
Introduction
Data parsing is not just a technical process, but a key to unlocking the full potential of your data. It converts data from one format into a more usable, readable, or structured format, a crucial step in data processing and analysis. It enables applications to interpret and manipulate data effectively, whether it's web data, mobile app data, or raw JSON files. Understanding how to parse data is not just essential, but a game-changer for efficient data handling and analysis.
In this blog, we'll explore various data parsing techniques and tools, with a particular focus to parse data from JSON using Python. JSON (JavaScript Object Notation) is a popular data interchange format, especially in web and mobile applications, due to its simplicity and readability. With its robust libraries, Python offers powerful methods for parsing JSON data, making it an ideal language for parsing data tasks.
We'll also discuss how to scrape mobile app using Python, a valuable skill for gathering data from app interfaces. Additionally, we will discuss methods to parse HTML trees in Python, using HTML parsing tools to extract meaningful information from web pages. We will review commercial data and data parsing tools available in the market, providing insights into when and why you might choose a specific tool over coding your parser.
Are you ready to unlock the full potential of your data? Join us as we embark on a journey into the world of data parsing in Python. We'll be examining various techniques and tools that can streamline your data processing workflows and enhance your data analysis capabilities. Get ready to take your data handling and analysis to the next level!
What Is Data Parsing?
Data parsing is not just about converting raw data into a structured format; it's about transforming data from one state to another, making it more accessible and usable. This process involves interpreting and transforming data from one format into another, enabling applications and systems to understand and process the data effectively. Parsing can be applied to various data formats, including text files, JSON, XML, and HTML. The goal is to extract meaningful information, validate the data, and make it suitable for further analysis or use in applications, showcasing the power and potential of parsing data.
For example, consider a web application that receives data in JSON format from an API. This raw JSON data needs to be parsed to extract relevant information, such as user details or product listings so that it can be displayed on the website or used in backend processing.
Parsing data is crucial in many fields, including web development, data analysis, and machine learning. It allows for the efficient handling and manipulation of data, ensuring that systems can process and analyze information accurately. By converting unstructured or semi-structured data into a structured format, parsing makes it easier to query, manipulate, and derive insights from the data.
Define a Data Parser and Outline How It Operates

A data parser is a software tool or program that converts raw data into a structured, readable format. This process, known as parsing data, is essential for making data suitable for analysis and application usage. Data parsers are used across various domains, including web development, data analysis, and mobile app development.
In Python, parsing data is facilitated by robust libraries and tools. For instance, the json library is commonly used to parse data from JSON using Python. This library allows you to convert JSON data into Python dictionaries, making it easier to manipulate and analyze. Similarly, when you need to scrape mobile app using Python, libraries like BeautifulSoup and lxml are invaluable. These libraries help parse HTML trees, extracting useful information from web pages and app interfaces.
Commercial data parsing tools are a reliable choice for handling large datasets and complex parsing tasks. These tools, with their versatile features, often come with user-friendly interfaces and support for various data formats, providing a sense of reassurance and making them suitable for enterprise-level applications.
HTML parsing tools are specifically designed for extracting data from HTML documents. Tools like BeautifulSoup and Scrapy enable developers to parse HTML trees in Python, facilitating web scraping and data extraction from websites.
Data parsing techniques in Python are a testament to its efficiency and power. These techniques, which vary depending on the data source and format, include regular expressions for text parsing, JSON parsing for structured data, and HTML tree parsing for web data. By harnessing these techniques and tools, data parsing in Python becomes a powerful process for transforming raw data into actionable insights, inspiring you to explore and utilize these capabilities.
Why Is Data Parsing in Web Scraping Important?

Parsing data is a critical component in web scraping, enabling the extraction of structured and meaningful information from raw web data. As the web comprises various data formats and structures, practical parsing data ensures that the extracted data can be used efficiently for analysis, reporting, or further processing.
One of the primary reasons parsing data is crucial in web scraping is the need to handle different data formats. Websites can deliver content in HTML, JSON, XML, or other formats. For instance, to scrape data from a mobile app using Python, you might encounter JSON responses from the app's API. Using a data parsing tool like Python's json library, you can quickly parse data from JSON using Python into a structured format such as a dictionary, facilitating further manipulation and analysis.
Similarly, parsing the HTML tree is essential when dealing with web pages. Python libraries such as BeautifulSoup and lxml allow developers to parse HTML trees, extracting specific elements, attributes, or text from web pages. This process is fundamental in web scraping, as it converts the raw HTML into structured data that can be analyzed or stored in databases.
Commercial data parsing tools offer a host of advanced capabilities, including handling large datasets, automating parsing tasks, and providing user-friendly interfaces. These tools are especially advantageous for enterprise-level web scraping projects, where efficiency and scalability are of utmost importance. Their use can significantly streamline the web scraping process, enhancing productivity and ensuring high-quality results.
Parsing data plays a crucial role in maintaining data quality and integrity. Raw web data often contains noise, inconsistencies, or redundant information. Effective parsing techniques help clean and normalize this data, ensuring the final output is accurate and reliable. This is particularly significant when the scraped data is used for decision-making processes or integrated into other systems, highlighting the importance of parsing data in web scraping.
Parsing data is indispensable in web scraping because it can transform raw, unstructured data into a structured and usable format. Effective parsing techniques are essential for successful web scraping projects, whether you are parsing JSON responses from a mobile app, extracting data from an HTML tree using Python, or utilizing commercial data parsing tools. These techniques ensure data accuracy, integrity, and usability, making them a modern cornerstone of data extraction and analysis.
Differentiating Data Scraping and Data Parsing

Data Scraping and Parsing are essential for extracting and manipulating data from various sources. While closely related, they serve distinct purposes and involve different techniques.
