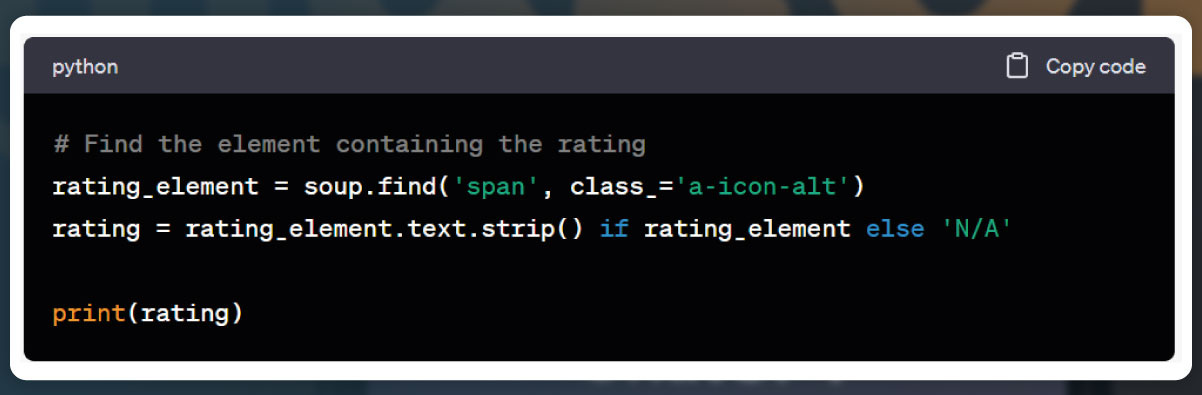
Total Reviews:
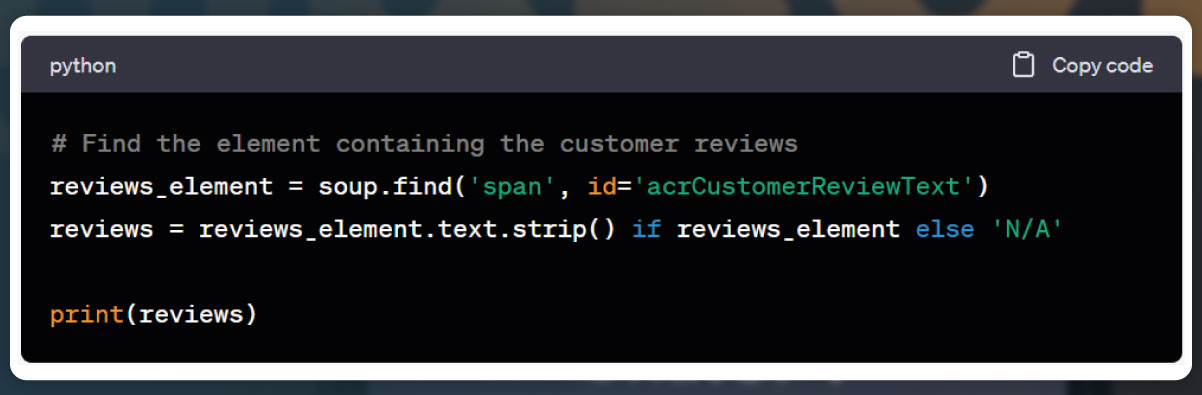
Image:
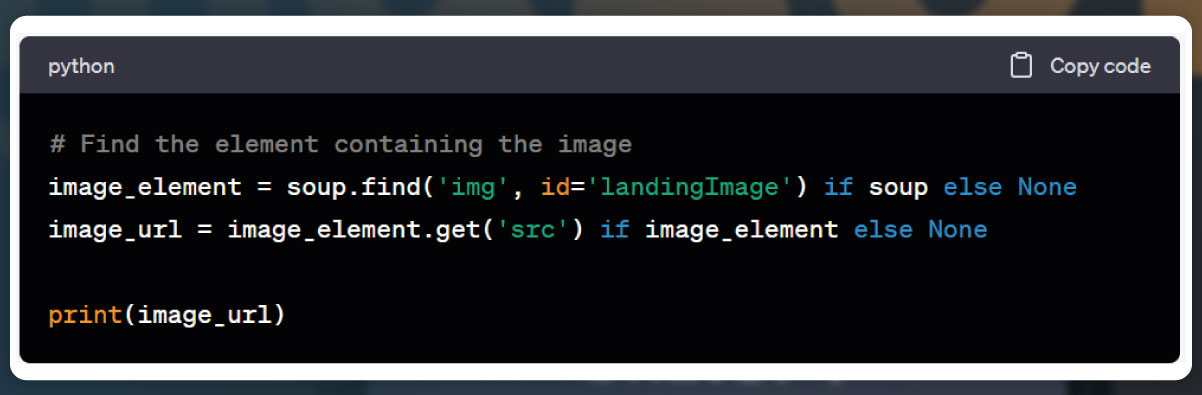
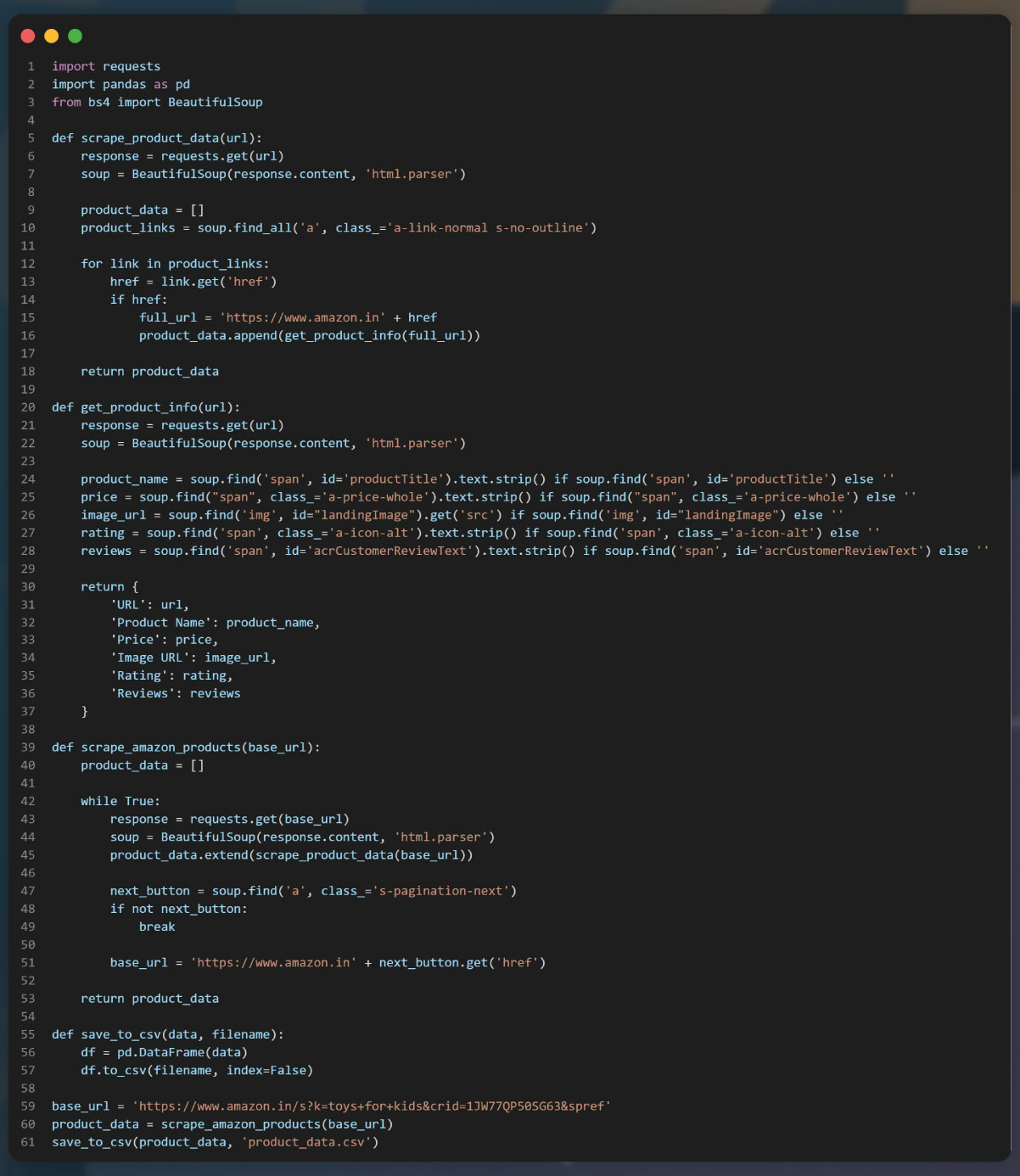
To improve the code's readability, maintainability, and competence without altering external behavior, we can apply standard coding practices. This includes using appropriate variable names, organizing the code into functions or classes, adding comments to explain the code's functionality, and optimizing the code structure and logic where possible. These improvements make the code easier to understand, modify, and optimize in the future.
