
In this comprehensive blog guide, we will go through the procedure of extracting Amazon product data using data scraping methods with Python. Web scraping is pivotal in gathering crucial data for AmazInvest, an Amazon investment app. By following this step-by-step guide, you will gain the knowledge to extract the necessary data for making informed investment decisions.
Web scraping is an automated data extraction technique to gather information from websites. Within AmazInvest, web scraping enables us to collect comprehensive product data such as pricing, ratings, competition scores, and customer reviews. This wealth of information is essential for evaluating investment prospects on the Amazon platform.
Throughout this blog guide, we will explore the significance of web scraping in building AmazInvest and how it empowers users to make intelligent investment decisions. By using data scraping methods, you will unlock valuable insights to help guide your investment strategies and maximize your potential returns on Amazon.
Join us as we delve into the world of web scraping and equip you with the skills to extract product data from Amazon for AmazInvest. Prepare to enhance your investment analysis and adopt a data-driven approach to Amazon investment opportunities.
Web Extraction For AmazInvest:
Web scraping holds immense significance in the development of AmazInvest, as it enables us to gather real-time data from Amazon, a prominent and dynamic marketplace. Automating the data collection process saves valuable time and effort, granting users effortless access to up-to-date product information. This wealth of data is the bedrock for analyzing investment opportunities, evaluating market competitiveness, and gaining insights into customer sentiment through reviews.
With web scraping, investors are empowered with a comprehensive toolset to assess and evaluate investment prospects on Amazon. By leveraging detailed product data, users can make well-read decisions depending on objective metrics like ratings, pricing, and competition scores. Furthermore, sentiment analysis on customer reviews unveils valuable insights into product reception and customer satisfaction, adding a layer of intelligence to the decision-making process.
Are you ready to embark on a thrilling web scraping journey in Python? Join us as we explore the realms of web scraping and equip you with the skills to extract and analyze data from Amazon for AmazInvest. Get ready to unlock the potential of real-time information and elevate your investment strategies to new heights. Let's dive in and harness the power of web scraping for AmazInvest!
Step 1: Set Up a Web Driver
Web scraping relies on a dedicated tool to interact with websites and retrieve data. To kickstart the web scraping process, we must utilize a web driver, which acts as a programmatically controllable browser. It allows us to navigate websites, perform searches, and extract the desired data.
For our AmazInvest web scraping, we will leverage Selenium's ChromeDriver. This driver allows us to control a web browser and carry out automated actions. By configuring the web driver, we establish a connection to the Amazon website, enabling seamless navigation and extraction of valuable information.
To set up the web driver in the code, you can import essential libraries and configure Chrome web driver through following snippet:
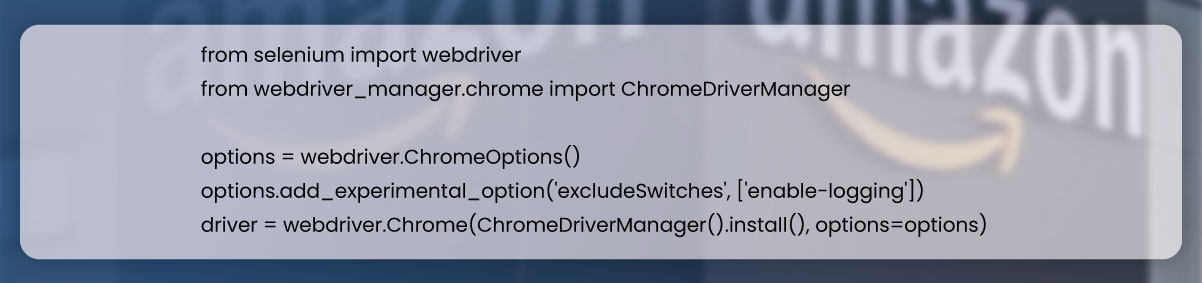
To initiate the web scraping process, we begin by importing the necessary libraries. We then configure Chrome options to exclude any unnecessary logging and finally, initialize the Chrome driver using ChromeDriverManager.