Data Scraping: Data or web scraping is the process of extracting data from websites or web pages. It involves accessing web content, retrieving desired information, and saving it for further use. Critical characteristics of data scraping include:
Techniques: Web scraping techniques involve fetching HTML content from web pages, often using HTTP requests, and extracting relevant data using parsing techniques.
Tools: Popular web scraping tools include Python libraries like BeautifulSoup and Scrapy, which facilitate the extraction of specific elements or text from HTML documents.
Use Cases: Data scraping is commonly used to gather information from websites for various purposes, such as market research, competitive analysis, and content aggregation.
Data Parsing:Data parsing is converting raw data from one format into another, typically into a structured format that is easier to manage and analyze. It involves interpreting data and extracting meaningful information. Critical aspects of parsing data include:
Techniques: Parsing techniques vary depending on the data format. For example, parsing HTML trees in Python involves using libraries like BeautifulSoup or lxml to navigate the HTML structure and extract desired data.
Tools: Data parsing tools include commercial software and libraries in programming languages like Python. These tools help parse data from various sources, including JSON, XML, and CSV files.
Use Cases: Parsing data is essential in various domains, including data analysis, integration, and transformation. It enables the conversion of unstructured or semi-structured data into a structured format suitable for analysis and processing.
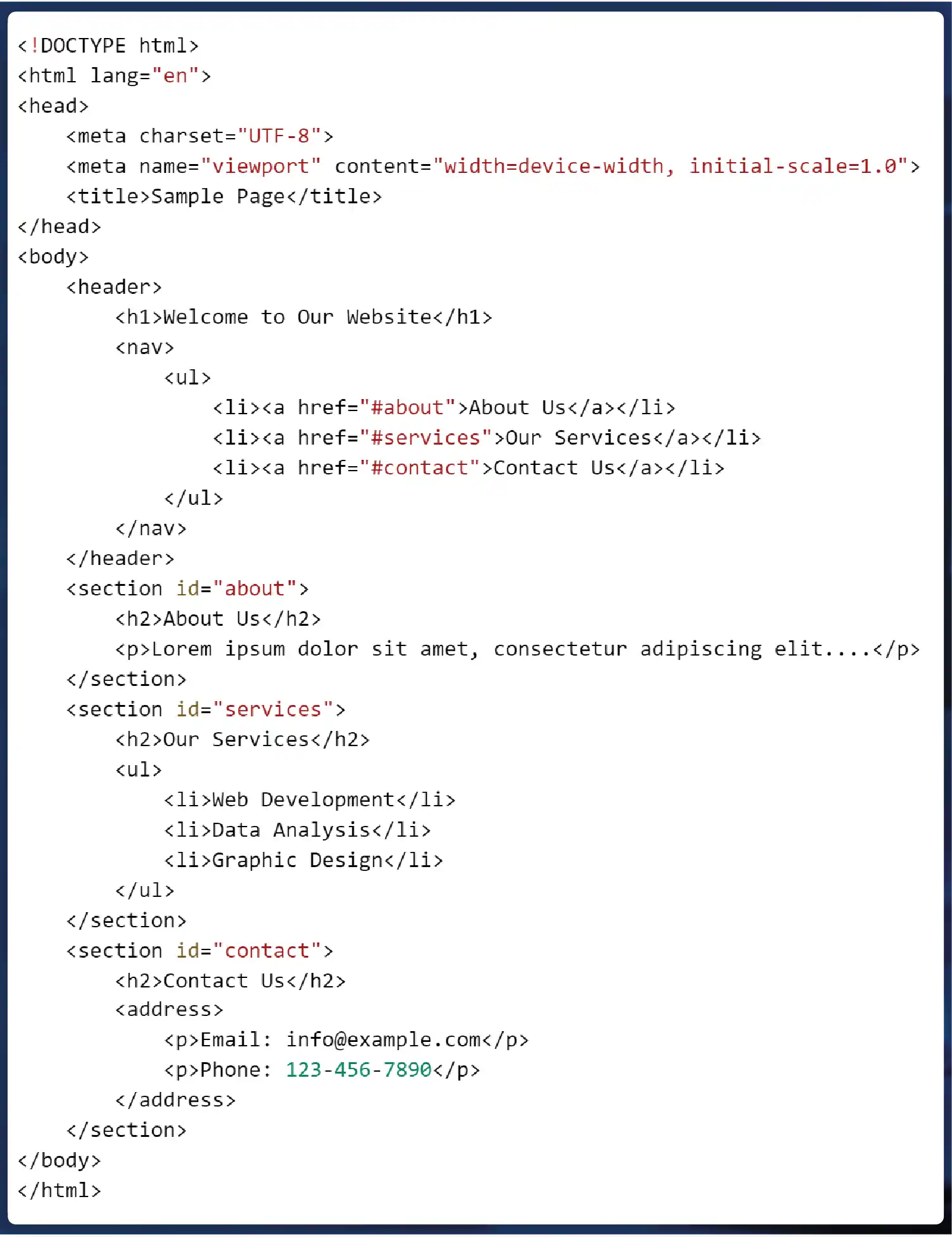
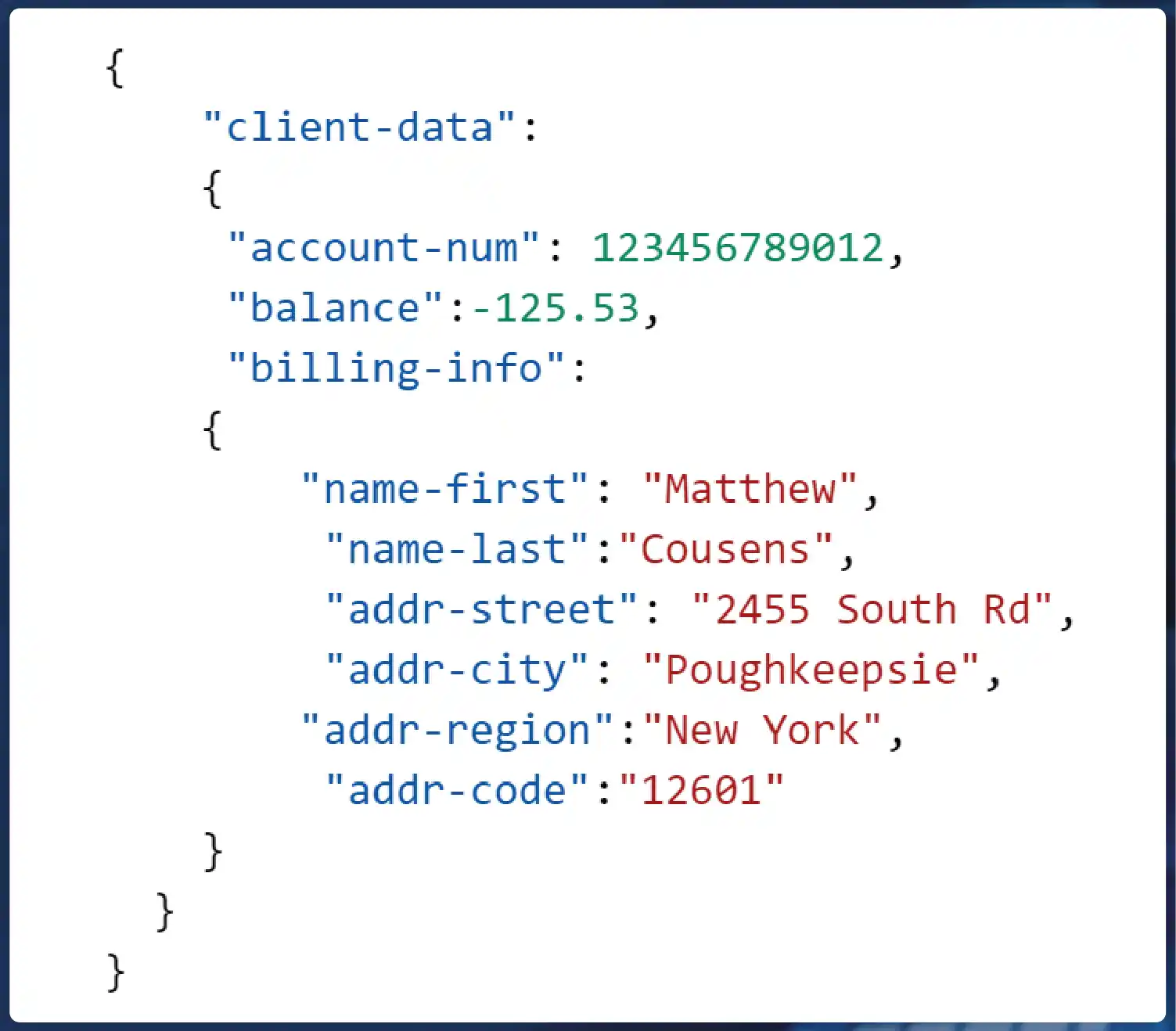
Raw HTML Data: Example
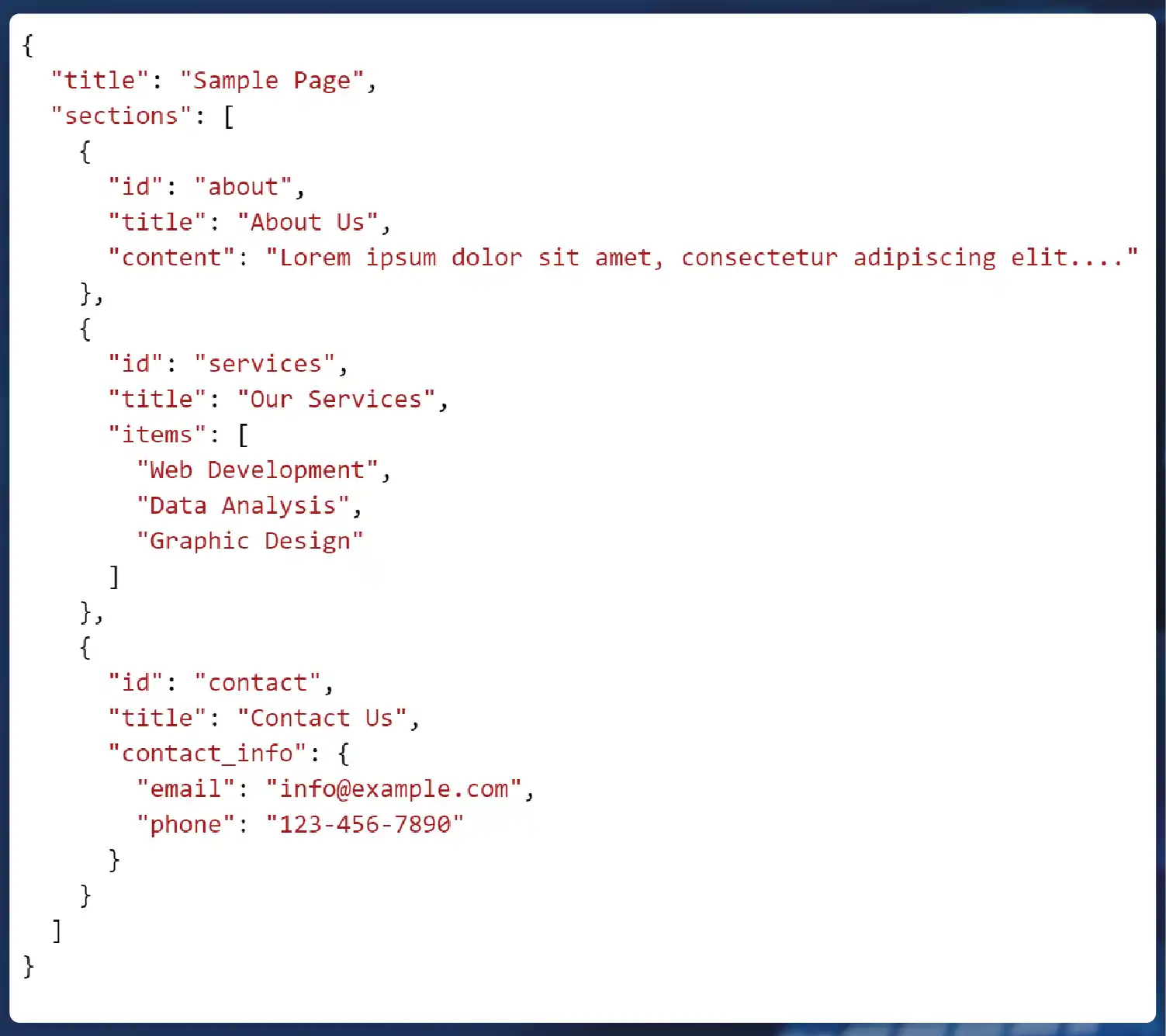
Parsed Data: Example
What are the Methods for Parsing Data in Python?
