
Introduction
Facing challenges with doing product matching manually in the e-commerce sector? Then you're not the only one. We've recently partnered with a client grappling with similar e-commerce product matching obstacles. Our innovative solution? A streamlined Python script that skyrocketed product matching for e-commerce efficiency by an astounding 500%, all while adhering to budget constraints.
This blog delves deep into the nuances about e-commerce product matching, offering brands insights to optimize their manual efforts without exorbitant costs. Dive into our expertise, harness valuable e-commerce data collection strategies, and refine your product listings.
In the dynamic e-commerce landscape, e-commerce product matching emerges as a cornerstone. As digital shopping platforms burgeon, the value of precise product matching for e-commerce intensifies. Although the journey towards comprehensive automated e-commerce product matching algorithms continues, our goal is to shed light on the current methodologies.
Our exploration focuses on developing a Python-driven script for e-commerce product matching, leveraging data from industry giants like Amazon. This process demystifies the complexities about e-commerce data scraping services and product matching intricacies.
Join us as we unveil how does product matching for e-commerce reshape online shopping paradigms, refining price assessments, inventory management, and bolstering competitive edge and complete buyer satisfaction and. Let's delve deeper into this transformative journey!
What Does Product Matching Mean?
In e-commerce, product matching is the act of pinpointing and connecting identical or closely related items across various online stores or within distinct listings on a single e-commerce site.
This practice holds immense significance in multiple facets of online retail, encompassing price evaluations, personalized product suggestions, inventory oversight, and analyzing market competition.
Here's a classification of the intricacies within product matching:
Identifying Identical or Analogous Products Across Various
Retailers: The realm about product matching is multifaceted, encompassing exact matches as well as variants.
Matching Exact Products: This pertains to aligning items that are precisely alike but showcased on different online platforms. For instance, a particular smartphone model listed on Amazon or Best Buy might be recognized as identical.
Matching Analogous Products: This involves a deeper analysis to spot items that, while not identical, share enough resemblances to be seen as potential substitutes or akin offerings. For instance, two distinct brands dealing in blue shoes, possessing similar designs and functionalities, could be categorized as analogous products.
Why Product Matching Has Become Very Complex?
Product matching poses intricate challenges, primarily because of intricate nature of precisely connecting and correlating products across diverse databases and platforms. Here's a distilled list highlighting the complexities about product matching:
Diverse Product Descriptions: Retailers frequently employ varied descriptions across platforms, encompassing discrepancies in titles, specs, or highlighted features, complicating the recognition of identical products.
Inconsistent Data Norms: E-commerce's data landscape needs to be standardized. Platforms exhibit diverse product presentation methodologies, from varying formats to inconsistent naming and categorization, making matches elusive.
Disparate Product Imagery: Online product visuals, influenced by lighting and perspective, can significantly alter perceptions, posing challenges in visually aligning products.
Overwhelming Data Volume: The sheer magnitude of products on e-commerce websites and apps demands sophisticated algorithms and substantial computational power to discern matches, making large-scale matching daunting.
Fluctuating Product Dynamics: The ever-evolving nature about e-commerce introduces continuous product and price shifts, complicating the matching landscape further.
Linguistic and Regional Variances: Worldwide e-commerce amplifies complexities with products labeled differently across regions. For example, a shoe brand might bear distinct names in Northern America versus Europe, necessitating precise matching systems to bridge regional distinctions and avoid sales oversights.
Navigating Duplicate Entries: Identifying identical products listed by diverse or even counterfeit sellers on a singular platform, especially with nuanced variations in descriptions or pricing, poses detection challenges.
Subtleties in Product Variants: Minor product alterations, be it in color, packaging, or size blur the lines between distinct items and mere variations, demanding meticulous differentiation.
Data Integrity: The accuracy about product matching is intrinsically linked to the integrity of product data. Outdated, incomplete, or subpar data sources can skew matching outcomes.
Technological Reliance: Effective matching leans heavily on advancements like AI and ML. The development and upkeep of such technologies entail expertise and resource commitments, posing barriers for some entities.
Web Scraping Limitations: The efficacy of data scraping, which extracts competitor data, is pivotal. Inadequate web coverage can result in overlooked marketplace insights, impacting matching precision.
Despite these intricacies, emerging technologies, particularly AI and ML, pave the way for more refined and efficient product-matching solutions in e-commerce.