Challenges of Utilizing ChatGPT for Web Scraping
While ChatGPT can be a useful tool for various natural language processing tasks, it does have some limitations when it comes to web scraping. Here are a few limitations to consider:
Lack of web-specific functionality: ChatGPT is primarily designed as a language model and does not have built-in capabilities for directly interacting with web pages. Web scraping often requires parsing HTML, interacting with APIs, handling cookies, and managing sessions, which are not directly supported by ChatGPT.
Limited access to web resources: ChatGPT operates as a standalone language model and does not have inherent access to the internet or external resources. It doesn't have the ability to send HTTP requests or download web pages, which are crucial for web scraping.
Difficulty in handling dynamic websites: Many modern websites use dynamic content loaded through JavaScript and AJAX requests. ChatGPT lacks the ability to execute JavaScript or interact with the rendered page, making it challenging to scrape such websites effectively.
Inability to handle CAPTCHAs: Some websites implement CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) to prevent automated scraping. Since ChatGPT does not have the ability to solve CAPTCHAs, it cannot bypass this security measure.
Compliance with website terms of service: Web scraping must be conducted in compliance with the terms of service of the targeted websites. ChatGPT may not have the ability to understand and adhere to these terms, potentially leading to ethical or legal issues.
No control over rate limiting: Many websites impose rate limits to prevent excessive traffic or scraping activity. ChatGPT lacks the ability to manage requests and throttle the scraping process, making it more prone to triggering rate limits and being blocked.
To overcome these limitations, it is advisable to use specialized web scraping tools or libraries, such as BeautifulSoup, Scrapy, or Selenium, which offer more control and functionality specifically tailored for web scraping tasks.
Considerations When Using ChatGPT for Web Scraping
While ChatGPT can generate basic web scraping code, it may not meet the requirements for production-level usage. To address the limitations, it is important to treat the generated code as a starting point, thoroughly review and modify it as needed. Additional research and expertise should be utilized to enhance the code and align it with best practices and current web technologies.
Furthermore, it is essential to be aware of legal and ethical considerations when engaging in web scraping activities. Adhering to website terms of service and respecting data privacy are crucial aspects to consider.
For beginners or one-time copy projects, ChatGPT can be a suitable option to learn web scraping. However, if you require regular data extraction or prefer to save time on coding, it is advisable to consult professional web scraping companies like Actowiz Solutions, which specialize in web scraping and can provide tailored solutions to meet your specific needs.
Conclusion
Web scraping has become a crucial skill for data gathering, but it can be daunting for beginners. Thankfully, LLM-based tools including ChatGPT have made scraping more beginner-friendly and accessible. ChatGPT serves as a helpful guide, offering detailed explanations and support to assist beginners in effectively scraping data from websites.
By following the steps outlined in ChatGPT and utilizing suitable tools like Selenium, BeautifulSoup, or Playwright, beginners can gain confidence in web scraping and make informed decisions. ChatGPT helps build knowledge and provides guidance on best practices, enabling beginners to extract data efficiently.
While it's important to acknowledge the limitations of ChatGPT in web scraping, such as lack of web-specific functionality and handling dynamic websites, it still serves as a valuable resource for both beginners and experienced users. Beginners can leverage ChatGPT to kickstart their web scraping journey and develop a solid foundation.
If you require reliable web scraping services to meet your data needs, consider reaching out to Actowiz Solutions. Their expertise in web scraping can provide tailored solutions to fulfill your specific requirements. For all your web scraping needs, mobile app scraping, or instant data scraper services, don't hesitate to contact us. We offer reliable solutions and expertise in extracting data from various sources. Whether you require a one-time extraction or regular data updates, our team at Actowiz Solutions is here to assist you. Reach out to us today to discuss your specific requirements and benefit from our professional web scraping services.
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming NEW
OTT & Streaming NEW
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing NEW
Dynamic Pricing / AI Repricing NEW
 Promotions & Deals Alerts NEW
Promotions & Deals Alerts NEW
 B2B / POI & Lead Data NEW
B2B / POI & Lead Data NEW
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries














































