Introduction
In the age of e-commerce dominance, Amazon stands as a retail giant, offering a vast marketplace for both buyers and sellers. As businesses and individuals seek to gain a competitive edge on the platform, some turn to web scraping as a means of extracting valuable data. However, the practice of Amazon web scraping isn't without controversy, raising questions about its legality and ethics.
This article delves into the complex world of Amazon web scraping, shedding light on the illegal and unethical dimensions often accompanying this practice. While web scraping is not inherently illegal, it can cross legal boundaries when used to harvest sensitive data without consent or violating Amazon's terms of service.
We will explore the potential harm caused by unethical scraping, including the infringement of intellectual property rights, the disruption of fair competition, and the compromise of user privacy. Understanding these issues is crucial for individuals and businesses looking to engage in data extraction activities on Amazon's platform.
Join us as we navigate the maze of Amazon web scraping, unveiling the legal and ethical concerns that should be considered before embarking on such endeavors and how they may impact your business and online presence.
The Dark Side of Amazon Scraping: Understanding Illicit and Unethical Practices

Illegal and unethical use cases of Amazon scraping can have far-reaching consequences, not only for those who engage in such activities but also for the broader Amazon ecosystem and its users. It's essential to be aware of these practices to avoid legal troubles and maintain ethical conduct in the digital marketplace. Below, we'll explore these illegal and unethical use cases in more detail:
Price Manipulation

Some individuals or businesses scrape Amazon's product prices with the intent of manipulating prices, either on their listings or on other e-commerce platforms. This unethical practice can disrupt fair competition and deceive consumers. In many jurisdictions, such price-fixing is illegal and can lead to antitrust violations and substantial fines.
Unauthorized Data Extraction
Scraping sensitive data, such as customer information, product details, or sales data, without proper consent is illegal and unethical. It may violate privacy regulations, such as the General Data Protection Regulation (GDPR) and Amazon's terms of service. Unauthorized data extraction compromises the privacy and security of Amazon's users, potentially resulting in legal action and account suspension.
Review Manipulation

Some individuals scrape to manipulate product reviews on Amazon. This includes posting fake reviews, deleting genuine ones, or gaming the review system. Such manipulation is dishonest and can erode trust in the platform. Amazon actively works to combat review manipulation, and those caught engaging in such practices may face account suspension or legal consequences.
Intellectual Property Infringement
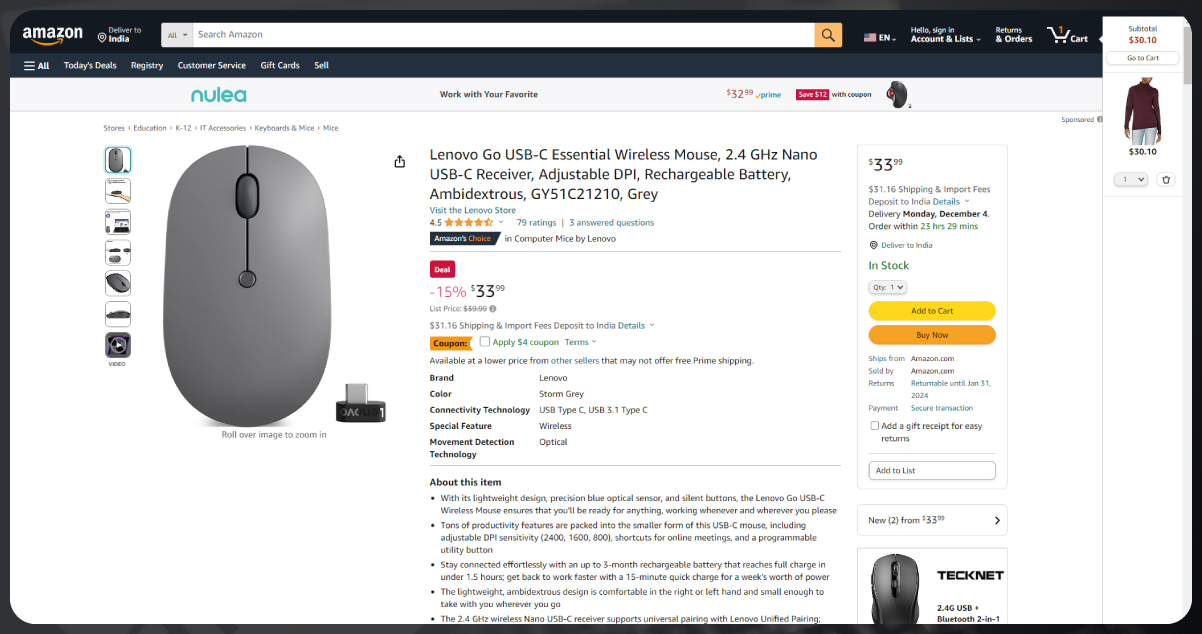
Scraping images, product descriptions, or copyrighted content from Amazon listings without proper authorization infringes on intellectual property rights. Amazon sellers invest time and resources in creating their listings, and unauthorized scraping and reusing of this content can lead to copyright infringement lawsuits and legal penalties.