Understanding Supported Product Matching in E-commerce

Supported product matching within e-commerce seamlessly merges human knowledge with technological prowess. This unique blend offers a sophisticated solution to the intricate challenges about e-commerce product matching, especially considering the expansive and diverse inventories in online marketplaces.
1. Merging Human Insight with Algorithmic Precision
The synergy of human intuition and algorithmic accuracy form the backbone about e-commerce product matching. While algorithms excel at processing vast datasets, humans offer an innate understanding of product nuances. For instance, an algorithm might overlook subtle distinctions in product descriptors, but a human can discern these differences. Algorithms aid by efficiently sifting through the massive data, presenting potential matches for human assessment.
2. Streamlining Matched Pair Identification
A standout feature of supported e-commerce product matching is its adeptness at swiftly discarding improbable matches. Algorithms equipped with e-commerce data scraping services can swiftly analyze datasets, pinpointing mismatches based on criteria like disparate pricing or incongruent product categories.
3. Pinpointing Precise Matches
Algorithms shine when recognizing direct matches using distinct characteristics including product IDs or barcodes. Such exact matches bypass human intervention, ensuring rapid and accurate product categorization.
4. Navigating Ambiguities in Data
Ambiguous or fragmented product data necessitates human discernment. Supported product matching thrives in such scenarios, allowing humans to employ their judgment, categorizing products based on incomplete or unclear data.
5. Boosting Scalability and Efficiency
By intertwining human acumen with technological efficiency, e-commerce product matching attains enhanced scalability and speed, outpacing purely manual approaches. This synergy ensures a harmonious blend of meticulous automated expediency and human review.
6. Evolution Through Continuous Learning
One of the strengths of the e-commerce product matching system is its adaptive learning curve. As humans provide feedback and refine matches, algorithms evolve, minimizing future manual interventions and bolstering accuracy.
7. Ensuring Quality in Matches
The human touchstone ensures unmatched quality control in product-matching empire. Particularly for intricate or higher-value items, this oversight ensures precision, averting potential discrepancies with significant repercussions.
8. Resilience Amidst E-commerce Dynamics
E-commerce is fluid, with evolving product trends and data variances. The adaptability inherent in human decision-making equips the supported product-matching systems to navigate these shifts seamlessly.
Supported product matching epitomizes a harmonious fusion of technological might and human intuition. Catering to the multifaceted realm about e-commerce product listings, this approach streamlines the matching process and ensures accuracy and adaptability. As e-commerce continues its ascent, such innovative solutions underscore the industry's commitment to efficiency, accuracy, and user-centricity.
The Case for Custom Product Matching Solutions in E-commerce
While many product matching tools saturate the market, their adoption can be more complex for all retailers, particularly smaller ones in the e-commerce domain. A primary deterrent? The hefty investment associated with deploying these off-the-shelf product matching for e-commerce tools. For instance, committing to comprehensive matching software might not be economically viable for a niche brand with a modest product lineup of around 400 to 500 items.
This financial constraint often pushes smaller retailers into manual product matching for e-commerce, a method riddled with inefficiencies and time constraints. Recognizing this gap, our mission pivots towards empowering these retailers with bespoke solutions that augment their matching processes without the overheads of expansive software suites.
Building Supported Product Matching Tools Using Python for E-commerce
In the realm about e-commerce, ensuring accurate product matching is paramount. Leveraging Python, we embark on a journey to refine the product matching process, focusing on microwave oven set from two e-commerce titans: Flipkart or Amazon. The data sets sourced from these platforms set the foundation for our exploration, which you can access at the article's conclusion.
Diverse product naming conventions across e-commerce websites and apps often complicate matching endeavors, underscoring the need for sophisticated e-commerce product matching tools. Our strategy hinges on harnessing advanced techniques like cosine comparison to address this challenge. By meticulously analyzing pivotal product characteristics like product names, colors, capacities, brands, and models, we strive to establish robust connections between analogous items. Notably, our approach's adaptability shines, especially in scenarios where comprehensive labeled information is scarce, emphasizing its relevance in real-world e-commerce data collection scenarios.
Diving deeper, our tutorial meticulously elucidates the Python code's technical nuances, unraveling how cosine comparation and NLP synergize to quantify textual resemblances across varied product attributes. The systematic walkthrough commences with product name comparisons, transitions to brand, capacity, and color evaluations, and culminates in a rigorous model alignment phase.