By excluding unnecessary logging from Chrome options, we improve the efficiency of our web scraping efforts. This reduces unnecessary output and declutters the log files, leading to enhanced readability of the logged information pertaining to the scraping process.
Step 2: Navigate to Amazon Website and Search Products
To extract product data from Amazon, the first step is to navigate to the website and perform a search. In the case of AmazInvest, we are interested in searching for products relevant to our investment analysis. To provide flexibility, we will work with all product categories, permitting a user to select specific category they want to invest in and retrieve corresponding product data.
In this example, let's assume we are scraping data for the "Laptops" category. In the code, open Amazon website and wait for page loading, enter a search query, and click search button through given snippet:

In the provided code snippet, we interact with the Amazon website by accessing it, providing a search query (in this case, "laptops"), locating the search box element, inputting the query, and clicking the search button. This action allows us to retrieve the search results page containing the products of interest.
Handling possible delays due to page loading and other elements on a website is important. To address this, it is recommended to employ techniques such as waiting for a specific element to look or implement clear wait times. These practices make sure that the required elements are loaded before happening with data scraping.
Please note that the following code snippet is a partial representation and assumes that the required import statements and variable definitions have been included in your script:
Step 3: Extract Product Data
Now we reach the core of the web extraction procedure: scraping the applicable product data from search results. In the AmazInvest project, our goal is to gather information such as product names, prices, ratings, and other relevant details for investment analysis.
To extract this data, we can utilize techniques such as locating specific elements on the page, extracting their text or attribute values, and storing them in variables or data structures. The exact implementation may vary depending on the structure of the Amazon search results page and the specific data elements you want to extract.
What’s an XPATH?

The code snippet follows a loop-based approach to iterate through the search results and collect the desired information. Here's an overview of the steps involved:
Locating elements that represent every product:

Scrape product names, prices, ratings, and other applicable data:

By locating any precise elements within HTML structure of every product, we can scrape the required data to do analysis. Please note that you may need to adjust the XPath expressions based on the structure of the Amazon search results page. Here's an example snippet that demonstrates how to extract product names, ratings, and prices using XPath expressions:
PAGINATION?

The extracted data should be stored in variables or data structures for later use in Step 4. You can create variables to hold product names, ratings, prices, and other relevant information. Additionally, you can use data structures such as lists or dictionaries to store the data for multiple products. Here's an updated code snippet that demonstrates how to store the extracted data in variables and a list:
Step 4: Save the Scraped Data
When the data gets scraped, it is important to save that for more analysis. In AmazInvest, we have saved the scraped data in the Excel file, giving a well-structured format which can be processed easily and analyzed. By saving the data, we create a valuable resource which empowers investors for exploring investment opportunities, comparing products, and making informed decisions based on reliable information.

When the data gets scraped, it is important to save that for more analysis. With AmazInvest, we have saved the scraped data in the Excel file, providing a structured format that can be easily processed and analyzed. By saving the data, we create a valuable resource which empowers investors in exploring investment opportunities, comparing products, and making well-informed decisions based on reliable information.
To save the extracted data as an Excel file, we can use the pandas library in Python.
Considerations and Challenges
In the provided code snippet, we import all necessary libraries, configure Chrome options for excluding needless logging and initialize Chrome driver through ChromeDriverManager.
By excluding unnecessary logging from the Chrome options, we optimize the efficiency of our web scraping process. Dropping needless outputs and clutters in log files enhances the readability of the logged information related to the scraping process.
To implement this in your code, install the required libraries, including Selenium and ChromeDriverManager. Customize the Chrome options as needed, and feel free to add additional arguments to suit your specific web scraping requirements.