Unfair Competition
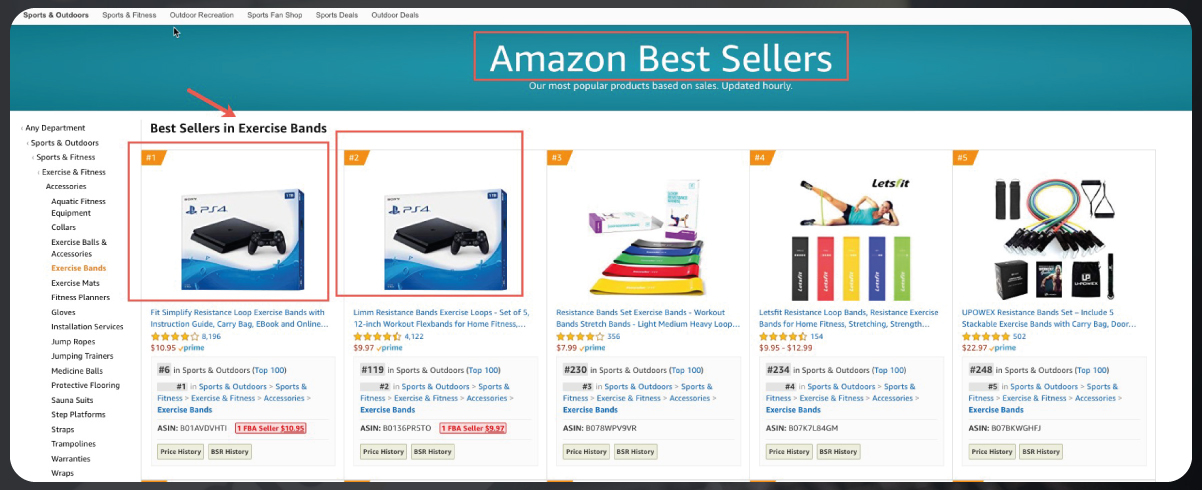
Using scraped data to gain an unfair advantage in the marketplace, such as replicating successful products, exploiting competitors' strategies, or unfairly targeting their customer base, is considered unethical. Engaging in such practices can lead to legal disputes, damage your brand's reputation, and potential account suspension.
Web Traffic Hijacking
Some individuals scrape Amazon's product listings to redirect web traffic from Amazon to their website or another platform. This not only violates Amazon's policies but is also unethical as it diverts potential customers from the intended platform. It can lead to account suspension and loss of trust among Amazon's user base.
Fraudulent Activities
Scraping data intending to engage in fraudulent activities, such as identity theft, credit card fraud, or phishing, is illegal and morally wrong. These activities not only harm Amazon's users but also put you at risk of facing criminal charges and significant legal consequences.
Violation of Amazon's Terms of Service
Amazon has specific terms of service that prohibit certain scraping activities. Violating these terms can result in account suspension, termination, or other legal actions initiated by Amazon.
It's essential to recognize that while web scraping itself is not inherently illegal, how it is employed can make it illegal or unethical. Before engaging in any scraping activities related to Amazon, it is crucial to ensure strict compliance with the law, regulations, and Amazon's policies. Additionally, considering the potential harm scraping can cause to other users, businesses, and the platform is a responsible and ethical approach to data collection in the e-commerce ecosystem. Explore the responsible and ethical use of E-commerce Data Scraping Services to gather insights without causing harm to the digital ecosystem.