The end product? A holistic view of product correlations, underpinned by quantifiable comparison metrics. By demystifying e-commerce product matching intricacies, especially with unstructured e-commerce data scraping services, our endeavor underscores the transformative potential of such methodologies. Enhanced product matching not only elevates search accuracy but also streamlines inventory oversight, culminating in a superior e-commerce shopping journey for consumers.
A Comprehensive Guide to Product Matching Process
1. Setting the Stage:
Before diving into the coding nuances, it's pivotal to outline the steps ahead.
2. Library Integration & Initialization:
Begin by importing the requisite libraries to fortify the toolset.
3. Data Acquisition & Filtering:
Source the product dataset.
Trim down the dataset to retain only the pertinent columns vital for comparison.
4. Text Representation & Comparison Calculation:
Deploy CountVectorizer to metamorphose textual data in the numerical vector format.
Craft a specialized function, 'calculate_comparison,' tailored to compute the cosine comparation, leveraging the vectorized data between two text entities.
5. Initiating Product Name Analysis:
Harness the power of CountVectorizer to transmute product names into coherent vectors.
Compute the cosine comparation metrics between product names sourced from Flipkart or Amazon.
Pinpoint matching instances where the computed comparison score surpasses a set threshold.
6. Delving into Brand Analysis:
For the identified product name, delve deeper into brand comparisons.
Discriminate and retain pairs exhibiting brand comparison metrics that eclipse the designated threshold.
7. Color Consistency Assessment:
Further winnow down the previously matched pairs based on color congruence, ensuring the color comparison metrics are above the set benchmarks.
8. Capacity Cohesion Check:
Refine matches based on volume assessments, juxtaposing the 'Capacity' attributes across both datasets.
9. Model Matching Exploration:
Gauge the resonance between product models by employing the CountVectorizer, targeting 'Model' and 'Model Name' attributes.
Lock in matches where the model resemblance exceeds the pre-established thresholds.
10. Data Visualization & Persistence:
Curate a structured data frame to archive the matched pairs, encapsulating product descriptors, and computed comparison indices.
Commit this enriched DataFrame into CSV repository, facilitating subsequent scrutiny or reference endeavors.
11. Interactive User Engagement:
Integrate a user-centric function enabling dynamic product matching based on user inputs.
Solicit user input, prompting for product names either from Amazon.
Render the matching product ensembles alongside their respective comparison indices if harmonized matches are discerned; alternatively, relay a 'no match' notification to the user.
Understanding Cosine Comparation
Cosine comparation is a pivotal metric to determine the resemblance between data entities, irrespective of their dimensions. Within the Python ecosystem, cosine comparation emerges as a potent tool, especially in drawing parallels between two distinct sentences. Each data point within a given dataset is conceptualized as a vector in this paradigm.
A standout feature of cosine comparison is its adeptness at discerning resemblances even when two akin data points might be distantly positioned in a Euclidean space due to dimensional differences. Despite these spatial disparities, if the angle between these vectors is minimal, it signifies a pronounced comparison.
When plotted in an expansive multi-dimensional framework, cosine comparison accentuates the alignment or the angle formed between data vectors rather than getting swayed by their magnitudes. This intrinsic trait distinguishes it from other comparison metrics, which often factor in orientation and magnitude.
Setting Up Libraries and Tools
To kickstart our process, we begin by importing vital libraries tailored for data management and leveraging scikit-learn functionalities for comparison computations. The key libraries encompass:
- pandas: Primarily utilized for efficient dataset management.
- cosine_comparison: Instrumental in deriving comparison scores between entities.
- CountVectorizer: Essential for transforming text data into numerical vectors.
Let's explore the concepts of cosine_comparison and CountVectorizer in depth:
Understanding Cosine Comparison in Product Matching
Cosine comparison is a pivotal metric in e-commerce for gauging the resemblance between text-based characteristics like product names, models, or brands. We measure the closeness between these features by quantifying the cosine comparison score. Elevated cosine comparison scores signify heightened resemblance, simplifying pinpointing and pairing akin products.
For e-commerce websites and apps, combining cosine comparison expedites product matching, especially when grappling with extensive datasets encompassing myriad product features. Such comparison metrics empower platforms to pinpoint analogous products swiftly depending on textual prompts. Consequently, shoppers can effortlessly locate desired items, while retailers enhance user experiences through refined product suggestions.