Scraping Mobile App Data using Python:

Use Python libraries like requests to fetch data from mobile app APIs.
Parse JSON responses using the built-in json library to extract relevant information.
Parse data from JSON using Python:
Use the json library to parse JSON data into Python dictionaries or objects.
Access specific data elements by navigating the parsed JSON structure.
Parse HTML Tree in Python:
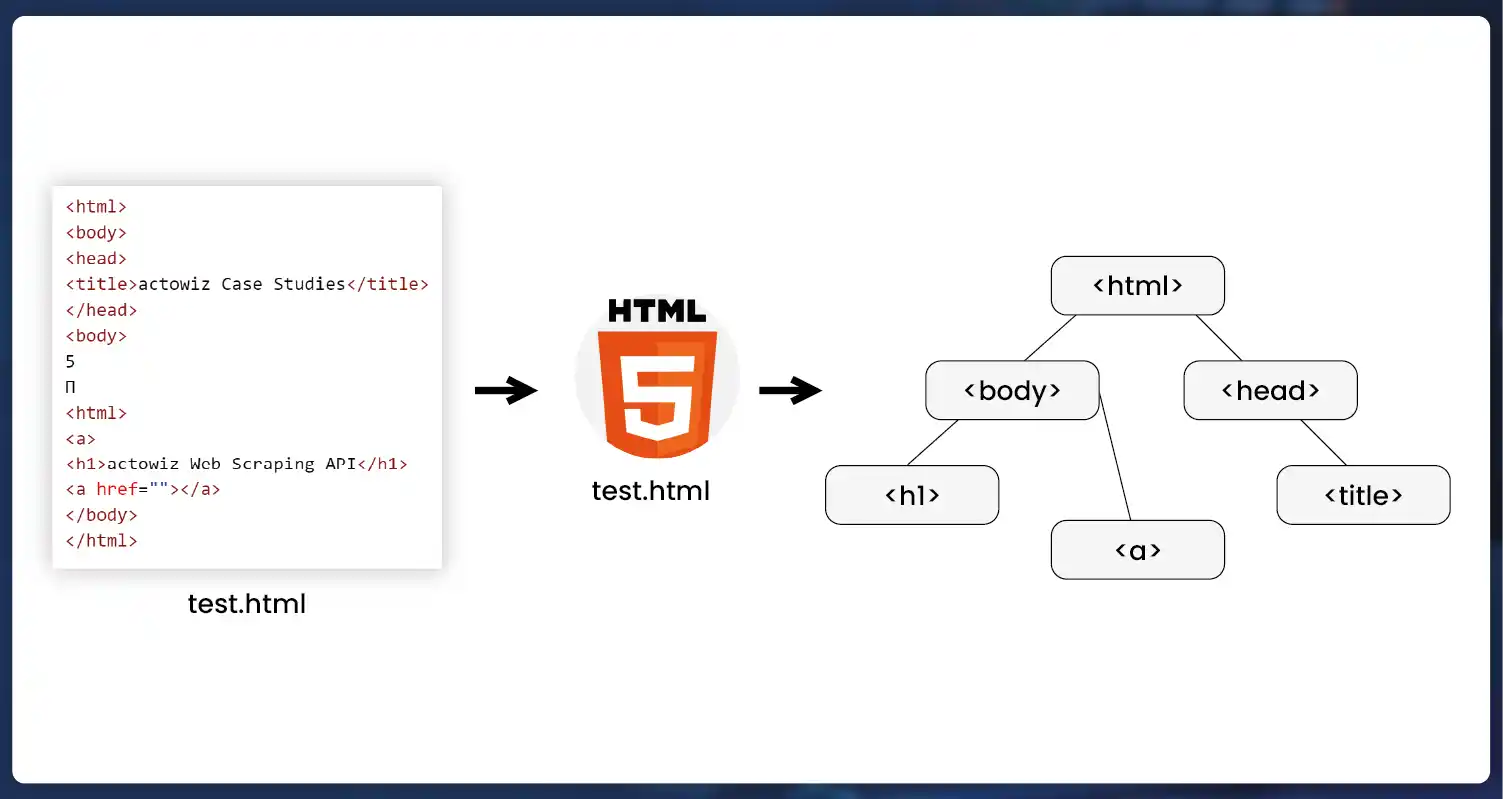
Employ HTML parsing tools like BeautifulSoup or lxml to parse HTML documents.
Extract desired data elements such as tags, attributes, and text content from the HTML tree.
These methods enable efficient data parsing in Python, allowing developers to extract, process, and manipulate data from various sources with ease. Additionally, commercial data parsing tools offer advanced features for handling complex parsing tasks and large datasets, providing alternative solutions for parsing data needs.