Efficiency in Data Extraction: Understanding the Speed of Web Scraping
Web scraping is a powerful technique for collecting data from websites. Still, it should be performed responsibly, considering various factors that affect the speed and efficiency of data extraction. Let's delve into these considerations:
Server Workload
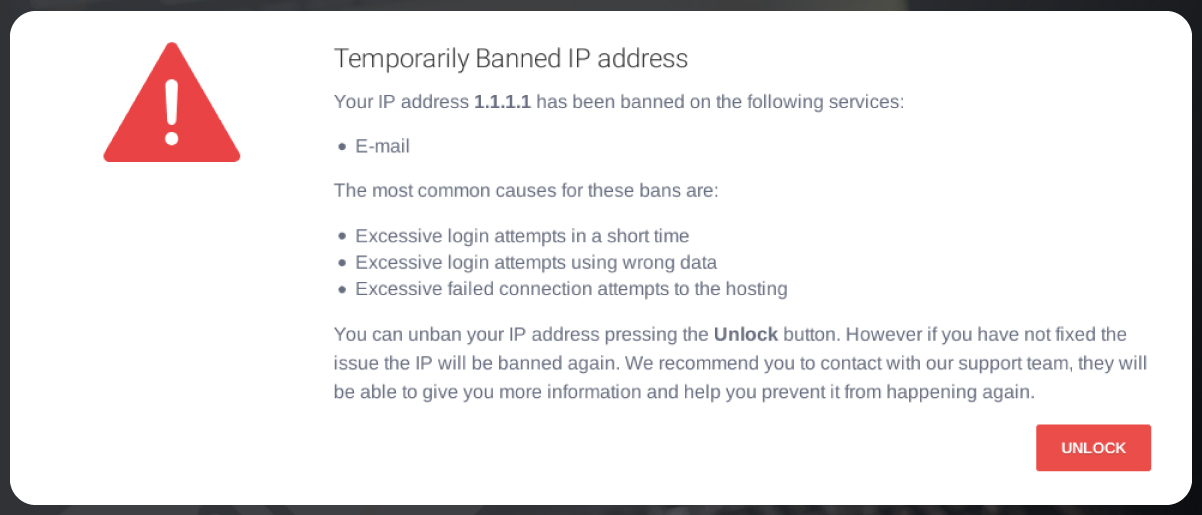
One key factor that affects data extraction speed is the server load of the website being scraped. Heavy server loads can slow down the scraping process as the website's servers may need help to respond to a high volume of requests. Responsible web scrapers monitor server load and adjust their scraping rate to avoid overloading the servers, which could lead to IP blocking or other countermeasures.
Navigating Website Limits
Web scraping should respect the boundaries set by the website. This includes understanding and adhering to the website's terms of service, robots.txt file, and any other specific guidelines provided. Ignoring these boundaries can lead to legal issues and ethical concerns.
Optimizing Web Scraping Speed

Rate limiting, or setting the frequency of requests, is a crucial aspect of responsible web scraping. Scrapers should ensure that they only bombard a website with requests quickly. Setting an appropriate delay between requests not only helps avoid overloading the server but also reduces the risk of getting banned.
Honoring the Website's Integrity
Responsible web scrapers should ensure that their activities do not disrupt the normal functioning of the website. Web scraping should be conducted in a way that doesn't interfere with the experience of other users and doesn't cause unnecessary strain on the website's resources.
The Quest for Quality Amidst Quantity

It's essential to balance the quantity of data collected and the quality of that data. Extracting large volumes of data quickly may lead to inaccuracies, incomplete information, or even getting banned. Prioritizing data quality over quantity is a wise approach.
Ethics in Web Scraping Practices

Ethical considerations are paramount in web scraping. Engaging in scraping activities that could harm others, violate privacy, or deceive users is unethical. Responsible web scrapers should ensure that their activities are aligned with ethical principles and fair play.
Exploring Error Rates
Web scraping is only sometimes error-free. Pages may change in structure or content, causing scraping errors. Responsible scrapers should implement error-handling mechanisms to address these issues, such as retries, error logging, and notifications.
Detect and Evade

Websites often employ anti-scraping measures to detect and block scrapers. Responsible web scrapers should employ techniques to avoid detection, such as using rotating user agents, IP rotation, and CAPTCHA solving, while still adhering to ethical and legal boundaries.
Ensuring Data Persistence
If your web scraping is intended to be an ongoing process, it's crucial to maintain a good relationship with the website. This involves continuously monitoring scraping performance, adjusting to any changes on the website, and being prepared to adapt your scraping strategy to ensure long-term access to the data.
The speed of data extraction in web scraping depends on various factors, and responsible web scrapers take these factors into account to ensure their activities are efficient, ethical, and compliant with the rules and boundaries set by the websites they interact with. By doing so, they can achieve their data extraction goals while minimizing the risk of legal issues, ethical concerns, and disruptions to the websites they scrape.
Best Practices for Preventing Copyright Violations in Web Scraping Amazon Data
You are avoiding copyright infringement when web scraping from Amazon or any website is critical to ensure that you operate within the boundaries of copyright law. Amazon, like many websites, has its terms of service and content protection measures. Here are some specific steps to help you avoid copyright infringement while web scraping from Amazon:
Review Amazon's Terms of Service
Start by thoroughly reading Amazon's terms of service, user agreements, and any web scraping guidelines they may provide. Amazon's terms may specify which activities are allowed and which are prohibited.