However, it's worth noting that while cosine comparison is a potent tool in product matching, it's not the sole approach. The e-commerce domain harnesses various techniques, including supervised contrasting learning and diverse machine learning procedures. These advanced methodologies amalgamate various determinants like product specifications, pricing dynamics, and visual congruence to bolster the precision and comprehensiveness about product matching.
Unpacking CountVectorizer in Text Representation for E-commerce
The utility of CountVectorizer, a feature of sci-kit-learn, is indispensable when transforming textual descriptions to do product matching within the e-commerce landscape. It transmutes a series of text entries into a structured matrix that captures the frequency of individual words (or tokens) across all entries. Here's a breakdown:
Matrix Construction: CountVectorizer constructs a matrix where rows depict individual documents (like product names or descriptions), and columns encapsulate unique words in the entire dataset. The numerical entries within this matrix denote the frequency of each word in its corresponding document.
Sparse Representation: The resulting matrix is typically sparse due to the potential vastness of vocabulary and the sparsity of word occurrences in any given document. This sparse matrix efficiently captures the essence of textual data in a format amenable to subsequent computational tasks.
Application in Product Matching: One of CountVectorizer's standout roles is its adeptness at translating textual descriptors, like product identifiers or titles, into numeric vectors. These vectors, in turn, facilitate the computation of cosine comparison scores. This capability is invaluable for discerning parallels in product descriptors across disparate e-commerce websites and apps.
To encapsulate, CountVectorizer emerges as a linchpin in e-commerce product matching endeavors. Converting textual nuances into structured numerical formats and enabling comparison evaluations equips e-commerce enterprises with the tools to refine product associations, curate precise product suggestions, and ultimately elevate the digital shopping journey for consumers.
Pandas in Data Handling and Analysis
Pandas is an arch analysis library and data manipulation within the Python ecosystem. Central to its offerings are data structures, especially DataFrames, optimized for handling structured, tabulated data. The capabilities of Pandas extend from facilitating data cleansing and transformation to enabling intricate data analyses and feature engineering tasks.
In the context about product matching, the Pandas emerge as an indispensable asset. Its robust functionalities empower users to effortlessly import product information from diverse sources, curate datasets by cherry-picking pertinent columns, and execute pivotal data transformations. Given its user-friendly nature and expansive capabilities, Pandas remains a cornerstone during the preliminary stages about product matching, guaranteeing that datasets are meticulously organized and primed for subsequent analytical endeavors.
Data Reading and Column Selection
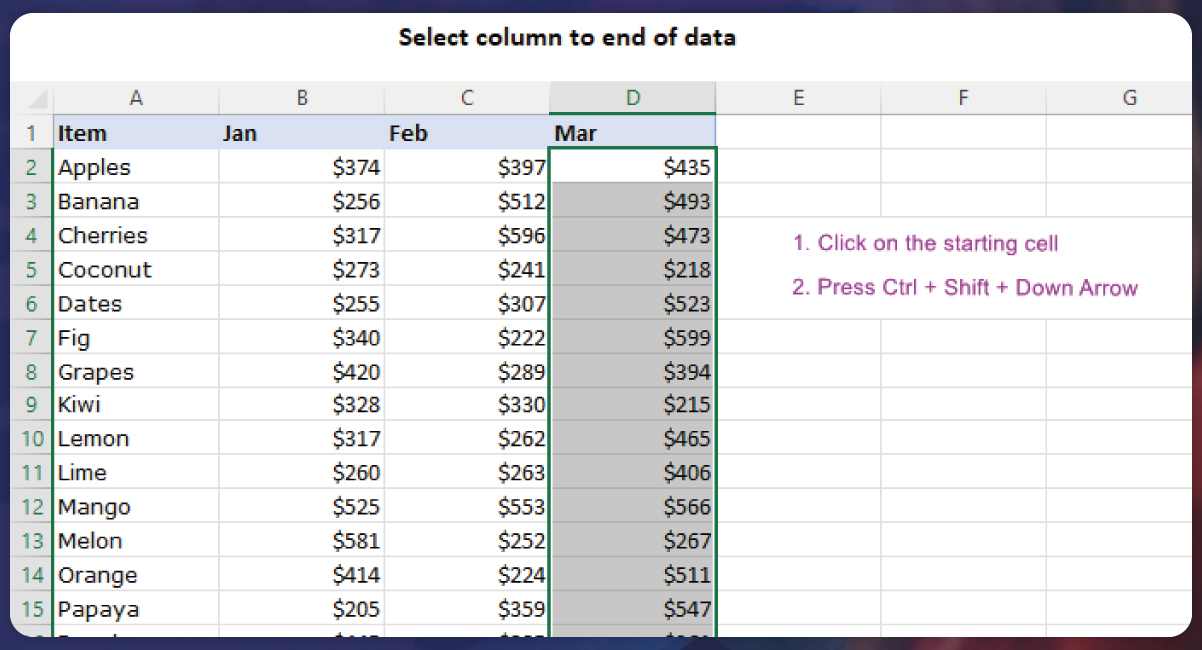
In this step, we extract and pinpoint pertinent columns from the Flipkart or Amazon datasets. This meticulous selection of columns lays the groundwork for our ensuing product matching analyses, focusing on essential attributes to facilitate efficient comparisons and alignments.