Data Validation and Quality
Data quality is crucial in web scraping as it directly impacts the accuracy and reliability of the analysis performed in AmazInvest. To ensure data quality and validation, it's important to follow these techniques and best practices:
Data Validation: Implement validation checks to ensure the integrity of the extracted data. Validate different fields like product names, prices, ratings, and other important information to make sure consistency and correctness. Use techniques like data type checking, regular expressions, or assessment with identified values to validate the extracted data.
Dealing with Incomplete or Missing Data: Data scraping might encounter examples where data is incomplete or missing. Implement tactics to deal with these situations efficiently. Consider setting default values for missing data, skipping incomplete records, or attempting to fetch missing data from alternative sources if available.
Error Recognition and Handling: Observe the scraping procedure for anomalies or errors. Use error handling mechanisms for capturing and handling errors effectively. Set up error logging to capture error details, allowing for analysis and troubleshooting. Consider implementing retry mechanisms to handle temporary errors, implementing logging mechanisms to track errors, or setting up automated notifications to address errors promptly.
Data Consistency Checks: Perform consistency checks on the extracted data to identify any discrepancies or inconsistencies. Compare data across multiple sources or time periods to ensure data accuracy and consistency. Implement algorithms or checks to identify and flag any outliers or data anomalies that may affect the analysis.
Data Cleaning and Transformation: Preprocess and clean the extracted data to remove any unwanted characters, symbols, or formatting inconsistencies. Standardize data formats, units, or naming conventions to ensure consistency in the analysis. Use techniques like data normalization, deduplication, or data transformation to ensure data quality.
Continuous Monitoring and Maintenance: Web scraping requires ongoing monitoring and maintenance to address any changes or updates in the target website's structure. Regularly review and update scraping scripts or rules to adapt to website changes. Monitor the quality and accuracy of the extracted data over time and make necessary adjustments as needed.
By following these techniques and best practices, you can ensure data quality in web scraping for AmazInvest. This will result in more accurate and reliable analysis, enabling informed investment decisions based on trustworthy information.
Performance and Scalability Optimization
As the volume of data increases, optimizing the web scraping process for scalability and performance becomes crucial. Here are some strategies to consider:
Parallel Processing: Parallel processing is a technique that involves dividing the scraping tasks into multiple parallel processes or threads. By doing so, multiple requests can be handled concurrently, leading to a substantial improvement in the data extraction process and overall performance. This approach allows for simultaneous execution of scraping tasks, reducing the time required to retrieve data from the target website. Consequently, it enables faster and more efficient extraction of data, enhancing the scalability and responsiveness of the web scraping system.
Distributed Computing: In scenarios where the scraping workload is substantial, it is advantageous to adopt a distributed computing approach by distributing the workload across multiple machines or servers. By leveraging distributed computing frameworks such as Apache Spark or Kubernetes, businesses can effectively divide the scraping tasks among multiple nodes, maximizing efficiency and performance. This distributed setup allows for parallel processing on a larger scale, enabling faster data extraction and analysis. It also offers the flexibility to scale resources horizontally by adding more machines or servers as the workload grows, ensuring optimal performance even with increasing data volumes. Ultimately, distributed computing empowers organizations to handle large-scale web scraping tasks efficiently and effectively.
Code Optimization: To achieve improved performance in web scraping, it is essential to optimize the code by implementing various techniques. These techniques include optimizing XPath expressions, minimizing network requests, and utilizing efficient data structures. By employing these strategies, you can reduce execution time and enhance the scalability of your scraping process.
a. Optimizing XPath Expressions: XPath expressions are used to locate specific elements on a web page for data extraction. By crafting efficient and precise XPath expressions, you can minimize the time required to locate and extract the desired data. Avoid using overly complex or generic XPath expressions that may lead to unnecessary traversals and slow down the scraping process.
b. Minimizing Network Requests: Excessive network requests can impact performance, especially when scraping a large number of pages. Minimize the number of requests by employing techniques such as session management, caching, and request batching. Reuse existing connections and cookies to reduce overhead and optimize the retrieval of data from the website.
c. Efficient Data Structures: Choose appropriate data structures to store and manipulate the extracted data. Utilize data structures like lists, dictionaries, or pandas DataFrames efficiently to ensure fast and efficient data processing. Consider the specific requirements of your analysis and choose the most suitable data structures accordingly.
d. Implementing Throttling and Rate Limiting: Respect the website's guidelines and avoid overloading the server with excessive requests. Implement throttling and rate limiting mechanisms to control the frequency of your requests. Adhering to these limits ensures that the scraping process is well-behaved and maintains a good relationship with the target website.