Understand Amazon's Robots.txt File
Check Amazon's robots.txt file, which can be found at the root of their website (https://www.amazon.com/robots.txt). The robots.txt file may provide guidelines on which parts of the site are off-limits to web crawlers and scrapers. Adhere to these guidelines.
Use Amazon's API (if available)

Whenever possible, use Amazon's Application Programming Interface (API) to access their data. Amazon provides APIs for various services, and using them is often more compliant with their terms of service.
Scrape Only Publicly Accessible Data
Focus on scraping publicly accessible data that is not protected by copyright. Product information, prices, and availability are typically not copyrighted, but be cautious with descriptions and images, as they may be protected.
Respect Copyrighted Content
Avoid scraping and using copyrighted materials like product images, descriptions, and user-generated content without proper authorization or adherence to fair use principles. Seek permission or use these materials in a manner consistent with copyright law.
Attribute Sources
When displaying or sharing scraped data from Amazon, provide proper attribution and source information to acknowledge Amazon as the original content provider. This practice demonstrates good faith and respect for copyright.
Avoid Republishing Entire Content
Refrain from republishing entire product listings or substantial portions of Amazon's copyrighted content without authorization. Instead, summarize or quote selectively and link back to the source.
Use a Human-Like Scraping Pattern
Employ scraping techniques that mimic human browsing behavior, such as adding delays between requests, randomizing user agents, and avoiding aggressive or rapid scraping. This can help prevent being detected as a malicious bot.
Monitor and Adapt
Continuously monitor your scraping activities and adapt to any changes in Amazon's terms of service, website structure, or technology. Stay aware of any updates or changes in their policies.
Legal Consultation
If you are still determining the legality of your web scraping activities on Amazon, consider seeking legal advice from experts in copyright and web scraping law. Legal professionals can provide guidance specific to your situation.
It's essential to approach web scraping from Amazon or any e-commerce platform with caution and respect for copyright laws. By adhering to Amazon's terms of service, observing copyright regulations, and maintaining ethical web scraping practices, you can extract the necessary data while minimizing the risk of copyright infringement and legal issues.
Legal Considerations for Web Scraping on Amazon Marketplace
Web scraping laws can vary significantly from one country to another, and when it comes to the Amazon Marketplace, it's essential to understand the legal landscape in different jurisdictions. Amazon, as a global e-commerce platform, operates in numerous countries and regions, each with its legal framework regarding web scraping and data collection. Below is a broad overview of web scraping laws related to the Amazon Marketplace in different countries.
United States
In the United States, web scraping laws are primarily governed by federal copyright and computer fraud laws. While copyright laws protect original content and creative works, web scraping may infringe upon copyrights if not conducted responsibly. The Computer Fraud and Abuse Act (CFAA) can be used to prosecute scraping activities that involve unauthorized access to computer systems. Therefore, it's essential to respect Amazon's terms of service and legal boundaries when scraping its platform.
European Union
In the European Union, web scraping laws are influenced by data protection regulations, copyright laws, and the General Data Protection Regulation (GDPR). GDPR, in particular, imposes strict rules on the collection and processing of personal data, which includes customer information. Suppose you are scraping data from Amazon's EU websites. In that case, you must ensure that you comply with GDPR requirements, such as obtaining user consent for data processing and following the principles of data minimization.
United Kingdom
The UK, after leaving the EU, has adopted its data protection laws, including the UK GDPR. These regulations influence web scraping laws in the UK. It's crucial to respect user privacy and data protection rights when scraping data from Amazon UK or any other website.
Canada
In Canada, web scraping laws are influenced by the Copyright Act, which protects original literary, artistic, and dramatic works. While factual information may not be subject to copyright, scraping product descriptions or images without proper authorization can infringe upon copyrights. Additionally, Canada has data protection laws, like the Personal Information Protection and Electronic Documents Act (PIPEDA), which governs the handling of personal data.
Australia
Australia has copyright laws similar to those in the United States, which protect original works. However, facts and data are not generally subject to copyright. When scraping Amazon Australia, you should respect the terms of service and intellectual property rights while adhering to the Australian Privacy Principles (APPs) when handling personal data.
India
In India, web scraping laws are primarily influenced by copyright law, which protects original literary and artistic works. Web scraping that infringes upon copyrighted content may result in legal action. Data protection laws in India are evolving, with the Personal Data Protection Bill awaiting enactment.