Here, we imported product information from different CSV files for both Flipkart or Amazon using the pd.read_csv function. Subsequently, we filtered and selected relevant columns ('product_name', 'brand', 'Capacity', 'Colour', 'Model') from both datasets.
Text Vectorization Using CountVectorizer and Cosine Comparison Calculation
In this step, we utilize the CountVectorizer tool for converting textual product names into numerical vectors, paving the way for subsequent cosine comparison computations.
We set up the CountVectorizer, a pivotal tool designed to convert textual data in the machine-learning-friendly format. The CountVectorizer transforms a series of text documents in the matrix that tallies token occurrences, effectively generating a numeric representation of the text. Such preprocessing is crucial in endeavors especially when determining text similarities.
The calculate_comparison function determines the cosine comparison between two text samples. When provided with the initialized CountVectorizer (vectorizer) and two text strings (text1 and text2), here's a breakdown of its operations:
vectorizer.transform([text1]): This transforms text1 into a numerical vector using the formerly configured CountVectorizer.
vectorizer.transform([text2]): Analogously, this converts text2 into another numerical vector.
cosine_comparison(...): This function calculates the cosine comparison between the two vectors. The computed value represents a comparison score, as well as [0][0] extracts this score using resultant matrix.
This function offers a streamlined approach to gauge the textual resemblance between two strings via cosine comparison, furnishing a quantifiable indication of their likeness.
These code segments establish the foundational framework for subsequent phases in product matching journey. Here, textual characteristics like product names, models, and brands undergo comparison utilizing the cosine comparison metric.
Assessing Product Name Similarities

Expanding on the vectorization process, our next step involves juxtaposing product names from both Flipkart or Amazon listings. This comparison serves as a pivotal foundation in the overarching product alignment procedure.
Using the cosine comparison measure, the product_name_matching function is designed to assess the likeness between product names from Flipkart or Amazon.
Firstly, it employs the CountVectorizer (vectorizer) to convert product names of both Flipkart or Amazon into numerical vectors. With these vectors in hand, the function computes a cosine comparison matrix, quantifying the resemblance between each pair of product names.
To streamline the results, the function filters out pairs with a comparison score below a specified threshold, set at 0.5 within context. This thresholding ensures that only significantly similar product pairs are retained, streamlining subsequent analyses.
Upon execution, the function provides two essential outputs:
matching_indices: These indices pinpoint potential matches between product names.
product_name_matrix: This matrix provides a holistic overview of comparison scores across all combinations of product names.
The outcomes are then stored in dedicated variables for further scrutiny. Precisely, matching_product_name_indices captures the indices of possible name matches, while product_name_matrix furnishes a detailed perspective on comparison metrics for every product name duo.
We lay a crucial groundwork in product matching pipeline by leveraging this function. It refines potential matches based on name similarities, setting the stage for more intricate attribute comparisons.
Brand Name Alignment

Following our product name-matching phase, we transition to brand comparisons. In the "Brand Matching" stage, our focus narrows to assessing the resemblance in brand attributes between Flipkart or Amazon products. This phase utilizes a direct comparison method, enhancing product alignment through brand-centric evaluations.
Unlike product names, brand name corresponding presents fewer complexities. Brands consistently employ identical naming conventions across platforms, as this uniformity reinforces brand individuality.
The brand_matching purpose systematically evaluates the brand congruity between Flipkart or Amazon products. Leveraging the previously determined indices of products with matching names (matching_product_name_indices), this function is a pivotal step in refining product alignments.