Widely Used Data Parsing Methods
Parsing data, a crucial process in data analysis, involves transforming raw data into a structured format for efficient processing and analysis. It's a fundamental step that enables us to make sense of the vast amount of data we encounter. Several techniques are commonly used for parsing data across various formats and sources.
Regular Expressions (Regex): Regular expressions are powerful tools for pattern matching and string manipulation. They allow developers to define search patterns and extract specific data from unstructured text. Regex is commonly used to parse text files, log files, and other textual data where patterns are predictable.
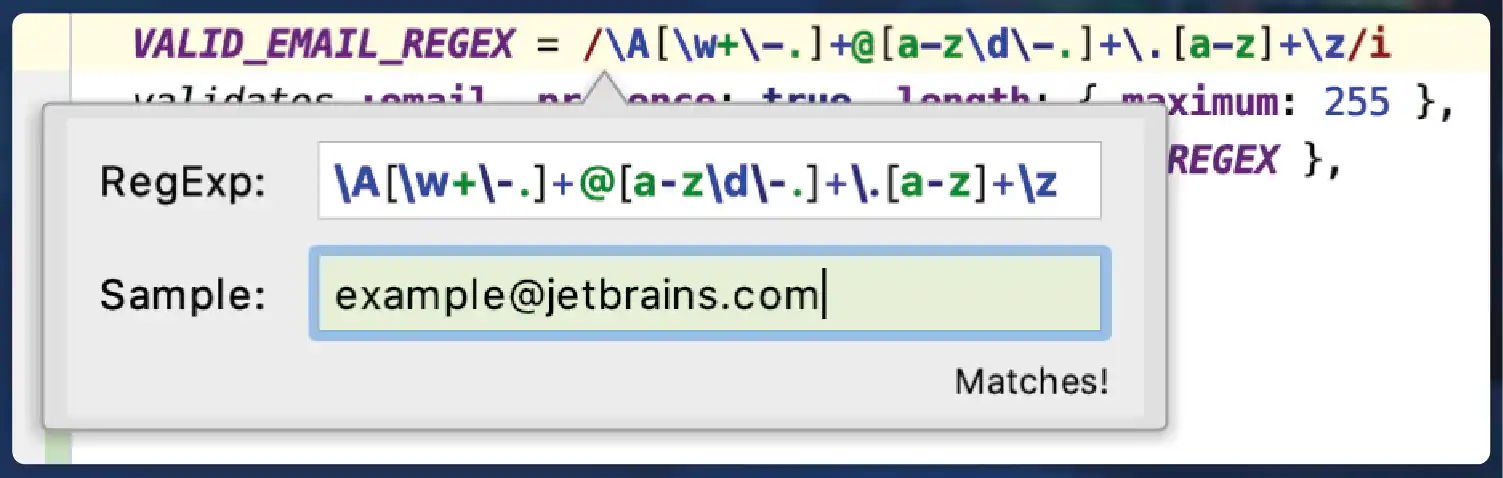
JSON Parsing: JSON (JavaScript Object Notation) is a lightweight data-interchange format widely used in web development and APIs. JSON parsing involves converting JSON data into native data structures, such as dictionaries or lists in Python. This enables easy access to individual data elements for further processing.
XML Parsing: XML (eXtensible Markup Language) is another popular data format for representing structured data. XML parsing involves parsing XML documents to extract data elements and attributes. Libraries like ElementTree in Python provide efficient XML parsing capabilities, allowing developers to navigate XML trees and retrieve desired data.