By implementing these code optimization techniques, you can enhance the performance and scalability of your web scraping process, enabling efficient extraction of data from websites for further analysis and decision-making.
Robustness and Error Handling: To ensure the robustness of your web scraping scripts and handle errors effectively, it is important to incorporate error handling mechanisms and implement retry strategies. Additionally, setting up monitoring and alerting systems can help detect and respond to any issues that may arise during the scraping process. Consider the following tips:
a. Robust Error Handling: To handle common errors and exceptions during scraping, it is recommended to use try-except blocks. Capture specific errors and exceptions, log them, and implement appropriate error-handling logic. By gracefully recovering from failures, you can ensure that your scraping script continues execution without disruptions.
b. Retry Mechanisms: Transient errors or connection issues may occur during web scraping. Implement retry strategies to handle these situations effectively. Repeat failed requests after some delay or using exponential backoff for improving chances of any successful data scraping. By incorporating retry mechanisms, you can increase the resilience of your scraping script.
c. Alert and Monitoring: Set up a monitoring system to keep track of the scraping process and detect any anomalies or errors. Implement alerting mechanisms that notify you or your team in real-time when issues arise. This proactive approach allows for prompt troubleshooting and minimizes the impact of disruptions on the data extraction pipeline.
By following these tips, you can build robust web scraping scripts that can handle errors gracefully, recover from failures, and ensure the smooth functioning of your scraping process. Monitoring and alerting systems provide visibility into the scraping activities, enabling timely response to any issues that may occur.
Ethical and Legal Considerations: Ethical and legal considerations play a crucial role in web scraping. It is important to adhere to ethical guidelines and comply with the legal requirements to ensure responsible and lawful data extraction. Consider the following points:
a. Follow Website's Terms of Service: Review and understand the terms of service of the Amazon website or any other website you are scraping. Comply with their policies, guidelines, and restrictions. Respect any rate limits or data usage restrictions specified in the terms of service.
b. Crawl-Delay and Robots.txt: Check the website's robots.txt file to understand which parts of the website are open to scraping and any specific instructions or restrictions. Adhere to the rules given in robots.txt file, including respecting the crawl delay if mentioned. This helps to evade overloading servers and ensures responsible scraping.
c. Copyrights and Intellectual Property: Respect copyright laws and intellectual property rights when using the scraped data. Ensure that you have the necessary rights and permissions to use and analyze the data extracted. Avoid scraping sensitive or private information that may infringe upon privacy rights or violate legal regulations.
By implementing these strategies and considering ethical and legal aspects, you can optimize the web scraping process for scalability, performance, and compliance. This ensures that the data extraction for AmazInvest is conducted in a responsible and lawful manner, maintaining the integrity of the scraping process.
Code Time:
The comprehensive web scraping solution utilizes Python and Selenium's ChromeDriver to interact with the Amazon website. Here is an overview of the main steps involved:
Configuration: The code sets up the web driver and directs it to the Amazon website. Chrome options are configured to exclude unnecessary logging, and the Chrome driver is initialized using ChromeDriverManager.
Search and Navigation: The code performs a search for a specific category, such as "Laptops", by locating the search box element, entering the query, and clicking the search button. This navigates to the search results page.
Data Extraction: XPath expressions are used to locate and extract relevant information from the search results page. This includes product names, ratings, prices, and other pertinent data. Additionally, the code enters each product page to gather more specific information.