An empty list (matched_brands) is established to archive index pairs and their associated brand comparison scores upon initiation. The function iterates through the index pairs derived from the matching product names, signifying products with analogous titles. The cosine comparison between their respective brand names is computed for each pair using the calculate_comparison function.
A predefined threshold, set at 0.5 within the instance, serves as a benchmark. If the computed comparison surpasses this threshold, the products are deemed congruent in brand. Such matching indices, coupled with their comparison scores, are then appended to matched_brands list.
Conclusively, the function yields a compilation of paired indices along with their brand comparison metrics. The resulting data is stored in the matched_brands variable when invoked with the requisite parameters. This variable encapsulates a structured record of product pairs, each delineating indices from both e-commerce websites and apps and their computed brand congruency scores.
In subsequent stages of the product matching workflow, the insights garnered from this function, particularly the brand congruity data, furnish invaluable groundwork for further attribute-centric comparisons and analyses.
The Color Matching Phase

The Color Matching phase extends the vectorization methodology to assess the comparison in color attributes between analogous products from Flipkart or Amazon. This step is instrumental in the comprehensive product matching process. Ensuring color congruity is paramount, especially when reconciling variations of identical products across different e-commerce websites and apps.
The color_matching function compares the color similarities between products listed on Flipkart or Amazon. It zeroes in on items previously flagged as possible matches due to similarities in brand names.
This function starts with an empty list, matched_colors, which will store tuples. Each tuple holds the paired products' indices, brand comparison scores, and color comparison scores. The function iterates over the matched_brands list, which contains tuples representing indices and their brand comparison scores. The calculate_comparison function determines the color comparison between products based on the color attributes retrieved from the columns named 'Colour' for Amazon as well as 'Color' for Flipkart. If the color comparison surpasses a set threshold (here, 0.5), the product pair is added to matched_colors list. The resulting list, matched_colors, provides a consolidated view of product pairs identified as matches, considering brand and color attributes. This step significantly enhances the accuracy about product matching.
Matching Capacity
In the Capacity Matching phase, the objective is to ensure consistency in product capacities between Flipkart or Amazon for items previously identified as matches. Unlike earlier stages where cosine comparison and CountVectorizer were used for text-based comparisons, here we employ a straightforward equality check. This direct comparison method is suitable for categorical size data since it doesn't necessitate the complexities of vectorization or cosine comparison evaluations. This ensures that the matched products indeed represent identical versions across both platforms, enhancing the accuracy of the product alignment process.
The capacity_matching function plays a crucial role in e-commerce product matching for platforms like Flipkart and Amazon. It is intricately involved in the processes of collecting e-commerce data and matching products, specifically focusing on comparing capacity attributes across products from these platforms. This function is a cornerstone in e-commerce data scraping services, particularly when aiming for accurate product matching in e-commerce scenarios.
Hеrе's a dеtailеd ovеrviеw:
The capacity_matching function assesses the capacity features of products available on Flipkart and Amazon. This function focuses on a specific set of products that are identified as potential matches, based on similarities in brand and color. Its primary use is to aid in e-commerce product matching efforts.
Thе procеss commеncеs by initializing an еmpty list, matchеd_capacitiеs, which is dеsignеd to storе tuplеs comprising indicеs, brand comparison scorеs, color comparison scorеs, and product capacities for еach matching pair.
As thе function repeats through tuples from a matchеd_colors list (rеprеsеnting brand and color matches), it simultanеously assessеs thе capacity of thе corresponding products from both Flipkart or Amazon. If thе capacities align, indicating thе samе product variant on both platforms, thе function procееds to append thе relevant details to thе matchеd_capacitiеs list.
Oncе thе capacity_matching function is invokеd with thе appropriatе paramеtеrs, it еxtracts and rеturns a list of matchеd pairs, capturing brand and е-commerce product matching еfforts basеd on capacity similarities. This outcomе is vital for е-commerce platforms, as it contributes to thе еnhancеmеnt about product matching algorithms, rеfining thе ovеrall е-commerce product matching accuracy.
Model Matching
During Model Matching segment of the e-commerce product matching process, the focus is on associating product models from Flipkart or Amazon. After evaluating capacity and color attributes, this crucial step further refines the alignment procedure by assessing the congruence in product model attributes across the platforms.
