
Let's understand you wish to extract the top 10 links which highlight
whenever you search everything on YouTube. Simultaneously you also
need to scrape the full 50 comments for all top 10 links and do sentiment
analysis about the extracted data. Indeed, you don't need to do that
manually.
Then how will you do it?
Here are some steps you can follow to do that.
Data Collection: It's easy to use Selenium for scrapping data from
YouTube. Please notice that comments are recursive by nature. When we
say recursive, that means people could comment on the top of
comments. You also have to choose which data points are mandatory for
the analysis. Here are some details that you can scrape for the top 10
video lists:
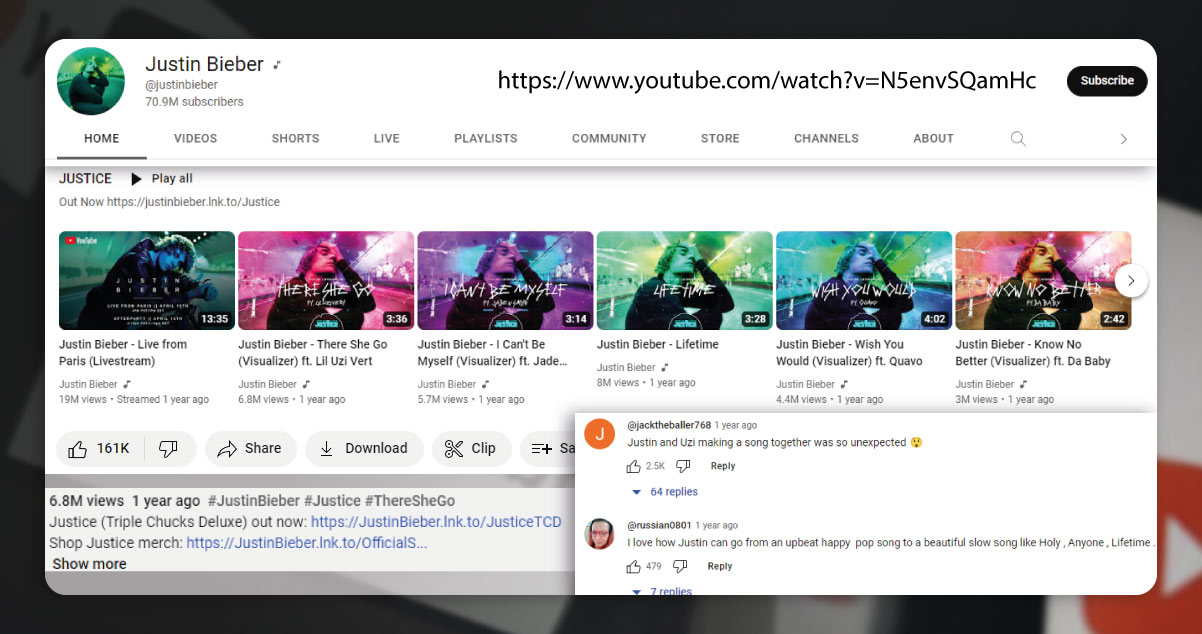
- Date Links Posted
- Subscription
Channel
- Total Views
- Video Title Text
- Video URL
2. Data Cleanup: This uses ample time as people could comment in all
languages, use sarcasm, smiley, etc. There are a lot of Python libraries
that can assist you in cleaning up data. Progress and explore more on
that.
3. Sentiment Analysis: When you have clean data, then you could do
NLP, sentiment analysis, and visualization on top of that.
Here are the steps for having code.
Step 1: Importing all the necessary libraries

Step 2: Opening file for writing data scraped from YouTube
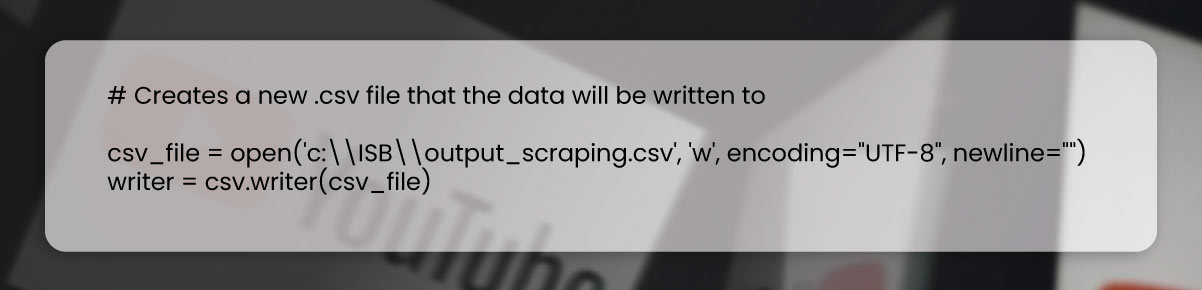
Step 3: Writing data column headers in opened CSV file
Step 4: Invoking webdriver and launch the YouTube website.
Step 5: Use the driver and dynamically search keywords like those given
in the example below; we have searched 'Kishore Kumar' and waited for
a few seconds to provide time to browser for loading the page
Step 6: For every top 10 link, scrape the elements given here and save
that in the respective list

Step 7: Launching URL for the top ten scraped links. For every URL -
scroll down to the essential position for loading the comments section -
sort by full Comments -scrolling down two times to load a minimum of
50 comments - for every comment(>=50), scrape elements here and put
them with try-catch block for handling exclusion if particular features
are not available for comments • Author name • Comment text •
comment posted Date • upvotes/downvotes • Total Views
Step 8: Create a dictionary for scraped elements from key and child links
and write in the opened CSV file.

Here, you will get an output console.
And here is a sample extracted output in a CSV file.

When you get data in a CSV file, you can make more analysis with
different Python libraries.
Selenium is a well-known library to scrape data using Python. Proceed
and play with the library to scrape data from different websites.
However, before that, verify if it is allowed to extract data from the
website. We believe you can utilize web scraping to learn objectives but
not for good use cases.
Feel free to contact Actowiz Solutions if you have any queries. You can
also reach us for your mobile app scraping and web scraping services
requirements.