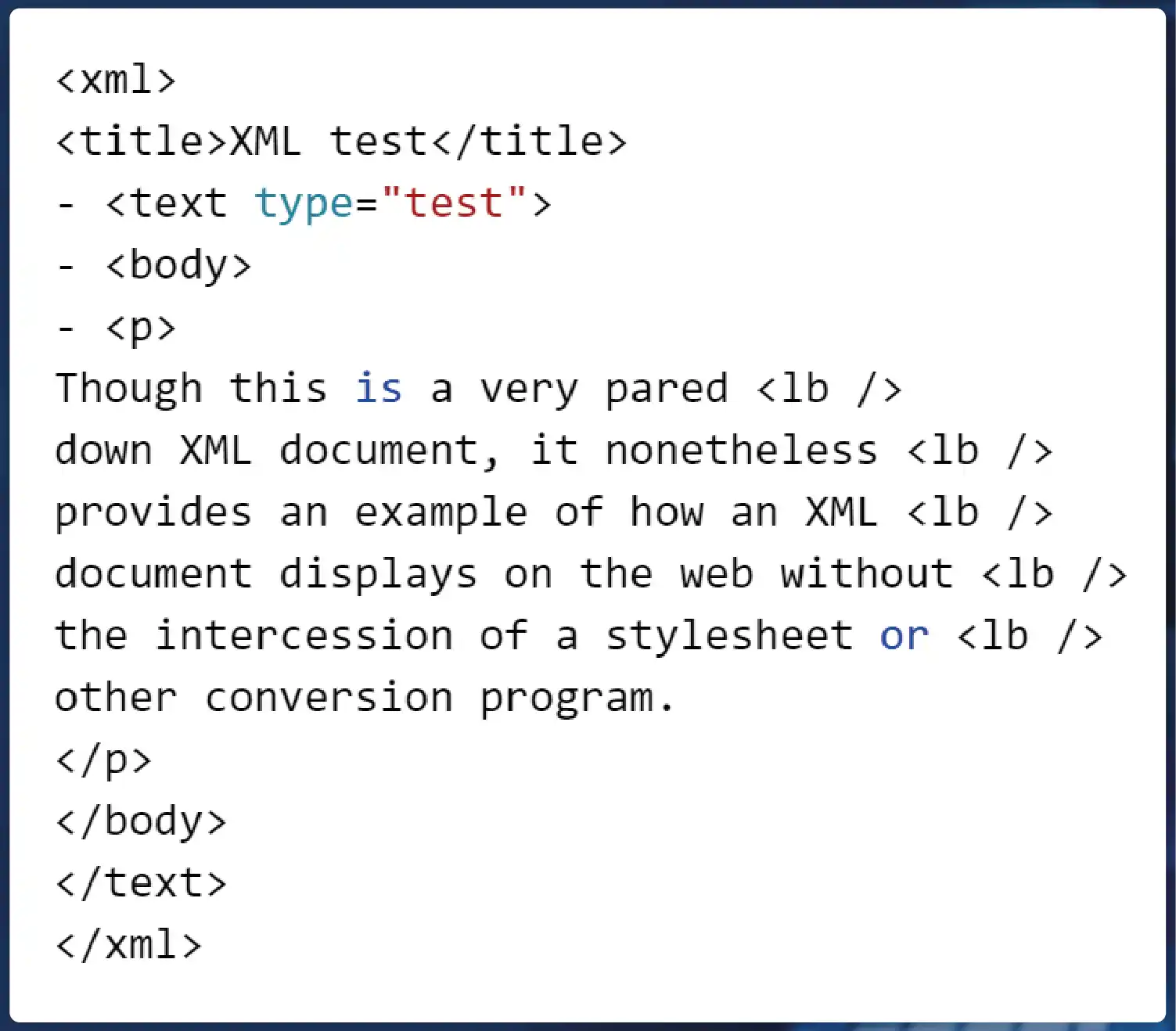
HTML Parsing: HTML (Hypertext Markup Language) parsing is essential for extracting data from web pages. HTML parsing tools like BeautifulSoup and lxml in Python help developers parse HTML documents and extract specific elements, attributes, or text content. This is particularly useful for web scraping and data extraction from websites.
CSV Parsing: Comma-separated values (CSV) files are commonly used for storing tabular data. CSV parsing involves reading and converting CSV files into data structures like arrays or dictionaries. Python's built-in csv module provides functions for reading and writing CSV files, making it easy to parse and manipulate CSV data.
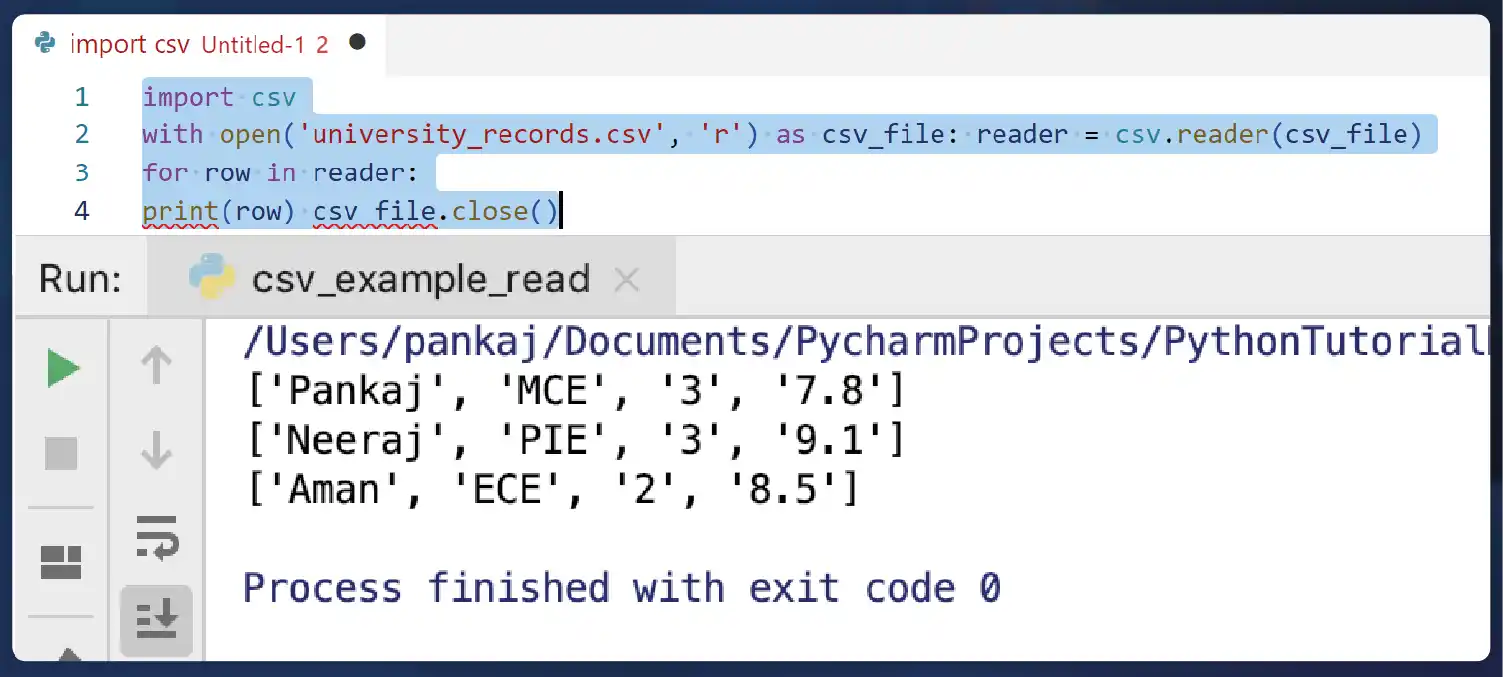
Data Frame Parsing: Data frames are tabular structures commonly used in data analysis and manipulation tasks. Libraries like Pandas in Python provide potent tools for parsing and working with data frames. Data frame parsing involves reading data from various sources, such as CSV files, Excel spreadsheets, databases, and JSON files, into data frames for analysis.
These widely used parsing data methods enable developers to efficiently extract, transform, and analyze data from diverse sources, laying the groundwork for meaningful insights and informed decision-making.