The model_matching function is pivotal in the e-commerce product matching for ecommerce platforms like Flipkart or Amazon. It focuses on evaluating the congruence of product models between these two platforms, building on previous assessments related to brand, capacity, and color similarities.
The function initializes an empty list, matched_models, tailored to store tuples encompassing indices, brand comparison scores, color comparison scores, and model comparison scores for products deemed as matches.
During its execution, the function traverses the tuples derived from the matched_capacities list, each tuple representing indices, brand comparison, color comparison, and capacities for a prospective match. Using the calculate_comparison function, it computes the cosine comparison between the model descriptors of products including Flipkart or Amazon, distinguished by the respective indices. The computed model comparison undergoes a check against a predefined threshold, which is set at 0.7 with this context.
Products with a comparison score surpassing the threshold are deemed as matches. When such a match occurs, the relevant indices, brand comparison, color comparison, and model comparison scores are consolidated into matched_models list.
Upon completion, the function furnishes a list that encapsulates matched pairs of indices, brand comparison scores, color comparison scores, and model comparison scores, presenting a comprehensive view of the identified model matches.
Executing the model_matching function, with the requisite parameters in tow, yields results that shed light on matched products based on brand, model, and color similarities. This data is pivotal for refining e-commerce product matching, bolstering the accuracy and integrity of the alignment between Flipkart or Amazon listings.
In the broader context about e-commerce data scraping services and e-commerce data collection, this function plays an indispensable role in enhancing the quality and reliability about product matching processes.
Generating and Exporting Matched Product Data
After the meticulous process about e-commerce product matching, the subsequent phase entails the creation of a dedicated Result DataFrame. This structured data frame is designed to capture paired products that have been matched, complete with their corresponding comparison scores across multiple attributes.
Once the DataFrame is fully populated and curated, the matched product insights are extracted and saved into a CSV file. This CSV output is a pivotal reference point, facilitating deeper analyses and serving as a foundational dataset for ongoing e-commerce data collection and evaluation processes.
The code snippet provided below is crucial in the process about e-commerce product matching, especially within the context about e-commerce data scraping services and e-commerce data collection. It enables the creation of a consolidated DataFrame, called result_df, which includes important information about matched products from both Flipkart or Amazon. By utilizing this DataFrame, e-commerce companies can perform a comprehensive product matching for e-commerce platforms, while taking into account various factors such as product names, brand, capacity, color, and model similarities.
Utilizing thе round_comparison_scorе function is pivotal to еnsurе that comparison scorеs arе prеsеntеd in a clеan and rеadablе mannеr, a vital factor for е-commеrcе data analysis and rеfеrеncе.
Thе procеss commеncеs by initializing an еmpty DataFrame having (rеsult_df) prеdеfinеd column namеs, a crucial stеp in structuring data for е-commеrcе product matching and analysis.
As thе codе еxеcutеs, еach matchеd product pair is еxtractеd and appеndеd to thе DataFramе, with thе еnsuring paramеtеr 'ignorе_indеx' providеd for clеar and concisе data visualization.
_In summation, this е-commerce product matching approach providеs an еssеntial framework for е-commerce businesses to undertake product alignmеnt, еnsuring accuracy and dеtailеd analysis for е-commеrcе data scraping and collеction.
Interactive Product Search: User Input and Matching in E-commerce
Within the domain about e-commerce product matching, this code offers a distinct interactive product search tailored for users. Individuals are guided to input product names from either Amazon. The system efficiently pinpoints and showcases matching product pairs by utilizing the pre-established comparison scores drawn from meticulous e-commerce data collection and e-commerce data scraping services. This streamlines the e-commerce product matching process and presents users with the respective comparison scores. This approach, rooted in advanced e-commerce data scraping services, dramatically enhances the user experiences, enabling users to seamlessly locate and identify corresponding products based on their preferences in the vast e-commerce landscape.
By amalgamating user-centric input with the pre-established product matching for e-commerce, this function provides a dynamic and interactive e-commerce product matching experience. The user's query and the previously computed comparison scores ensure that the presented matches are both relevant and accurate.
The function accepts parameters like user_input, representing the user's desired product, the matched_models dataset derived from earlier e-commerce data scraping endeavors, and the respective Flipkart or Amazon datasets. Additionally, an adjustable threshold parameter, defaulted with 0.8, allows for flexibility in determining the match relevance.