Pagination: The code checks for the presence of a next page to scrape data from multiple pages of search results. If a next page is available, it continues the extraction process by navigating to the next page and repeating the data extraction steps.
Data Storage: The extracted data is stored in variables, lists, or data structures for further processing and analysis. The code may use pandas to create a DataFrame from the extracted data and save it as an Excel file for easy storage and analysis.
Challenges and Considerations: The code addresses challenges such as website structure changes, anti-scraping measures, and legal and ethical considerations. It includes error handling mechanisms, scalability techniques like parallel processing or distributed computing, and adherence to website terms of service and legal guidelines.
Please note that the provided overview is a high-level summary, and the actual code implementation may include additional functionalities, error handling, and best practices to ensure efficient and reliable web scraping.
Conclusion
Web scraping plays a crucial role in the development of AmazInvest, the Amazon investment application. It enables the extraction and analysis of data from the Amazon website, providing investors with valuable information to evaluate investment opportunities effectively.
Throughout this guide, we have covered the web scraping process for the AmazInvest project, explaining the significance of each step and its relevance to building the application. By following this guide, you have acquired the knowledge and code snippets necessary to navigate to the Amazon website, perform searches for relevant products, extract the required data, and save it for further analysis. It is essential to emphasize the importance of adhering to website terms of service and legal guidelines during the web scraping process.
By implementing the techniques and best practices outlined in this guide, you are well-equipped to develop a robust and efficient web scraping solution for AmazInvest. Remember to continuously monitor and adapt to changes in website structure, handle potential challenges, and ensure the integrity, quality, and compliance of the extracted data.
Harnessing the power of web scraping, AmazInvest can provide investors with accurate and reliable insights, enabling them to make informed investment decisions and uncover valuable opportunities on the Amazon platform.
Still, if you want more information, contact Actowiz Solutions! You can also reach us for all your mobile app scraping, instant data scraper, web scraping service requirements.
 Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping
Core Scraping Services
Amazon Data Scraping #1 Walmart Data Scraping Shopify Store Scraping HOT TikTok Shop Scraping HOT Flipkart Data Scraping Top Global Platforms
Top Global Platforms
 Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW
Platforms by Region
🇺🇸 USA🇬🇧🇪🇺 UK/EU🇮🇳 India🇦🇪 ME🌏 SEA🌎 LATAM🇨🇳🇯🇵🇰🇷🇦🇺 AUAmazon Data Scraping #1 Walmart Data Scraping Target Data Scraping NEW Shopify Scraping HOT TikTok Shop Scraping HOT Costco Data Scraping NEW Best Buy Scraping NEW Home Depot Scraping NEW Etsy Data Scraping NEW Shein Data Scraping NEW DoorDash Scraping NEW Instacart Scraping NEWTesco Data Scraping NEW Sainsbury's Scraping NEW ASDA Data Scraping NEW Ocado Scraping NEW ASOS Data Scraping NEW Rightmove Scraping NEW Deliveroo Scraping NEW Zalando Scraping NEW Otto Scraping NEW Cdiscount Scraping NEW Carrefour Scraping NEW Allegro Scraping NEW Bol.com Scraping NEWFlipkart Data Scraping JioMart Data Scraping NEW BigBasket Scraping NEW Myntra Data Scraping NEW Nykaa Data Scraping NEW Blinkit Data Scraping Zepto Data Scraping Zomato Data Scraping Swiggy Data ScrapingNoon Data Scraping NEW Amazon.ae Scraping NEW Talabat Data Scraping NEW Careem Data Scraping NEW PropertyFinder Scraping NEW Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence
Pricing & Promotions
MAP Violations Brand Protection Counterfeit Detection Price Intelligence AI HOT Data Intelligence Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW
Brand & Intelligence
Share of Search Content Audit & PDP Reviews & Ratings Retail Media Buy Box Monitoring Social Commerce HOT Live Commerce NEW Agentic Commerce NEW Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW
Digital Shelf & Search
Assortment Planning Competitive Benchmarking Product Availability Seller Intelligence NEW Q-Commerce NEW AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW
AssortmentE-commerce Intelligence Hyperlocal Insights POI & Store Locator DTC Brand Analytics NEW For Retailers
For Retailers E-Commerce Dashboard
E-Commerce Dashboard
 Flipkart Insights (Live) #1
Flipkart Insights (Live) #1
 Grocery Intelligence
Grocery Intelligence
.svg) Grocery Price (U.S.)