China
China has specific regulations and guidelines for Internet information services and data privacy. When scraping Amazon China, be aware of these regulations, which may require user consent for collecting and processing personal data.
Japan
Japan's Personal Information Protection Act governs the handling of personal data, making it essential to adhere to data protection laws when scraping from Amazon Japan. Intellectual property laws also protect copyrighted content.
It's crucial to remember that web scraping laws can be complex and are subject to change. Before engaging in web scraping activities on Amazon Marketplace in different countries, it is advisable to consult with legal experts who are well-versed in the specific jurisdiction's laws. Additionally, it is essential to respect Amazon's terms of service, robots.txt guidelines, and any website-specific regulations to avoid legal issues and ethical concerns.
Web Scraping Ethics: Guidelines for Handling Nonpublic Data
Regarding web scraping, particularly for nonpublic information, it's crucial to exercise caution, responsibility, and compliance with legal and ethical standards. Nonpublic information can include sensitive data, proprietary information, personal details, or content not intended for public consumption. Here are some considerations to keep in mind when scraping nonpublic information:
Legal Compliance
Ensure that your web scraping activities comply with applicable laws, including copyright, data protection, and privacy regulations. Unauthorized scraping of nonpublic data can lead to legal action and severe consequences.
User Consent
When dealing with personal or sensitive data, always obtain informed consent from users before collecting their information. This consent should be freely given, specific, and unambiguous. Violating privacy regulations can result in hefty fines.
Terms of Service and User Agreements
Websites often have terms of service or user agreements that explicitly state their policies regarding data scraping. Respect these agreements and ensure your scraping activities align with their guidelines. Ignoring them can lead to legal disputes.
Robots.txt and Website Guidelines
Review the website's robots.txt file and any other guidelines provided. Nonpublic data is often protected from web scraping, and failure to adhere to these directives may result in blocking or legal action.
Selective Data Extraction
When scraping nonpublic information, extract only the data you genuinely need. Avoid collecting unnecessary data, as doing so can raise ethical and legal concerns.
Data Protection and Encryption
Implement robust data protection measures, such as encryption and secure storage, to safeguard any nonpublic data you collect. Failure to protect sensitive data can result in security breaches and legal liability.
Anonymization and De-identification
When working with personal data, consider anonymizing or de-identifying the information to remove any identifying elements. This can help protect individuals' privacy and minimize legal risks.
Minimize Impact on Servers
Nonpublic data scraping should be conducted with minimal impact on the server's resources. Avoid overloading the website with requests, which can disrupt its operation and result in potential legal action.
Ethical Use of Information
Scrutinize how you plan to use the nonpublic data you collect. Avoid using it for malicious purposes, such as fraud, identity theft, or harassment. Ethical use of information is a fundamental principle
Data Retention and Deletion
Define clear policies for data retention and deletion. Only keep nonpublic information for the necessary period and dispose of it securely when it is no longer required.
Continuous Monitoring and Updates
Regularly monitor your scraping activities and adjust them to any changes in the website's policies or data protection regulations. Stay informed and be prepared to adapt your approach accordingly.
Legal Advice
If you have concerns or uncertainties about scraping nonpublic information, it's advisable to seek legal counsel with expertise in data privacy and web scraping laws. Legal professionals can provide specific guidance based on your circumstances.
Scraping nonpublic information requires meticulous attention to legal, ethical, and privacy considerations. Failing to respect these considerations can result in legal consequences, damage to your reputation, and potential harm to individuals whose data is involved. Responsible web scraping practices are essential to balance data collection and ethical, lawful behavior.
Conclusion
Amazon web scraping presents a complex landscape of legal and ethical challenges. Understanding the potential risks and consequences is paramount for businesses and individuals looking to harness the power of web scraping while maintaining ethical integrity. To navigate this terrain with confidence and compliance, consider partnering with Actowiz Solutions. Our expertise in data extraction and commitment to responsible practices can help you achieve your data-driven goals while safeguarding against illegal and unethical pitfalls. Contact us today to explore how Actowiz Solutions can assist you in your web scraping endeavors and ensure you remain on the right side of the law and ethics. You can also reach us for all your mobile app scraping, instant data scraper and web scraping service requirements.
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming NEW
OTT & Streaming NEW
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing NEW
Dynamic Pricing / AI Repricing NEW
 Promotions & Deals Alerts NEW
Promotions & Deals Alerts NEW
 B2B / POI & Lead Data NEW
B2B / POI & Lead Data NEW
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries














