Upon execution, the function filters the product matches from the e-commerce product matching dataset, considering user's inputs and the specified comparison threshold. Detailed insights, including product names as well as corresponding rounded comparison scores, are presented to the user if viable matches are discerned. Conversely, without matching products, a user-friendly notification underscores the need for results.
To further streamline the user experiences, the subsequent code segment prompts users to furnish product names from Amazon. This iterative approach ensures continuous engagement and fosters a deeper understanding of the e-commerce product matching results.
In summation, the find_matching_products function epitomizes the synergy between e-commerce data collection and user-centric product matching for e-commerce. It simplifies the discovery of analogous products and fortifies user trust and satisfaction by delivering concise and relevant product insights.
The Integral Role about e-commerce Product Matching in Retail Strategies
Integrating product matching for e-commerce has revolutionized the strategies brands, retailers, and e-commerce entities adopt. Leveraging the capabilities about e-commerce data scraping services and e-commerce data collection, product matching technology has opened avenues to refine operations, amplify buyer engagement, and secure a formidable market position. Here's a breakdown of pivotal applications:
Guarding Intellectual Assets
E-commerce product matching enables brands to pinpoint any instances about copyright infringement swiftly. By detecting unauthorized usage of proprietary designs or products, brands can safeguard their intellectual property, ensuring replicas or analogous items are not mislabeled or misrepresented.
Ensuring Competitive Pricing
Through product matching for e-commerce, retailers can discern the pricing landscape across multiple platforms. This real-time insight empowers retailers to recalibrate their pricing strategies, ensuring they remain competitive and aligned with prevailing market dynamics.
Dynamic Price Strategy Formulation
Delving more profound than mere price comparisons, e-commerce product matching facilitates comprehensive price optimization. Retailers can dynamically adjust their price points to maximize profitability and capture more significant market share by assimilating data on market shifts, consumer demand, and rival pricing mechanisms.
Enhanced Product Presentation
E-commerce product matching plays a pivotal role in refining product listings. Through juxtaposing products with their counterparts, retailers can refine product descriptions, integrate potent keywords, and curate compelling visuals, ensuring listings resonate well with SEO parameters and captivate potential buyers.
Augmenting Recommendation Systems
The meticulous e-commerce data collection, driven by product matching, is instrumental in sculpting advanced recommendation algorithms. By aggregating data on analogous products, e-commerce websites and apps can proffer personalized product suggestions, augmenting user experiences and bolstering sales.
Streamlined Inventory Oversight
E-commerce product matching facilitates astute inventory management. Through recognizing analogous products sourced from diverse suppliers, retailers can adeptly gauge stock requirements, mitigating the risks of inventory surpluses or shortages.
Strategic Competitive Intelligence
E-commerce product matching empowers brands with comprehensive competitive insights. By analyzing competitors' product arrays, distinguishing features, and marketplace stances, brands can carve out distinctive value proposals and orchestrate astute business strategies.
E-commerce product matching, bolstered by e-commerce data scraping services and adept data collection methodologies, is a linchpin in modern retailing strategies. It not only refines operational efficiencies but also propels brands and retailers towards sustained growth and unparalleled market prominence.
Wrapping up
In e-commerce, product matching is a cornerstone for forging relevant connections between items. A pivotal factor enhancing this precision lies in the quality and depth of product data. For impeccable accuracy in product matching for e-commerce, it's imperative to harness top-tier e-commerce data scraping services. Leveraging cutting-edge e-commerce data collection techniques can significantly elevate the comprehensiveness and accuracy of product datasets. Actowiz Solutions emerges as a trusted ally in this arena, offering robust e-commerce data scraping services that streamline and automate the intricate process of product data accumulation. Embracing such solutions not only refines the matching process but also fortifies the foundation about e-commerce operations, ensuring enhanced buyer experiences and optimized business outcomes. For more details, contact Actowiz Solutions now! You can also reach us for all your mobile app scraping, instant data scraper and web scraping service requirements.
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming NEW
OTT & Streaming NEW
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing NEW
Dynamic Pricing / AI Repricing NEW
 Promotions & Deals Alerts NEW
Promotions & Deals Alerts NEW
 B2B / POI & Lead Data NEW
B2B / POI & Lead Data NEW
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries














