Grocery Price (U.S.)
.svg) Quick Commerce (India) HOT
Quick Commerce (India) HOT
 Food & Restaurant
Food & Restaurant
 Fashion Intelligence
Fashion Intelligence
 Automotive
Automotive
 Travel & Hospitality
Travel & Hospitality
 Real Estate
Real Estate
 Food Delivery Intelligence NEW
Food Delivery Intelligence NEW
 OTT & Streaming NEW
OTT & Streaming NEW
 By Use Case
By Use Case
 Pricing Intelligence
Pricing Intelligence
 Digital Shelf Analytics
Digital Shelf Analytics
 MAP Monitoring HOT
MAP Monitoring HOT
 Cross-Border Price Parity NEW
Cross-Border Price Parity NEW
 Share of Search
Share of Search
 Review Sentiment
Review Sentiment
 Kitchen Market Gaps NEW
Kitchen Market Gaps NEW
 Dynamic Pricing / AI Repricing NEW
Dynamic Pricing / AI Repricing NEW
 Promotions & Deals Alerts NEW
Promotions & Deals Alerts NEW
 B2B / POI & Lead Data NEW
B2B / POI & Lead Data NEW
 By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia
By Region🇮🇳 India 🇺🇸 USA 🇦🇪 Middle East 🇬🇧 UK 🇦🇺 Australia 🌏 SE Asia 🇪🇺 Europe 🌎 LATAMIndia Flipkart Real-Time Insights
Flipkart Real-Time Insights
 Quick Commerce — Zepto · Blinkit
Quick Commerce — Zepto · Blinkit
 Pincode Price Tracker
USA
Pincode Price Tracker
USA Grocery Price Tracker (U.S.)
Grocery Price Tracker (U.S.)
 GCC Q-Commerce — Talabat · Noon NEW
UK
GCC Q-Commerce — Talabat · Noon NEW
UK Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia
Grocery Price — Tesco · Sainsbury's · Asda NEW
Australia Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation →
Grocery Price — Coles · Woolworths NEW
Want THIS view for your brand · your city · your category? Custom dashboard in 7 days. Free Consultation → Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW
Marketplace Scrapers
Amazon API TikTok Shop API HOT Uber Eats API Airbnb API Zepto / Blinkit API Instacart API NEW Talabat API NEW Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW
Data APIsWeb Extract API Reviews API SERP API Pricing Webhook NEW Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK
Universal APIsLive Crawler API Scheduler Realtime Alerts Webhook Delivery 🐍 Python SDK 💚 Node.js SDK Delivery & SDKs
Delivery & SDKs Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW
Knowledge Center
Digital Shelf Playbook MAP Compliance Guide Pricing Intel Guide Scraping Compliance TikTok Shop Guide NEW Cross-Border Guide NEW Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit
Guides & Playbooks
Sample Datasets HOT ROI Calculator NEW API Postman Collection Demo Dashboards Free API Playground NEW Press Kit Downloads & Tools
Trust Center About Us FAQs Careers
Downloads & Tools
Trust Center About Us FAQs Careers Trust & Company
Trust & Company Grocery & FMCG
Grocery & FMCG Finance & Legal
Finance & Legal Healthcare & Pharma
Healthcare & Pharma Media & Entertainment
Media & Entertainment Emerging Industries
Emerging Industries














