Commonly Used HTML Parsing Tools
HTML parsing tools are essential for extracting structured data from web pages and facilitating tasks like web scraping, data extraction, and information retrieval. Several tools are commonly used for HTML parsing due to their robust features and ease of use.
Beautiful Soup:

Beautiful Soup is a popular Python library for parsing HTML and XML documents. It provides:
- Simple and intuitive methods for navigating HTML trees.
- Searching for specific tags or attributes.
- Extracting data.
- Beautiful Soup's flexible syntax suits various web scraping tasks, from simple data extraction to complex web crawling projects.
lxml:

lxml is another powerful HTML parsing library for Python. It is built on libxml2 and libxslt, offering high-performance and efficient parsing capabilities. lxml provides an HTML parser (lxml.html) and an XML parser (lxml.etree), allowing developers to parse and manipulate HTML documents quickly. With support from XPath and CSS selectors, lxml enables precise data extraction from HTML structures.
Scrapy:

Scrapy is a comprehensive web crawling and scraping framework for Python. While it offers a complete solution for building web scrapers and crawlers, Scrapy includes built-in support for HTML parsing using its Selector and Item classes. Scrapy's powerful features, such as asynchronous networking and distributed crawling, make it suitable for large-scale web scraping projects.
HTMLParser (Python Standard Library):
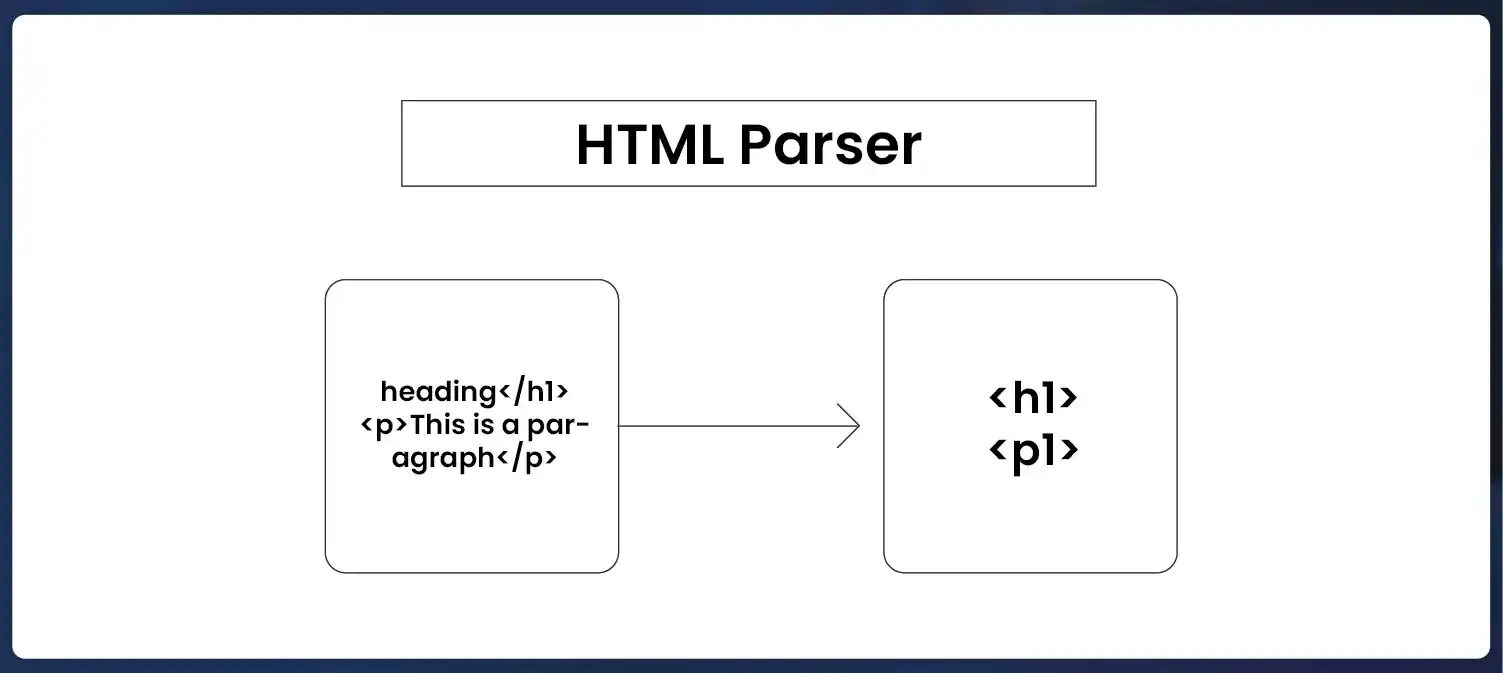
HTMLParser is a built-in module in Python's standard library for parsing HTML documents. While it lacks some advanced features of third-party libraries like Beautiful Soup and lxml, HTMLParser provides a basic HTML parsing functionality for simple parsing tasks. It is beneficial for projects that require minimal dependencies or for learning purposes.
PyQuery:

PyQuery is a jQuery-like library for Python that simplifies HTML parsing and manipulation. It provides a familiar API for working with HTML documents, allowing developers to use CSS selectors to select and extract data from HTML elements. PyQuery's concise syntax makes it an excellent choice for developers familiar with jQuery and CSS.
These commonly used HTML parsing tools empower developers to extract and process data from HTML documents, enabling a wide range of web scraping and data extraction applications.
Challenges of Data Parsing Using Python

Data parsing using Python offers numerous benefits, but it also presents certain challenges that developers may encounter. Understanding and addressing these challenges is essential for efficient and accurate parsing data processes.
Handling Complex Data Structures:
Parsing data often involves dealing with complex data structures, especially when parsing nested JSON objects or deeply nested HTML documents. Managing and navigating these structures efficiently can be challenging, requiring careful design and implementation of parsing algorithms.
Ensuring Data Integrity:
Maintaining data integrity during parsing is crucial, especially when dealing with large datasets or real-time data streams. Parsing errors or inconsistencies can lead to incorrect data interpretation and analysis. Implementing robust error handling mechanisms and data validation checks is essential to ensure data integrity throughout the parsing process.
Dealing with Unstructured Data:
Many data sources, such as web pages or text documents, contain unstructured or semi-structured data. Parsing such data requires advanced techniques, such as natural language processing (NLP) or regular expressions, to extract meaningful information effectively. Handling unstructured data adds complexity to the parsing process and may require additional preprocessing steps.
Performance Optimization:
Parsing data can be resource-intensive, especially when dealing with large datasets or complex data structures. Optimizing parsing algorithms and data processing techniques is essential to improve performance and reduce processing times. Techniques like lazy parsing, caching, and parallel processing can help optimize parsing data performance in Python.
Choosing the Right Tools and Libraries:
Python offers a wide range of tools and libraries for parsing data, each with its strengths and limitations. Selecting the appropriate tools and libraries for specific parsing tasks can be challenging, especially when considering factors like ease of use, performance, and compatibility with other components of the data processing pipeline.
Handling Dynamic Data Sources:
Parsing data from dynamic sources, such as web pages generated using client-side JavaScript, presents unique challenges. Parsing dynamically generated content requires techniques like web scraping with headless browsers or interacting with web APIs to retrieve the desired data. Handling dynamic data sources adds complexity to the parsing process and requires careful consideration of factors like data freshness and reliability.
Addressing these challenges requires a combination of technical expertise, domain knowledge, and effective problem-solving skills. By understanding and overcoming these challenges, developers can ensure efficient and accurate parsing data processes in Python.
Constructing vs. Acquiring a Data Parsing Tool

When faced with the need for a data parsing tool, organizations must decide whether to develop a custom solution in-house or purchase an existing tool from the market. Each approach has advantages and considerations, depending on budget, time constraints, and specific requirements.
Building a custom data parsing tool involves designing and implementing a solution tailored to the organization's needs. This approach offers several benefits:
Customization: Building a tool from scratch allows organizations to tailor it precisely to their requirements. They can incorporate specific features, functionality, and integration capabilities to effectively meet their parsing data needs.
Control: Developing an in-house solution provides complete control over the tool's development, maintenance, and future enhancements. Organizations can prioritize features, address issues promptly, and adapt the tool to evolving business needs.
Scalability: Custom solutions can be designed with scalability, allowing organizations to accommodate growing data volumes and processing requirements over time. They can also optimize performance, scalability, and resource utilization according to their specific use cases.
However, building a custom data parsing tool also comes with challenges and considerations:
Time and Resources: Developing a custom solution requires time, expertise, and resources for design, development, testing, and deployment. It may involve significant upfront investment and ongoing maintenance costs.
Complexity: Building a data parsing tool involves various technical challenges, such as parsing different data formats, handling edge cases, and ensuring robust error handling and data validation.
Expertise: Organizations need access to skilled developers with expertise in parsing data, programming languages, and relevant technologies to build and maintain the tool effectively.
On the other hand, acquiring a pre-built data parsing tool from the market offers several advantages:
Rapid Deployment: Purchasing a ready-made solution allows organizations to deploy the tool quickly without extensive development or customization efforts.
Cost-Effectiveness: Acquiring a commercial data parsing tool may be more cost-effective than building a custom solution, especially considering development time, resources, and ongoing maintenance costs.
Vendor Support and Updates: Commercial tools often come with vendor support, regular updates, and maintenance, ensuring ongoing reliability, compatibility, and security.
However, organizations must carefully evaluate commercial solutions to meet their specific requirements, offer the desired features, and provide adequate support and scalability. Additionally, they should consider factors such as licensing, integration capabilities, and long-term vendor viability when choosing a commercial data parsing tool.
Deciding to build or buy a data parsing tool depends on customization needs, time constraints, resources, expertise, and budget considerations. By carefully weighing the pros and cons of each approach, organizations can choose the most suitable option to effectively meet their data parsing requirements.
Conclusion
Actowiz Solutions, as a key player in the data management and analytics industry, faces the critical task of effectively managing and parsing data to meet the evolving needs of its clients and projects. With the growing demand for efficient parsing data solutions, Actowiz's role in carefully considering its approach to address this challenge is crucial.
The company can either develop a custom data parsing tool or acquire a commercial solution from the market. Building a custom tool would allow Actowiz to tailor the solution to its specific requirements, incorporating features like scraping mobile app data using Python, parsing JSON and HTML data, and implementing advanced data parsing techniques.
On the other hand, acquiring a commercial data parsing tool could offer rapid deployment, cost-effectiveness, and vendor support. Actowiz is committed to thoroughly evaluating commercial solutions to ensure they meet its needs for data parsing in Python, HTML parsing tools, and integration capabilities, providing a solid foundation for our decision-making process.
Ultimately, the decision should align with Actowiz's goals, resources, and long-term strategy. Actowiz must prioritize scalability, performance, and data integrity to deliver reliable solutions to its clients, whether building or buying a data parsing tool. By making an informed choice and leveraging the right tools and techniques, Actowiz can enhance its parsing data capabilities and maintain its position as a leading provider of innovative solutions in the data analytics domain. For more information, contact us now! You can also reach us for all your mobile app scraping, instant data scraper and web scraping service requirements.
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming NEW
OTT & Streaming NEW
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing NEW
Dynamic Pricing / AI Repricing NEW
 Promotions & Deals Alerts NEW
Promotions & Deals Alerts NEW
 B2B / POI & Lead Data NEW
B2B / POI & Lead Data NEW
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries














































